Simulações baseadas em aprendizado por reforço mostram que o desejo humano de sempre querer mais pode acelerar o aprendizado
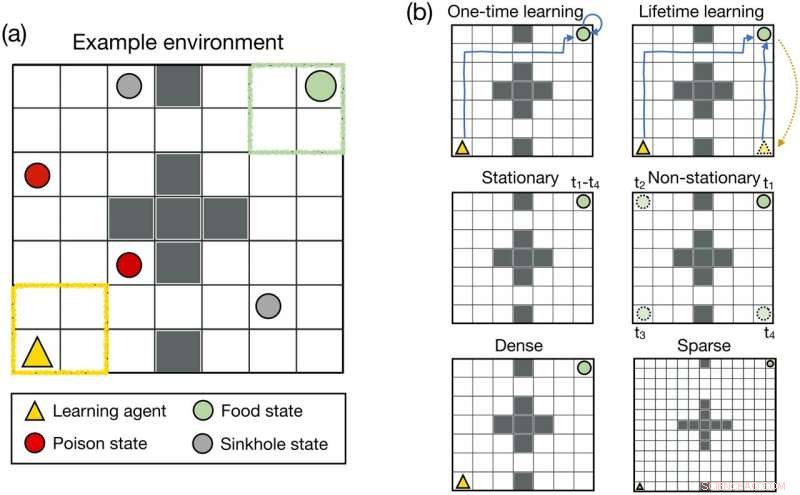
Projeto de ambiente. (a) O ambiente gridworld bidimensional usado no Experimento 1. (b) Para estudar as propriedades da recompensa ótima, fizemos várias modificações no ambiente gridworld. Linha superior:No ambiente de aprendizado único, o agente pode optar por permanecer no local do alimento constantemente após alcançá-lo. No ambiente de aprendizado vitalício, o agente era teletransportado para um local aleatório no gridworld assim que alcançava o estado alimentar. Linha do meio:No ambiente estacionário, o alimento permaneceu no mesmo local durante toda a vida do agente. No ambiente não estacionário, o alimento mudou de localização durante o tempo de vida do agente. Linha inferior:Usamos um gridworld de tamanho 7 × 7 para simular uma configuração de recompensa densa. Para simular uma configuração de recompensa esparsa, aumentamos o tamanho do gridworld para 13 × 13. Crédito:PLOS Computational Biology (2022). DOI:10.1371/journal.pcbi.1010316
Um trio de pesquisadores, dois da Universidade de Princeton, o outro do Instituto Max Planck de Cibernética Biológica, desenvolveu uma simulação baseada em aprendizado por reforço que mostra que o desejo humano de sempre querer mais pode ter evoluído como uma forma de acelerar o aprendizado. Em seu artigo publicado no
PLOS Computational Biology de acesso aberto , Rachit Dubey, Thomas Griffiths e Peter Dayan descrevem os fatores que entraram em suas simulações.
Pesquisadores que estudam o comportamento humano muitas vezes ficam intrigados com os desejos aparentemente contraditórios das pessoas. Muitas pessoas têm um desejo incessante por mais de certas coisas, mesmo sabendo que atender a esses desejos pode não resultar no resultado desejado. Muitas pessoas querem mais e mais dinheiro, por exemplo, com a ideia de que mais dinheiro facilitaria a vida, o que deveria torná-las mais felizes. Mas uma série de estudos mostrou que ganhar mais dinheiro raramente torna as pessoas mais felizes (com exceção daqueles que começam com um nível de renda muito baixo). Nesse novo esforço, os pesquisadores procuraram entender melhor por que as pessoas teriam evoluído dessa maneira. Para isso, eles construíram uma simulação para imitar a forma como os humanos respondem emocionalmente a estímulos, como alcançar objetivos. E para entender melhor por que as pessoas podem se sentir assim, eles adicionaram pontos de verificação que podem ser usados como um barômetro da felicidade.
A simulação foi baseada no aprendizado por reforço, no qual as pessoas (ou uma máquina) continuam fazendo coisas que oferecem uma recompensa positiva e deixam de fazer coisas que não oferecem recompensa ou uma recompensa negativa. Os pesquisadores também adicionaram reações emocionais simuladas aos conhecidos impactos negativos da habituação e comparação, em que as pessoas se tornam menos felizes ao longo do tempo à medida que se acostumam com algo novo e ficam menos felizes ao ver que outra pessoa tem mais de algo que desejam.
Ao executar a simulação, os pesquisadores descobriram que ela atingia os objetivos mais rapidamente quando a habituação e a comparação entravam em ação – uma sugestão de que essas reações emocionais também podem desempenhar um papel no aprendizado mais rápido em humanos. Eles também descobriram que a simulação ficou menos "feliz" quando confrontada com mais opções em relação a possíveis opções alcançáveis do que quando havia apenas algumas para escolher.
Os pesquisadores sugerem que a razão pela qual as pessoas são propensas a ficarem presas em um ciclo interminável de sempre querer mais é porque, no geral, isso ajuda os humanos a aprender mais rápido.
+ Explorar mais Felicidade:por que aprender, não recompensas, pode ser a chave
© 2022 Science X Network