Crédito CC0:domínio público
Em 3 de novembro, 2020 - e por muitos dias depois - milhões de pessoas ficaram de olho nos modelos de previsão das eleições presidenciais veiculados por vários veículos de notícias. Com apostas tão altas em jogo, cada tique de uma contagem e contração de um gráfico podem enviar ondas de choque de superinterpretação.
Um problema com as contagens brutas da eleição presidencial é que elas criam uma narrativa falsa de que os resultados finais ainda estão se desenvolvendo de forma drástica. Na realidade, na noite da eleição não há "recuperação por trás" ou "perda da liderança" porque os votos já foram lançados; o vencedor já ganhou - só não sabemos ainda. Mais do que impreciso, essas descrições fascinantes do processo de votação podem fazer os resultados parecerem excessivamente suspeitos ou surpreendentes.
"Modelos preditivos são usados para tomar decisões que podem ter consequências enormes para a vida das pessoas, "disse Emmanuel Candès, a Cadeira Barnum-Simons em Matemática e Estatística na Escola de Humanidades e Ciências da Universidade de Stanford. "É extremamente importante entender a incerteza sobre essas previsões, para que as pessoas não tomem decisões com base em crenças falsas. "
Essa incerteza era exatamente o que The Washington Post o cientista de dados Lenny Bronner teve como objetivo destacar em um novo modelo de previsão que ele começou a desenvolver para as eleições locais da Virgínia em 2019 e posteriormente refinado para as eleições presidenciais, com a ajuda de John Cherian, um atual Ph.D. estudante de estatística em Stanford que Bronner conhecia de seus estudos de graduação.
"O modelo realmente tratava de adicionar contexto aos resultados que estavam sendo mostrados, "disse Bronner." Não se tratava de prever a eleição. Tratava-se de dizer aos leitores que os resultados que eles estavam vendo não refletiam onde pensávamos que a eleição iria terminar. "
Este modelo é a primeira aplicação no mundo real de uma técnica estatística existente desenvolvida em Stanford por Candès, o ex-bolsista de pós-doutorado Yaniv Romano e o ex-aluno de graduação Evan Patterson. A técnica é aplicável a uma variedade de problemas e, como no modelo de predicação do Post, poderia ajudar a elevar a importância da incerteza honesta na previsão. Enquanto o Post continua a aperfeiçoar seu modelo para futuras eleições, Candès está aplicando a técnica subjacente em outro lugar, incluindo dados sobre COVID-19.
Evitando suposições
Para criar esta técnica estatística, Candès, Romano e Evan Patterson combinaram duas áreas de pesquisa - regressão quantílica e predição conformada - para criar o que Candès chamou de "o mais informativo, intervalo bem calibrado de valores previstos que sei como construir. "
Enquanto a maioria dos modelos de previsão tenta prever um único valor, frequentemente a média (média) de um conjunto de dados, a regressão quantílica estima uma gama de resultados plausíveis. Por exemplo, uma pessoa pode querer encontrar o quantil 90, que é o limite abaixo do qual se espera que o valor observado caia 90 por cento do tempo. Quando adicionado à regressão de quantis, a previsão conformada - desenvolvida pelo cientista da computação Vladimir Vovk - calibra os quantis estimados para que sejam válidos fora de uma amostra, como para dados até agora não vistos. Para o modelo eleitoral do Post, isso significava usar resultados de votação de áreas demograficamente semelhantes para ajudar a calibrar as previsões sobre votos que foram pendentes.
O que há de especial nessa técnica é que ela começa com suposições mínimas incorporadas às equações. Para trabalhar, Contudo, ele precisa começar com uma amostra representativa de dados. Isso é um problema para a noite da eleição porque as contagens de votos iniciais - geralmente de pequenas comunidades com mais votação pessoal - raramente refletem o resultado final.
Sem acesso a uma amostra representativa dos votos atuais, Bronner e Cherian tiveram que adicionar uma suposição. Eles calibraram seu modelo usando as contagens de votos das eleições presidenciais de 2016 para que, quando uma área relatasse 100 por cento de seus votos, o modelo do Post presumiria que quaisquer mudanças entre os votos de 2020 daquela área e seus votos de 2016 seriam igualmente refletidos em condados semelhantes. (O modelo então se ajustaria ainda mais - reduzindo a influência da suposição - conforme mais áreas relatassem 100 por cento de seus votos.) Para verificar a validade deste método, eles testaram o modelo com cada eleição presidencial, começando com 1992, e descobriu que suas previsões coincidiam de perto com os resultados do mundo real.
"O que é bom em usar a abordagem de Emmanuel para isso é que as barras de erro em torno de nossas previsões são muito mais realistas e podemos manter suposições mínimas, "disse Cherian.
Visualizando a incerteza
Em ação, a visualização do modelo ao vivo do Post foi meticulosamente projetada para exibir de forma proeminente essas barras de erro e a incerteza que elas representavam. O Post executou o modelo para prever a gama de resultados eleitorais prováveis em diferentes estados e tipos de condado; condados foram categorizados de acordo com seus dados demográficos. Em todo caso, cada indicado tinha sua própria barra horizontal preenchida com um sólido - azul para Joe Biden, vermelho para Donald Trump - para mostrar os votos conhecidos. Então, o resto da barra continha um gradiente que representava os resultados mais prováveis para os votos pendentes, de acordo com o modelo. A área mais escura do gradiente era o resultado mais provável.
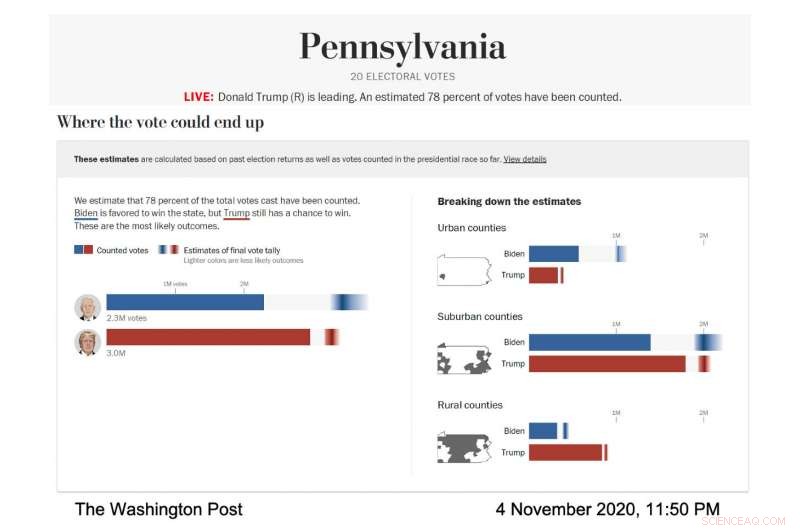
Captura de tela do modelo eleitoral do The Washington Post, mostrando a previsão de votação para a Pensilvânia em 4 de novembro, 2020. (Crédito da imagem:cortesia do The Washington Post)
"Conversamos com pesquisadores sobre a visualização da incerteza e aprendemos que se você der a alguém uma previsão média e, em seguida, dizer a eles quanta incerteza está envolvida, eles tendem a ignorar a incerteza, "disse Bronner." Então, fizemos uma visualização que é muito 'incerta'. Queríamos mostrar, esta é a incerteza e não vamos nem dizer qual é a nossa previsão média. "
Conforme a noite da eleição avançava, a parte mais escura do gradiente de Biden na visualização do voto total estava mais à direita da barra, o que significava que o modelo previu que ele acabaria com mais votos. Seu gradiente também era mais amplo e espalhado de forma assimétrica em direção ao lado mais votado da barra, o que significa que o modelo previu que havia muitos cenários, com chances decentes, onde ele ganharia mais votos do que o número mais provável.
"Na noite da eleição, notamos que as barras de erro eram muito curtas no lado esquerdo da barra de Biden e muito longas no lado direito, "disse Cherian." Isso aconteceu porque Biden tinha muitas vantagens para superar nossa projeção de forma substancial e não teve muitas desvantagens. "Essa previsão assimétrica foi uma consequência da abordagem de modelagem particular usada por Cherian e Bronner . Como as previsões do modelo foram calibradas usando resultados de condados demograficamente semelhantes que terminaram de relatar seus votos, ficou claro que Biden tinha uma boa chance de superar significativamente o voto democrata de 2016 em condados suburbanos, embora fosse extremamente improvável que ele fizesse pior.
Claro, à medida que a contagem dos votos se dirigia para o final, os gradientes diminuíram e as previsões incertas do Post pareciam cada vez mais certas - uma situação desesperadora para cientistas de dados preocupados em exagerar conclusões tão importantes.
"Eu estava particularmente preocupado que a corrida chegasse a um estado, e teríamos uma previsão em nossa página por dias que acabou não se concretizando, "disse Bronner.
E essa preocupação foi bem fundamentada porque o modelo previu forte e teimosamente uma vitória de Biden por vários dias, enquanto a contagem final da votação não vinha de um único estado, mas três:Wisconsin, Michigan e Pensilvânia.
"Ele acabou vencendo esses estados, so that ended up working well for the model, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, Afinal, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. Na verdade, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, Contudo, is that the conclusions suffer if there isn't enough data. Por exemplo, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, no entanto, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."