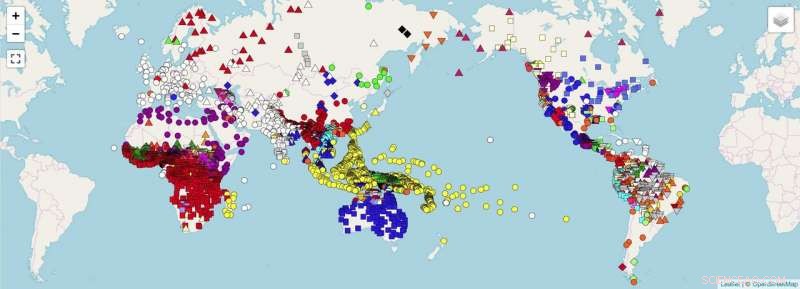
Um mapa-múndi mostrando pontos de dados, para o qual os pesquisadores planejam reunir dados unificados (por exemplo, dados que são diretamente comparáveis) usando as diretrizes fornecidas no documento. Crédito:OpenStreetMap. Forkel et al. 2018. Formatos de dados lingüísticos cruzados, avanço no compartilhamento e reutilização de dados em linguística comparativa. Dados Científicos .
Uma equipe internacional de pesquisadores, membros da Cross-Linguistic Data Formats Initiative (CLDF) liderada pelo Instituto Max Planck para a Ciência da História Humana, propôs novas diretrizes sobre formatos de dados multilíngues, a fim de facilitar o compartilhamento e as comparações de dados entre o número crescente de grandes bancos de dados linguísticos em todo o mundo. Este formato fornece um pacote de software, uma ontologia básica e exemplos de uso.
Há um número crescente de bancos de dados linguísticos em todo o mundo, levantando a possibilidade de uma vasta rede de estudos comparativos potenciais. Contudo, esses bancos de dados geralmente são criados independentemente uns dos outros, e geralmente têm um foco único e estreito. Isso significa que os formatos usados para codificar os dados costumam ser diferentes, criando dificuldades na comparação de dados entre bancos de dados.
A Cross-Linguistic Data Formats Initiative (CLDF) é um esforço para resolver esses problemas. Em um artigo publicado em Dados Científicos , o CLDF estabelece diretrizes propostas para um formato padronizado para bancos de dados linguísticos, e também fornece um pacote de software, uma ontologia básica e exemplos de uso das melhores práticas. O objetivo desse esforço é facilitar o compartilhamento e a reutilização de dados em linguística comparativa.
O CLDF fornece um modelo de dados subjacente às suas recomendações que pretende ser simples, ainda expressivo, e é baseado no modelo de dados desenvolvido anteriormente para o projeto Cross-Linguistic Data. Este modelo possui quatro entidades principais:(a) linguagens; (b) parâmetros; (c) valores; e (d) fontes. No modelo, cada valor está relacionado a um parâmetro e um idioma, e pode ser baseado em várias fontes. Além disso, existem referências para fontes, e as referências também podem ter contextos (que, por exemplo, para referências impressas seriam números de página).
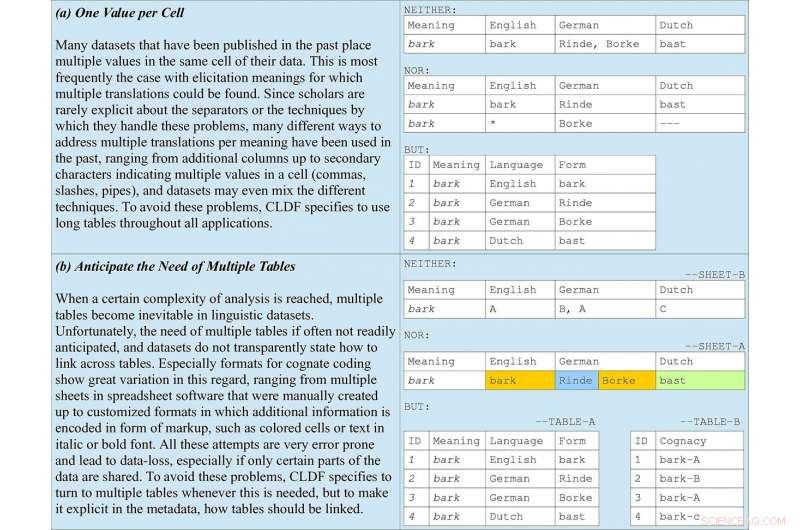
Regras básicas de codificação de dados incluídas nas diretrizes, tomando a codificação cognata em listas de palavras como exemplo. (a) ilustra por que tabelas longas devem ser favorecidas em todas as aplicações. (b) destaca a importância de antecipar tabelas múltiplas juntamente com metadados que indicam como eles devem ser vinculados. Crédito:Forkel et al. 2018. Formatos de dados lingüísticos cruzados, avanço no compartilhamento e reutilização de dados em linguística comparativa. Dados Científicos .
O modelo de dados CLDF é um formato de pacote no qual um conjunto de dados seria composto de um conjunto de arquivos de dados contendo tabelas, e um arquivo descritivo que define as relações entre as tabelas. Cada tipo de dado linguístico teria um módulo CLDF e componentes adicionais, quais seriam os aspectos dos dados no módulo que se repetem em vários tipos de dados. Os módulos CLDF também conteriam termos da ontologia CLDF. A ontologia é uma lista de vocabulário que representa objetos e propriedades com semântica bem conhecida em linguística comparada. Isso possibilita que os usuários façam referência a esses termos de maneira uniforme.
Um pacote de software para permitir validação e manipulação
As especificações CLDF usam formatos de arquivo comuns, como CSV, JSON e BibTeX — que são amplamente suportados, com o objetivo de que esses arquivos possam ser facilmente lidos e gravados em muitas plataformas. Ainda mais importante, o formato padronizado permitirá que pesquisadores sem habilidades de programação acessem e manipulem os dados com ferramentas preexistentes, para evitar restringir o pacote apenas a pesquisadores com habilidades de programação suficientes para criar suas próprias ferramentas. Para facilitar isso, o CLDF criou um repositório de "livro de receitas" para scripts a serem usados com as especificações do CLDF.
"Queremos trazer acesso a esses dados e a capacidade de compará-los com o maior número possível de pesquisadores, "diz a lista Johann-Mattis do Instituto Max Planck para a Ciência da História Humana. Robert Forkel, uma das forças motrizes por trás da iniciativa CLDF, também observa que o formato CLDF não se limita apenas aos dados linguísticos, mas também pode incorporar bancos de dados de dados culturais e geográficos, por exemplo. "O CLDF pode facilitar drasticamente o teste de questões relacionadas à interação entre linguística, cultural, e fatores ambientais na evolução linguística e cultural. "