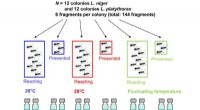
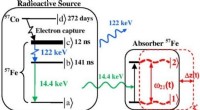
Acompanhar uma epidemia requer modelos informáticos – mas e se esses modelos estiverem errados?
Depender apenas de modelos informáticos para rastrear epidemias pode representar desafios e limitações significativos. Embora os modelos possam fornecer informações e previsões valiosas, eles são tão precisos quanto os dados e suposições sobre os quais são construídos. Aqui estão algumas razões principais pelas quais os modelos de computador nem sempre são confiáveis para o rastreamento de epidemias:
1.
Qualidade e disponibilidade de dados :A precisão dos modelos computacionais depende muito da qualidade e disponibilidade dos dados. Dados incompletos, imprecisos ou ausentes podem levar a previsões incorretas. A recolha de dados em tempo real durante uma epidemia pode ser difícil, especialmente em ambientes com recursos limitados, o que pode comprometer a precisão do modelo.
2.
Simplificação excessiva da realidade :Os modelos computacionais muitas vezes simplificam cenários complexos do mundo real para tornar os cálculos viáveis. Estas simplificações podem ignorar factores cruciais que influenciam a propagação de doenças, tais como comportamentos individuais, dinâmicas sociais e condições ambientais.
3.
Incerteza nas estimativas de parâmetros :Os modelos requerem estimativas para vários parâmetros, como taxa de transmissão, período de incubação e tempo de recuperação. Estas estimativas baseiam-se frequentemente em observações limitadas e podem estar sujeitas a alterações à medida que surgem novas informações. A incerteza nesses parâmetros pode se propagar pelo modelo e afetar sua precisão.
4.
Mudanças comportamentais :O comportamento humano pode impactar significativamente a transmissão de doenças. Por exemplo, mudanças nos padrões de viagem, medidas de distanciamento social e uso de máscaras podem influenciar o curso de uma epidemia. Capturar essas mudanças comportamentais com precisão em um modelo computacional pode ser um desafio, levando a possíveis discrepâncias entre as previsões do modelo e as observações do mundo real.
5.
Eventos Imprevisíveis :As epidemias podem ser influenciadas por eventos imprevisíveis, como desastres naturais, mudanças políticas ou intervenções de saúde pública. Esses eventos podem interromper o curso da doença e tornar inválidos os modelos que não os consideram.
6.
Dados históricos limitados para novos patógenos :No caso de novos patógenos, como uma nova cepa de vírus, pode haver dados históricos disponíveis limitados para treinar e validar modelos computacionais. Sem dados suficientes, os modelos podem produzir previsões não confiáveis.
7.
Complexidade do modelo versus interpretabilidade :Encontrar um equilíbrio entre a complexidade do modelo e a interpretabilidade é vital. Modelos complexos podem fornecer informações mais detalhadas, mas podem ser difíceis de compreender e comunicar aos decisores políticos e ao público. Modelos mais simples podem ser mais fáceis de interpretar, mas podem carecer dos detalhes e da precisão necessários para uma tomada de decisão eficaz.
8.
Validação e calibração do modelo :Validar e calibrar modelos computacionais usando dados do mundo real é crucial para garantir sua confiabilidade. No entanto, a validação e calibração contínuas podem ser um desafio, especialmente quando os dados são escassos ou quando a epidemia evolui rapidamente.
9.
Sobreajuste e generalização :Os modelos adaptados a um contexto ou conjunto de dados específico podem não generalizar bem para diferentes populações ou ambientes. O overfitting para dados específicos pode levar a previsões que não são aplicáveis a situações mais amplas.
Para aumentar a fiabilidade dos modelos informáticos para o acompanhamento de epidemias, é essencial utilizar múltiplos modelos, incorporar conhecimentos especializados, actualizar continuamente os dados, validar e calibrar modelos regularmente e considerar as limitações e incertezas associadas às previsões dos modelos. Uma combinação de modelização e observações do mundo real é crucial para uma vigilância e resposta eficazes às epidemias.