O aprendizado de máquina revela o papel da cultura na definição dos significados das palavras
 p Os pesquisadores usaram o aprendizado de máquina para criar o primeiro em grande escala, estudo baseado em dados para iluminar como a cultura afeta o significado das palavras. Crédito:Pintura da Torre de Babel, de Pieter Bruegel, o Velho, Museu Kunsthistorisches de Viena, Viena, Áustria
p Os pesquisadores usaram o aprendizado de máquina para criar o primeiro em grande escala, estudo baseado em dados para iluminar como a cultura afeta o significado das palavras. Crédito:Pintura da Torre de Babel, de Pieter Bruegel, o Velho, Museu Kunsthistorisches de Viena, Viena, Áustria
p O que queremos dizer com a palavra bela? Não depende apenas de quem você pergunta, mas em que idioma você pergunta a eles. De acordo com uma análise de aprendizado de máquina de dezenas de idiomas realizada na Universidade de Princeton, o significado das palavras não se refere necessariamente a um intrínseco, constante essencial. Em vez de, é significativamente moldado pela cultura, história e geografia. Essa descoberta foi verdadeira até mesmo para alguns conceitos que parecem ser universais, como emoções, características da paisagem e partes do corpo. p "Mesmo para palavras do dia a dia que você pensaria que significam a mesma coisa para todos, existe toda essa variabilidade lá fora, "disse William Thompson, um pesquisador de pós-doutorado em ciência da computação na Universidade de Princeton, e principal autor das descobertas, publicado em
Nature Human Behavior 10 de agosto. "Fornecemos a primeira evidência baseada em dados de que a maneira como interpretamos o mundo por meio das palavras é parte de nossa herança cultural."
p A linguagem é o prisma através do qual conceituamos e entendemos o mundo, e linguistas e antropólogos há muito procuram desvendar as forças complexas que moldam esses sistemas de comunicação críticos. Mas os estudos que tentam abordar essas questões podem ser difíceis de conduzir e demorados, frequentemente envolvendo longo, entrevistas cuidadosas com falantes bilíngues que avaliam a qualidade das traduções. "Pode levar anos e anos para documentar um par específico de idiomas e as diferenças entre eles, "Thompson disse." Mas recentemente surgiram modelos de aprendizado de máquina que nos permitem fazer essas perguntas com um novo nível de precisão. "
p Em seu novo jornal, Thompson e seus colegas Seán Roberts, da Universidade de Bristol, REINO UNIDO., e Gary Lupyan da Universidade de Wisconsin, Madison, aproveitou o poder desses modelos para analisar mais de 1, 000 palavras em 41 idiomas.
p Em vez de tentar definir as palavras, o método em grande escala usa o conceito de "associações semânticas, "ou simplesmente palavras que têm uma relação significativa entre si, que os linguistas consideram uma das melhores maneiras de definir uma palavra e compará-la com outra. Associados semânticos de "lindo, " por exemplo, incluem "colorido, " "amar, "" precioso "e" delicado ".
p Os pesquisadores construíram um algoritmo que examinou redes neurais treinadas em várias linguagens para comparar milhões de associações semânticas. O algoritmo traduziu os associados semânticos de uma palavra específica para outro idioma, e então repetiu o processo ao contrário. Por exemplo, o algoritmo traduziu os associados semânticos de "beautiful" para o francês e, em seguida, traduziu os associados semânticos de beau para o inglês. A pontuação de similaridade final do algoritmo para o significado de uma palavra veio da quantificação da proximidade da semântica alinhada em ambas as direções da tradução.
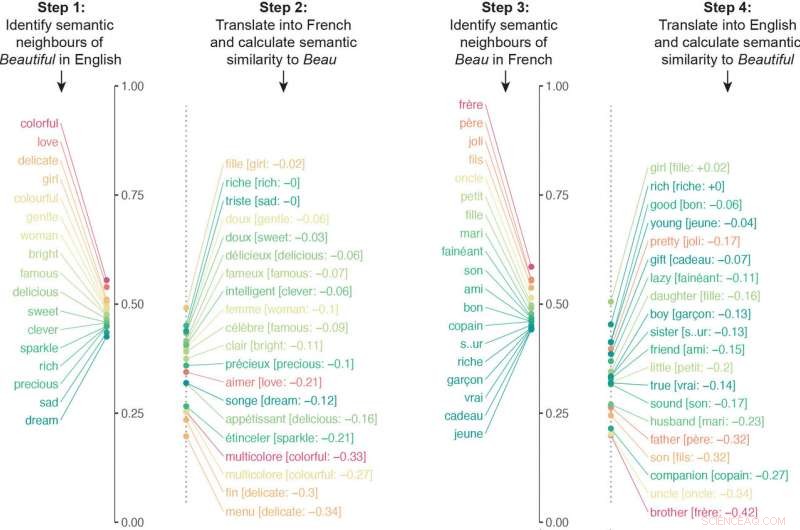 p O algoritmo traduziu os associados semânticos de uma palavra específica para outro idioma, e então repetiu o processo ao contrário. Neste exemplo, os vizinhos semânticos de "beautiful" foram traduzidos para o francês e, em seguida, os vizinhos semânticos de "beau" foram traduzidos para o inglês. As respectivas listas eram substancialmente diferentes por causa de associações culturais diferentes. Imagem cortesia dos pesquisadores. Crédito:Princeton University
p O algoritmo traduziu os associados semânticos de uma palavra específica para outro idioma, e então repetiu o processo ao contrário. Neste exemplo, os vizinhos semânticos de "beautiful" foram traduzidos para o francês e, em seguida, os vizinhos semânticos de "beau" foram traduzidos para o inglês. As respectivas listas eram substancialmente diferentes por causa de associações culturais diferentes. Imagem cortesia dos pesquisadores. Crédito:Princeton University
p "Uma maneira de ver o que fizemos é uma maneira baseada em dados de quantificar quais palavras são mais traduzíveis, "Disse Thompson.
p Os resultados revelaram que existem algumas palavras quase universalmente traduzíveis, principalmente aqueles que se referem a números, profissões, quantidades, datas do calendário e parentesco. Muitos outros tipos de palavras, Contudo, incluindo aqueles que se referem a animais, comida e emoções, eram muito menos combinados em significado.
p Em uma etapa final, os pesquisadores aplicaram outro algoritmo que comparou o quão semelhantes são as culturas que produziram as duas línguas, com base em um conjunto de dados antropológicos comparando coisas como práticas de casamento, sistemas jurídicos e organização política dos falantes de uma determinada língua.
p Os pesquisadores descobriram que seu algoritmo pode prever corretamente a facilidade com que duas línguas podem ser traduzidas com base na semelhança entre as duas culturas que as falam. Isso mostra que a variabilidade no significado das palavras não é apenas aleatória. A cultura desempenha um papel importante na formação de linguagens, uma hipótese que a teoria há muito previa, mas os pesquisadores careciam de dados quantitativos para apoiar.
p "Este é um artigo extremamente bom que fornece uma quantificação baseada em princípios para questões que têm sido centrais para o estudo da semântica lexical, "disse Damián Blasi, um cientista da linguagem na Universidade de Harvard, que não estava envolvido na nova pesquisa. Embora o artigo não forneça uma resposta definitiva para todas as forças que moldam as diferenças no significado das palavras, os métodos que os autores estabeleceram são sólidos, Blasi disse, e o uso de múltiplos, diversas fontes de dados "é uma mudança positiva em um campo que tem sistematicamente desconsiderado o papel da cultura em favor dos universais mentais ou cognitivos".
p Thompson concordou que ele e as descobertas de seus colegas enfatizam o valor de "curar conjuntos improváveis de dados que normalmente não são vistos nas mesmas circunstâncias". Os algoritmos de aprendizado de máquina que ele e seus colegas usaram foram originalmente treinados por cientistas da computação, enquanto os conjuntos de dados que alimentaram os modelos para analisar foram criados por antropólogos do século 20, bem como estudos linguísticos e psicológicos mais recentes. Como disse Thompson, "Por trás desses novos métodos sofisticados, há toda uma história de pessoas em vários campos coletando dados que estamos reunindo e analisando de uma forma totalmente nova. "