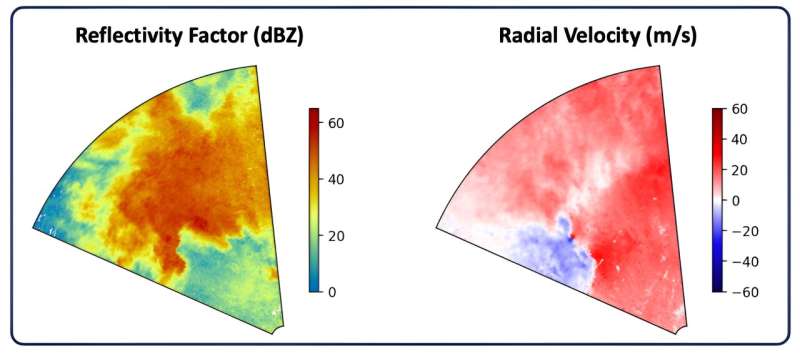
 Cada amostra no conjunto de dados TorNet inclui seis tipos de imagens de radar, retratando diferentes produtos de dados de radar. As imagens mostradas aqui são dois desses produtos, incluindo fator de refletividade e velocidade radial de um exemplo de tornado no conjunto de dados. Crédito:Instituto de Tecnologia de Massachusetts
Cada amostra no conjunto de dados TorNet inclui seis tipos de imagens de radar, retratando diferentes produtos de dados de radar. As imagens mostradas aqui são dois desses produtos, incluindo fator de refletividade e velocidade radial de um exemplo de tornado no conjunto de dados. Crédito:Instituto de Tecnologia de Massachusetts O retorno da primavera no Hemisfério Norte dá início à temporada de tornados. O funil sinuoso de poeira e detritos de um tornado parece uma visão inconfundível. Mas essa visão pode ser obscurecida pelo radar, a ferramenta dos meteorologistas. É difícil saber exatamente quando um tornado se formou, ou mesmo por quê.
Um novo conjunto de dados poderia conter respostas. Ele contém retornos de radar de milhares de tornados que atingiram os Estados Unidos nos últimos 10 anos. As tempestades que geraram tornados são flanqueadas por outras tempestades severas, algumas com condições quase idênticas, que nunca aconteceram. Os pesquisadores do Laboratório Lincoln do MIT que fizeram a curadoria do conjunto de dados, chamado TorNet, agora o lançaram em código aberto. Eles esperam permitir avanços na detecção de um dos fenômenos mais misteriosos e violentos da natureza.
"Muito progresso é impulsionado por conjuntos de dados de referência facilmente disponíveis. Esperamos que o TorNet estabeleça uma base para algoritmos de aprendizado de máquina para detectar e prever tornados", diz Mark Veillette, co-investigador principal do projeto com James Kurdzo. Ambos os pesquisadores trabalham no Grupo de Sistemas de Controle de Tráfego Aéreo.
Junto com o conjunto de dados, a equipe está lançando modelos treinados nele. Os modelos mostram-se promissores na capacidade do aprendizado de máquina de detectar tornados. Aproveitar este trabalho poderá abrir novas fronteiras para os meteorologistas, ajudando-os a fornecer avisos mais precisos que poderão salvar vidas.
Incerteza turbulenta
Cerca de 1.200 tornados ocorrem nos Estados Unidos todos os anos, causando prejuízos econômicos de milhões a bilhões de dólares e ceifando, em média, 71 vidas. No ano passado, um tornado de duração incomum matou 17 pessoas e feriu pelo menos 165 outras ao longo de um caminho de 95 quilômetros no Mississippi.
No entanto, os tornados são notoriamente difíceis de prever porque os cientistas não têm uma ideia clara da razão pela qual se formam. “Podemos ver duas tempestades que parecem idênticas, e uma produzirá um tornado e a outra não. Não entendemos isso completamente”, diz Kurdzo.
Os ingredientes básicos de um tornado são tempestades com instabilidade causada pelo ar quente que sobe rapidamente e pelo cisalhamento do vento que causa rotação. O radar meteorológico é a principal ferramenta usada para monitorar essas condições. Mas os tornados ficam muito baixos para serem detectados, mesmo quando moderadamente próximos do radar. À medida que o feixe do radar com um determinado ângulo de inclinação se afasta da antena, ele fica mais alto acima do solo, vendo principalmente os reflexos da chuva e do granizo carregados no "mesociclone", a corrente ascendente ampla e rotativa da tempestade. Um mesociclone nem sempre produz um tornado.
Com esta visão limitada, os meteorologistas devem decidir se devem ou não emitir um alerta de tornado. Freqüentemente, eles erram por excesso de cautela. Como resultado, a taxa de alarmes falsos para alertas de tornado é superior a 70%.
“Isso pode levar à síndrome do menino que chorou o lobo”, diz Kurdzo.
Nos últimos anos, os pesquisadores recorreram ao aprendizado de máquina para detectar e prever melhor os tornados. No entanto, os conjuntos de dados e modelos brutos nem sempre foram acessíveis à comunidade em geral, sufocando o progresso. A TorNet está preenchendo essa lacuna.
O conjunto de dados contém mais de 200 mil imagens de radar, 13.587 das quais retratam tornados. O restante das imagens não são tornados, tiradas de tempestades em uma de duas categorias:tempestades severas selecionadas aleatoriamente ou tempestades de alarme falso (aquelas que levaram um meteorologista a emitir um alerta, mas que não produziram um tornado).
Cada amostra de tempestade ou tornado compreende dois conjuntos de seis imagens de radar. Os dois conjuntos correspondem a diferentes ângulos de varredura do radar. As seis imagens retratam diferentes produtos de dados de radar, como refletividade (mostrando a intensidade da precipitação) ou velocidade radial (indicando se os ventos estão se aproximando ou se afastando do radar).
Um desafio na curadoria do conjunto de dados foi primeiro encontrar tornados. Dentro do corpus de dados do radar meteorológico, os tornados são eventos extremamente raros. A equipe então teve que equilibrar essas amostras de tornado com amostras difíceis de não tornado. Se o conjunto de dados fosse muito fácil, por exemplo, comparando tornados com tempestades de neve, um algoritmo treinado nos dados provavelmente classificaria excessivamente as tempestades como tornados.
“O que é bonito em um verdadeiro conjunto de dados de benchmark é que todos trabalhamos com os mesmos dados, com o mesmo nível de dificuldade, e podemos comparar resultados”, diz Veillette. “Isso também torna a meteorologia mais acessível aos cientistas de dados e vice-versa. Torna-se mais fácil para essas duas partes trabalharem em um problema comum.”
Ambos os pesquisadores representam o progresso que pode advir da colaboração cruzada. Veillette é um matemático e desenvolvedor de algoritmos que há muito é fascinado por tornados. Kurdzo é meteorologista por formação e especialista em processamento de sinais. Na pós-graduação, ele perseguiu tornados com radares móveis personalizados, coletando dados para analisar de novas maneiras.
“Esse conjunto de dados também significa que um estudante de pós-graduação não precisa gastar um ou dois anos construindo um conjunto de dados. Eles podem ir direto para a pesquisa”, diz Kurdzo.
Buscando respostas com aprendizado profundo
Usando o conjunto de dados, os pesquisadores desenvolveram modelos básicos de inteligência artificial (IA). Eles estavam particularmente ansiosos para aplicar o aprendizado profundo, uma forma de aprendizado de máquina que se destaca no processamento de dados visuais. Por si só, o aprendizado profundo pode extrair recursos (observações-chave que um algoritmo usa para tomar uma decisão) de imagens em um conjunto de dados. Outras abordagens de aprendizado de máquina exigem que os humanos primeiro rotulem os recursos manualmente.
“Queríamos ver se o aprendizado profundo poderia redescobrir o que as pessoas normalmente procuram em tornados e até mesmo identificar coisas novas que normalmente não são pesquisadas pelos meteorologistas”, diz Veillette.
Os resultados são promissores. Seu modelo de aprendizado profundo teve desempenho semelhante ou melhor que todos os algoritmos de detecção de tornado conhecidos na literatura. O algoritmo treinado classificou corretamente 50% dos tornados EF-1 mais fracos e mais de 85% dos tornados classificados como EF-2 ou superior, que constituem as ocorrências mais devastadoras e dispendiosas dessas tempestades.
Eles também avaliaram dois outros tipos de modelos de aprendizado de máquina e um modelo tradicional para comparação. O código-fonte e os parâmetros de todos esses modelos estão disponíveis gratuitamente. Os modelos e o conjunto de dados também são descritos em um artigo submetido a uma revista da American Meteorological Society (AMS). Veillette apresentou este trabalho na Reunião Anual da AMS em janeiro.
“A maior razão para divulgar nossos modelos é para que a comunidade os aprimore e faça outras coisas excelentes”, diz Kurdzo. “A melhor solução poderia ser um modelo de aprendizagem profunda, ou alguém pode achar que um modelo de aprendizagem não profunda é realmente melhor.”
O TorNet também pode ser útil na comunidade meteorológica para outros usos, como para a realização de estudos de caso em grande escala sobre tempestades. Também poderia ser aumentado com outras fontes de dados, como imagens de satélite ou mapas de relâmpagos. A fusão de vários tipos de dados pode melhorar a precisão dos modelos de aprendizado de máquina.
Dando passos em direção às operações
Além de detectar tornados, Kurdzo espera que os modelos possam ajudar a desvendar a ciência que explica por que eles se formam.
"Como cientistas, vemos todos esses precursores de tornados - um aumento na rotação de baixo nível, um eco de gancho nos dados de refletividade, pé de fase diferencial específica (KDP) e arcos de refletividade diferencial (ZDR). Mas como todos eles andam juntos? E existem manifestações físicas que não conhecemos?" ele pergunta.
Descobrir essas respostas pode ser possível com IA explicável. IA explicável refere-se a métodos que permitem a um modelo fornecer o seu raciocínio, num formato compreensível para os humanos, sobre o motivo pelo qual tomou uma determinada decisão. Neste caso, estas explicações podem revelar processos físicos que acontecem antes dos tornados. Este conhecimento poderia ajudar a treinar previsores e modelos para reconhecer os sinais mais cedo.
“Nenhuma destas tecnologias pretende substituir um previsor. Mas talvez algum dia possa guiar os olhos dos meteorologistas em situações complexas e dar um aviso visual a uma área com previsão de atividade de tornado”, diz Kurdzo.
Essa assistência poderá ser especialmente útil à medida que a tecnologia de radar for melhorando e as redes futuras se tornarem potencialmente mais densas. Espera-se que as taxas de atualização de dados em uma rede de radar de próxima geração aumentem de cada cinco minutos para aproximadamente um minuto, talvez mais rápido do que os meteorologistas conseguem interpretar as novas informações. Como o aprendizado profundo pode processar grandes quantidades de dados rapidamente, ele pode ser adequado para monitorar retornos de radar em tempo real, junto com humanos. Tornados podem se formar e desaparecer em minutos.
Mas o caminho para um algoritmo operacional é um longo caminho, especialmente em situações críticas de segurança, diz Veillette. "Acho que a comunidade de analistas ainda é, compreensivelmente, cética em relação ao aprendizado de máquina. Uma forma de estabelecer confiança e transparência é ter conjuntos de dados de referência públicos como este. É um primeiro passo."
Os próximos passos, espera a equipe, serão dados por pesquisadores de todo o mundo, inspirados pelo conjunto de dados e motivados para construir seus próprios algoritmos. Esses algoritmos, por sua vez, irão para bancos de teste, onde serão eventualmente mostrados aos previsores, para iniciar um processo de transição para operações.
No final, o caminho poderia voltar à confiança.
“Podemos nunca receber mais do que um alerta de tornado de 10 a 15 minutos usando essas ferramentas. Mas se pudéssemos reduzir a taxa de alarmes falsos, poderíamos começar a avançar na percepção do público”, diz Kurdzo. “As pessoas vão usar esses avisos para tomar as medidas necessárias para salvar suas vidas”.