Pesquisadores propõem um modelo novo e mais eficaz para reconhecimento automático de fala
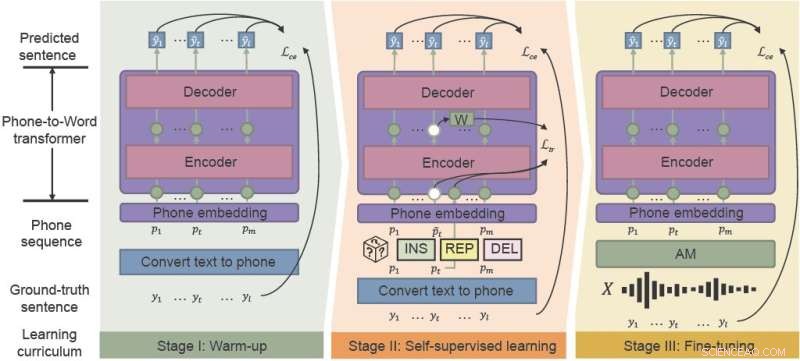
A estrutura de pré-treinamento fonético-semântico (PSP) usa o aprendizado de "currículo com reconhecimento de ruído" para melhorar efetivamente o desempenho do ASR em ambientes ruidosos. integrando aquecimento, aprendizado auto-supervisionado e ajuste fino. Crédito:Pesquisa de Inteligência Artificial CAAI , Imprensa da Universidade de Tsinghua
Assistentes de voz populares como Siri e Amazon Alexa introduziram o reconhecimento automático de fala (ASR) para o público em geral. Apesar de décadas de fabricação, os modelos ASR lutam com consistência e confiabilidade, especialmente em ambientes ruidosos. Pesquisadores chineses desenvolveram uma estrutura que melhora efetivamente o desempenho do ASR para o caos dos ambientes acústicos cotidianos.
Pesquisadores da Universidade de Ciência e Tecnologia de Hong Kong e do WeBank propuseram uma nova estrutura – pré-treinamento fonético-semântico (PSP) e demonstraram a robustez de seu novo modelo contra conjuntos de dados sintéticos de fala altamente ruidosos.
O estudo foi publicado na
CAAI Artificial Intelligence Research em 28 de agosto.
"A robustez é um desafio de longa data para a ASR", disse Xueyang Wu, do Departamento de Ciência e Engenharia da Computação da Universidade de Ciência e Tecnologia de Hong Kong. "Queremos aumentar a robustez do sistema ASR chinês com baixo custo."
O ASR usa aprendizado de máquina e outras técnicas de inteligência artificial para traduzir automaticamente a fala em texto para usos como sistemas ativados por voz e software de transcrição. Mas os novos aplicativos voltados para o consumidor exigem cada vez mais que o reconhecimento de voz funcione melhor – lide com mais idiomas e sotaques e tenha um desempenho mais confiável em situações da vida real, como videoconferência e entrevistas ao vivo.
Tradicionalmente, treinar os modelos acústicos e de linguagem que compõem o ASR requer grandes quantidades de dados específicos de ruído, o que pode ser proibitivo em termos de tempo e custo.
O modelo acústico (AM) transforma as palavras em "telefones", que são sequências de sons básicos. O modelo de linguagem (LM) decodifica telefones em frases de linguagem natural, geralmente com um processo de duas etapas:um LM rápido, mas relativamente fraco, gera um conjunto de frases candidatas e um LM poderoso, mas computacionalmente caro, seleciona a melhor frase dos candidatos.
“Os modelos tradicionais de aprendizado não são robustos contra saídas de modelos acústicos ruidosos, especialmente para palavras polifônicas chinesas com pronúncia idêntica”, disse Wu. "Se a primeira passagem da decodificação do modelo de aprendizagem estiver incorreta, é extremamente difícil para a segunda passagem compensá-la."
O framework PSP recentemente proposto facilita a recuperação de palavras classificadas incorretamente. Ao pré-treinar um modelo que traduz as saídas AM diretamente para sentença junto com as informações de contexto completas, os pesquisadores podem ajudar o LM a se recuperar eficientemente das saídas ruidosas do AM.
A estrutura do PSP permite que o modelo seja aprimorado por meio de um regime de pré-treinamento chamado currículo sensível ao ruído, que introduz gradualmente novas habilidades, começando com facilidade e avançando gradualmente para tarefas mais complexas.
"A parte mais crucial do nosso método proposto, o Noise-aware Curriculum Learning, simula o mecanismo de como os seres humanos reconhecem uma frase de uma fala barulhenta", disse Wu.
O aquecimento é o primeiro estágio, em que os pesquisadores pré-treinam um transdutor de telefone para palavra em uma sequência de telefone limpa, que é traduzida apenas de dados de texto não rotulados – para reduzir o tempo de anotação. Esta etapa "aquece" o modelo, inicializando os parâmetros básicos para mapear sequências telefônicas para palavras.
No segundo estágio, aprendizado autossupervisionado, o transdutor aprende a partir de dados mais complexos gerados por técnicas e funções de treinamento autossupervisionado. Finalmente, o transdutor telefone-palavra resultante é ajustado com dados de fala do mundo real.
Os pesquisadores demonstraram experimentalmente a eficácia de sua estrutura em dois conjuntos de dados reais coletados de cenários industriais e ruído sintético. Os resultados mostraram que a estrutura PSP melhora efetivamente o pipeline ASR tradicional, reduzindo as taxas de erro relativo de caracteres em 28,63% para o primeiro conjunto de dados e 26,38% para o segundo.
Nas próximas etapas, os pesquisadores investigarão métodos de pré-treinamento de PSP mais eficazes com conjuntos de dados não pareados maiores, buscando maximizar a eficácia do pré-treinamento para LM robusto ao ruído.
+ Explorar mais Como usar o aprendizado multitarefa para tradução de fala de baixa latência