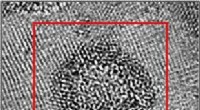
ObjectNet, um conjunto de dados de fotos criado por pesquisadores do MIT e IBM, mostra objetos de ângulos estranhos, em várias orientações, e contra fundos variados para melhor representar a complexidade dos objetos 3D. Os pesquisadores esperam que o conjunto de dados leve a novas técnicas de visão computacional com melhor desempenho na vida real. Crédito:Massachusetts Institute of Technology
Os modelos de visão computacional aprenderam a identificar objetos em fotos com tanta precisão que alguns podem superar os humanos em alguns conjuntos de dados. Mas quando esses mesmos detectores de objetos são liberados no mundo real, seu desempenho cai visivelmente, criando preocupações de confiabilidade para carros autônomos e outros sistemas críticos de segurança que usam visão de máquina.
Em um esforço para fechar essa lacuna de desempenho, uma equipe de pesquisadores do MIT e da IBM se propôs a criar um tipo muito diferente de conjunto de dados de reconhecimento de objetos. Chama-se ObjectNet, uma peça na ImageNet, o banco de dados crowdsourced de fotos responsável por lançar grande parte do boom moderno em inteligência artificial.
Ao contrário do ImageNet, que apresenta fotos tiradas do Flickr e outros sites de mídia social, ObjectNet apresenta fotos tiradas por freelancers pagos. Os objetos são mostrados inclinados de lado, filmado em ângulos estranhos, e exibidos em salas desordenadas. Quando os principais modelos de detecção de objetos foram testados na ObjectNet, suas taxas de precisão caíram de 97% na ImageNet para apenas 50-55%.
"Criamos este conjunto de dados para dizer às pessoas que o problema de reconhecimento de objetos continua sendo um problema difícil, "diz Boris Katz, um cientista pesquisador do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) e do Centro de Cérebros, Minds and Machines (CBMM). "Precisamos de melhor, algoritmos mais inteligentes. "Katz e seus colegas apresentarão a ObjectNet e seus resultados na Conferência sobre Sistemas de Processamento de Informação Neural (NeurIPS).
Aprendizagem profunda, a técnica que conduz grande parte do progresso recente em IA, usa camadas de "neurônios" artificiais para encontrar padrões em grandes quantidades de dados brutos. Aprende a escolher, dizer, a cadeira em uma foto após o treinamento em centenas a milhares de exemplos. Mas mesmo conjuntos de dados com milhões de imagens não podem mostrar cada objeto em todas as suas orientações e configurações possíveis, criando problemas quando os modelos encontram esses objetos na vida real.
O ObjectNet é diferente dos conjuntos de dados de imagens convencionais de outra maneira importante:ele não contém imagens de treinamento. A maioria dos conjuntos de dados é dividida em dados para treinar os modelos e testar seu desempenho. Mas o conjunto de treinamento muitas vezes compartilha semelhanças sutis com o conjunto de teste, na verdade, dando aos modelos uma prévia do teste.
À primeira vista, ImageNet, em 14 milhões de imagens, parece enorme. Mas quando seu conjunto de treinamento é excluído, é comparável em tamanho ao ObjectNet, aos 50, 000 fotos.
"Se quisermos saber o desempenho dos algoritmos no mundo real, devemos testá-los em imagens imparciais e que eles nunca viram antes, "diz o co-autor do estudo Andrei Barbu, um cientista pesquisador no CSAIL e CBMM.
Um conjunto de dados que tenta capturar a complexidade de objetos do mundo real
Poucas pessoas pensariam em compartilhar as fotos da ObjectNet com seus amigos, e esse é o ponto. Os pesquisadores contrataram freelancers da Amazon Mechanical Turk para tirar fotos de centenas de objetos domésticos dispostos aleatoriamente. Os funcionários receberam atribuições de fotos em um aplicativo, com instruções animadas dizendo-lhes como orientar o objeto atribuído, de que ângulo atirar, e se deve colocar o objeto na cozinha, banheiro, quarto, ou sala de estar.
Eles queriam eliminar três preconceitos comuns:objetos mostrados de frente, em posições icônicas, e em ambientes altamente correlacionados - por exemplo, pratos empilhados na cozinha.
Demorou três anos para conceber o conjunto de dados e projetar um aplicativo que padronizasse o processo de coleta de dados. "Descobrir como coletar dados de uma forma que controle vários vieses foi incrivelmente complicado, "diz o co-autor do estudo David Mayo, um aluno de pós-graduação no Departamento de Engenharia Elétrica e Ciência da Computação do MIT. "Também tivemos que realizar experimentos para garantir que nossas instruções fossem claras e que os trabalhadores soubessem exatamente o que lhes era pedido."
Demorou mais um ano para reunir os dados reais, e no final, metade de todas as fotos enviadas por freelancers tiveram que ser descartadas por não atenderem às especificações dos pesquisadores. Na tentativa de ser útil, alguns trabalhadores adicionaram rótulos aos seus objetos, encenou-os em fundos brancos, ou tentaram melhorar a estética das fotos que foram designadas para tirar.
Muitas das fotos foram tiradas fora dos Estados Unidos, e assim, alguns objetos podem parecer estranhos. Laranjas maduras são verdes, bananas vêm em tamanhos diferentes, e as roupas aparecem em uma variedade de formas e texturas.
Object Net vs. ImageNet:como os principais modelos de reconhecimento de objetos se comparam
Quando os pesquisadores testaram modelos de visão computacional de última geração na ObjectNet, eles encontraram uma queda de desempenho de 40-45 pontos percentuais no ImageNet. Os resultados mostram que os detectores de objetos ainda lutam para entender que os objetos são tridimensionais e podem ser girados e movidos para novos contextos, dizem os pesquisadores. "Essas noções não são construídas na arquitetura dos detectores de objetos modernos, "diz o co-autor do estudo Dan Gutfreund, pesquisador da IBM.
Mostrar que ObjectNet é difícil precisamente por causa de como os objetos são visualizados e posicionados, os pesquisadores permitiram que os modelos treinassem em metade dos dados ObjectNet antes de testá-los na metade restante. O treinamento e o teste no mesmo conjunto de dados geralmente melhoram o desempenho, mas aqui os modelos melhoraram apenas um pouco, sugerindo que os detectores de objetos ainda precisam compreender totalmente como os objetos existem no mundo real.
Os modelos de visão computacional têm melhorado progressivamente desde 2012, quando um detector de objetos chamado AlexNet esmagou a competição no concurso anual ImageNet. Conforme os conjuntos de dados ficaram maiores, o desempenho também melhorou.
Mas projetar versões maiores do ObjectNet, com seus ângulos de visão e orientações adicionais, não levará necessariamente a melhores resultados, os pesquisadores avisam. O objetivo da ObjectNet é motivar os pesquisadores a criar a próxima onda de técnicas revolucionárias, muito parecido com o lançamento inicial do desafio ImageNet.
"As pessoas alimentam esses detectores com grandes quantidades de dados, mas há retornos decrescentes, "diz Katz." Você não pode ver um objeto de todos os ângulos e em todos os contextos. Nossa esperança é que este novo conjunto de dados resulte em uma visão computacional robusta, sem falhas surpreendentes no mundo real. "
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.