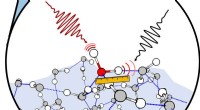
Crédito:Nvidia
O objetivo:transformar imagens 2-D em modelos 3-D usando uma arquitetura especial de codificador-decodificador. Os atores:Nvidia. O elogio:uma utilização inteligente do aprendizado de máquina com aplicativos benéficos do mundo real.
Paul Lilly em Hardware Quente estava entre os observadores de tecnologia que notaram que a maneira como passaram do 2-D para o 3-D era novidade. Não é nenhuma grande surpresa quando o caminho é inverso - 3-D para 2-D - mas "criar um modelo 3-D sem alimentar um sistema com dados 3-D é muito mais desafiador".
Lilly citou Jun Gao, um dos membros da equipe de pesquisa que trabalhou na abordagem de renderização. "Esta é essencialmente a primeira vez que você pode pegar qualquer imagem 2-D e prever propriedades 3-D relevantes."
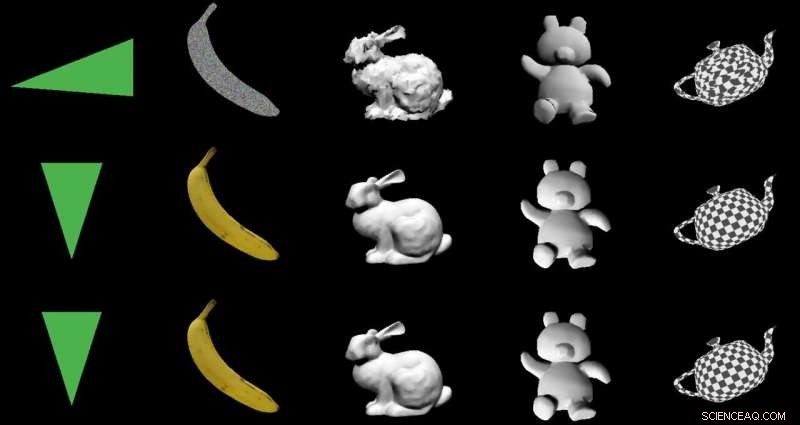
Seu molho mágico na produção de um objeto 3-D a partir de imagens 2-D é um "renderizador baseado em interpolação diferenciável, "ou DIB-R. Os pesquisadores da Nvidia treinaram seu modelo em conjuntos de dados que incluíam imagens de pássaros. Após o treinamento, O DIB-R tinha a capacidade de obter uma imagem de pássaro e fornecer uma representação 3D, com a forma e a textura certas de um pássaro 3-D.
A Nvidia descreveu ainda a entrada transformada em um mapa de recursos ou vetor que é usado para prever informações específicas, como forma, cor, textura e iluminação de uma imagem.
Por que isso é importante: Gizmodo O título de resumiu tudo. "A Nvidia ensinou uma IA para gerar instantaneamente modelos 3D totalmente texturizados a partir de imagens 2D planas." Essa palavra "instantaneamente" é importante.
O DIB-R pode produzir um objeto 3-D a partir de uma imagem 2-D em menos de 100 milissegundos, disse Lauren Finkle da Nvidia. "Ele faz isso alterando uma esfera poligonal - o modelo tradicional que representa uma forma 3-D. O DIB-R o altera para coincidir com a forma do objeto real retratado nas imagens 2-D."
Andrew Liszewski em Gizmodo destacou este elemento de tempo de 100 milissegundos. "Essa velocidade de processamento impressionante é o que torna esta ferramenta particularmente interessante, porque tem o potencial de melhorar muito a forma como máquinas como robôs, ou carros autônomos, ver o mundo, e entender o que está diante deles. "
Em relação aos carros autônomos, Liszewski disse, "As imagens estáticas retiradas de um stream de vídeo ao vivo de uma câmera podem ser convertidas instantaneamente em modelos 3-D, permitindo um carro autônomo, por exemplo, para medir com precisão o tamanho de um grande caminhão que precisa ser evitado. "

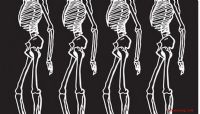
A equipe testou o DIB-R em quatro imagens 2D de pássaros (extrema esquerda). O primeiro experimento usou a imagem de uma toutinegra amarela (canto superior esquerdo) e produziu um objeto 3D (duas linhas superiores). Crédito:Nvidia
Um modelo que pudesse inferir um objeto 3-D a partir de uma imagem 2-D seria capaz de realizar um melhor rastreamento de objetos, e Lilly começou a pensar sobre seu uso na robótica. "Ao processar imagens 2-D em modelos 3-D, um robô autônomo estaria em uma posição melhor para interagir com seu ambiente de forma mais segura e eficiente, " ele disse.
A Nvidia observou que robôs autônomos, para fazer isso, "deve ser capaz de sentir e compreender seus arredores. O DIB-R pode melhorar potencialmente essas capacidades de percepção de profundidade."
Gizmodo de Liszewski, Enquanto isso, mencionou o que a abordagem da Nvidia pode fazer pela segurança. "O DIB-R pode até melhorar o desempenho das câmeras de segurança com a tarefa de identificar e rastrear pessoas, já que um modelo 3-D gerado instantaneamente tornaria mais fácil realizar correspondências de imagens conforme uma pessoa se move através de seu campo de visão. "
Os pesquisadores da Nvidia estariam apresentando seu modelo este mês na Conferência anual sobre Sistemas de Processamento de Informação Neural (NeurIPS), em Vancouver.
Aqueles que desejam aprender mais sobre suas pesquisas podem conferir seu artigo no arXiv, "Aprendendo a prever objetos 3-D com um renderizador diferenciável baseado em interpolação." Os autores são Wenzheng Chen, Jun Gao, Huan Ling, Edward J. Smith, Jaakko Lehtinen, Alec Jacobson e Sanja Fidler.
Eles propuseram "um renderizador diferenciável baseado em rasterização completo, para o qual os gradientes podem ser calculados analiticamente". Quando envolvido em uma rede neural, sua estrutura aprendeu a prever a forma, textura, e luz de imagens únicas, eles disseram, e eles exibiram sua estrutura "para aprender um gerador de formas texturizadas 3-D".
Em seu resumo, os autores observaram que "Muitos modelos de aprendizado de máquina operam em imagens, mas ignore o fato de que as imagens são projeções 2-D formadas pela geometria 3-D interagindo com a luz, em um processo denominado renderização. Permitir que os modelos de ML entendam a formação da imagem pode ser fundamental para a generalização. "
Eles apresentaram o DIB-R como uma estrutura que permite que gradientes sejam calculados analiticamente para todos os pixels em uma imagem.
Eles disseram que a chave para sua abordagem era "visualizar a rasterização do primeiro plano como uma interpolação ponderada de propriedades locais e a rasterização do plano de fundo como uma agregação baseada na distância da geometria global. Nossa abordagem permite a otimização precisa sobre as posições dos vértices, cores, normais, direções de luz e coordenadas de textura por meio de uma variedade de modelos de iluminação. "
© 2019 Science X Network