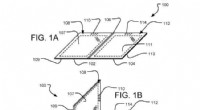
Uma nova ferramenta revela o que os modelos de IA deixam de fora na recriação de uma cena. Aqui, um GAN, ou rede adversária geradora, retirou o par de recém-casados de sua reconstrução (direita) da foto que foi solicitada a desenhar (esquerda). Crédito:Massachusetts Institute of Technology
Qualquer pessoa que já passou algum tempo nas redes sociais provavelmente percebeu que os GANs, ou redes adversárias geradoras, tornaram-se notavelmente bons em desenhar rostos. Eles podem prever como você ficará quando for velho e como será uma celebridade. Mas peça a um GAN para desenhar cenas do mundo maior e as coisas ficam estranhas.
Uma nova demonstração do MIT-IBM Watson AI Lab revela o que um modelo treinado em cenas de igrejas e monumentos decide deixar de fora quando desenha sua própria versão de, dizer, o Panteão de Paris, ou a Piazza di Spagna em Roma. O estudo maior, Vendo o que um GAN não pode gerar, foi apresentado na Conferência Internacional sobre Visão Computacional na semana passada.
"Os pesquisadores normalmente se concentram em caracterizar e melhorar o que um sistema de aprendizado de máquina pode fazer - o que ele presta atenção, e como entradas particulares levam a saídas particulares, "diz David Bau, um aluno de pós-graduação no Departamento de Engenharia Elétrica e Ciência da Computação e Laboratório de Ciência da Computação e Ciências Artificiais (CSAIL) do MIT. “Com este trabalho, esperamos que os pesquisadores prestem tanta atenção à caracterização dos dados que esses sistemas ignoram. "
Em um GAN, um par de redes neurais trabalham juntas para criar imagens hiper-realistas padronizadas com exemplos que eles receberam. Bau se interessou por GANs como uma forma de perscrutar dentro de redes neurais de caixa preta para entender o raciocínio por trás de suas decisões. Uma ferramenta anterior desenvolvida com seu consultor, Professor do MIT Antonio Torralba, e o pesquisador da IBM Hendrik Strobelt, tornou possível identificar os grupos de neurônios artificiais responsáveis por organizar a imagem em categorias do mundo real, como portas, árvores, e nuvens. Uma ferramenta relacionada, GANPaint, permite que artistas amadores adicionem e removam esses recursos de suas próprias fotos.
Um dia, ao ajudar um artista a usar o GANPaint, Bau encontrou um problema. "Como sempre, estávamos perseguindo os números, tentando otimizar a perda de reconstrução numérica para reconstruir a foto, "ele diz." Mas meu orientador sempre nos encorajou a olhar além dos números e examinar as imagens reais. Quando olhamos, o fenômeno saltou para fora:as pessoas estavam sendo retiradas seletivamente. "
Assim como GANs e outras redes neurais encontram padrões em pilhas de dados, eles ignoram os padrões, também. Bau e seus colegas treinaram diferentes tipos de GANs em cenas internas e externas. Mas não importa onde as fotos foram tiradas, os GANs omitiam consistentemente detalhes importantes, como pessoas, carros, sinais, fontes, e móveis, mesmo quando esses objetos apareceram com destaque na imagem. Em uma reconstrução GAN, um par de recém-casados se beijando nos degraus de uma igreja são apagados, deixando uma textura misteriosa de vestido de noiva na porta da catedral.
"Quando os GANs encontram objetos que não podem gerar, eles parecem imaginar como seria a cena sem eles, "diz Strobelt." Às vezes, as pessoas se transformam em arbustos ou desaparecem inteiramente no prédio atrás deles. "
Os pesquisadores suspeitam que a preguiça da máquina pode ser a culpada; embora um GAN seja treinado para criar imagens convincentes, ele pode aprender que é mais fácil se concentrar em prédios e paisagens e pular pessoas e carros mais difíceis de representar. Os pesquisadores sabem há muito tempo que os GANs tendem a ignorar alguns detalhes estatisticamente significativos. Mas este pode ser o primeiro estudo a mostrar que GANs de última geração podem omitir sistematicamente classes inteiras de objetos em uma imagem.
Uma IA que deixa cair alguns objetos de suas representações pode atingir seus objetivos numéricos enquanto perde os detalhes mais importantes para nós, humanos, diz Bau. Conforme os engenheiros recorrem aos GANs para gerar imagens sintéticas para treinar sistemas automatizados, como carros autônomos, existe o perigo de que as pessoas, sinais, e outras informações críticas podem ser descartadas sem que os humanos percebam. Mostra por que o desempenho do modelo não deve ser medido apenas pela precisão, diz Bau. “Precisamos entender o que as redes estão e não estão fazendo para ter certeza de que estão fazendo as escolhas que queremos que façam”.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.