Crédito:Petr Kratochvil / domínio público
Em um mundo de Deep Fakes e IA de linguagem natural muito humana, pesquisadores da Escola de Engenharia e Ciências Aplicadas (SEAS) de Harvard John A. Paulson e da IBM Research perguntaram:Existe uma maneira melhor de ajudar as pessoas a detectar texto gerado por IA?
Essa pergunta levou Sebastian Gehrmann, um Ph.D. candidato na SEAS, e Hendrik Strobelt, um pesquisador da IBM, para desenvolver um método estatístico, junto com uma ferramenta interativa de acesso aberto, para detectar texto gerado por AI.
Os geradores de linguagem natural são treinados em dezenas de milhões de textos online e imitam a linguagem humana, prevendo as palavras que mais frequentemente vêm uma após a outra. Por exemplo, as palavras "tenho", "sou" e "era" estão estaticamente mais propensas a vir depois da palavra "eu".
Usando essa ideia, Gehrmann e Strobelt desenvolveram um método que, em vez de identificar erros no texto, identifica o texto que é muito previsível.
"A ideia que tínhamos é que, à medida que os modelos ficam cada vez melhores, eles definitivamente são piores do que os humanos, que é detectável, tão bom ou melhor do que os humanos, que pode ser difícil de detectar com abordagens convencionais, "disse Gehrmann.
"Antes, você poderia dizer por todos os erros que o texto foi gerado por máquina, "disse Strobelt." Agora, não são mais os erros, mas sim o uso de palavras altamente prováveis (e um tanto enfadonhas) que revelam texto gerado por máquina. Com esta ferramenta, humanos e IA podem trabalhar juntos para detectar texto falso. "
Gehrmann e Strobelt apresentarão suas pesquisas, que foi coautorado por Alexander Rush, Associate in Computer Science at SEAS, na conferência da Association for Computational Linguistics (ACL) em 28 de julho a 2 de agosto.
Método de Gehrmann e Strobelt, conhecido como GLTR, é baseado em um modelo treinado em 45 milhões de textos de sites - a versão pública do modelo OpenAI, GPT-2. Porque ele usa GPT-2 para detectar o texto gerado, GLTR funciona melhor contra GPT-2, mas também funciona bem contra outros modelos.
Funciona assim:
Se você inserir uma passagem de texto na ferramenta, destaca o texto em verde, amarelo, vermelho ou roxo, cada cor significa a previsibilidade da palavra no contexto da palavra antes dela. Verde significa que a palavra era muito previsível, amarelo, moderadamente previsível, vermelho não muito previsível e roxo significa que o modelo não teria previsto a palavra.
Portanto, um parágrafo de texto gerado pela GPT-2 terá a seguinte aparência:

Crédito:Harvard University
Comparar, este é um real New York Times artigo:
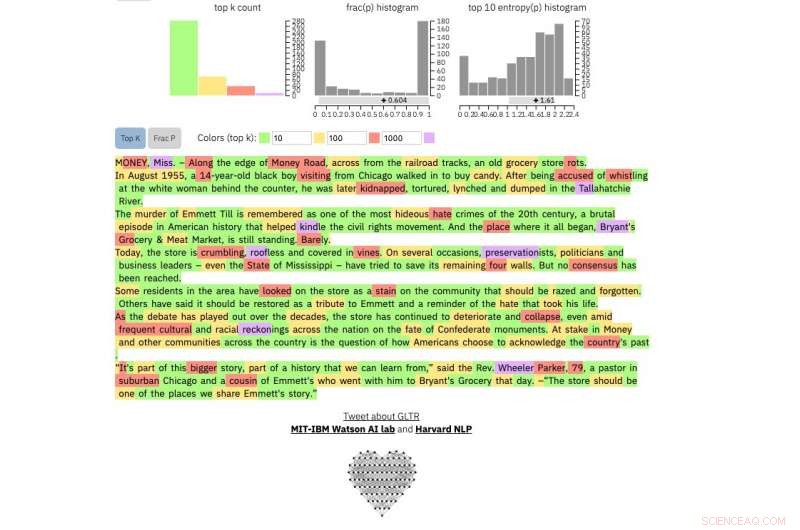
Crédito:Harvard University
E este é um trecho do provavelmente o texto humano mais imprevisível já escrito, De James Joyce Finnegans Wake :
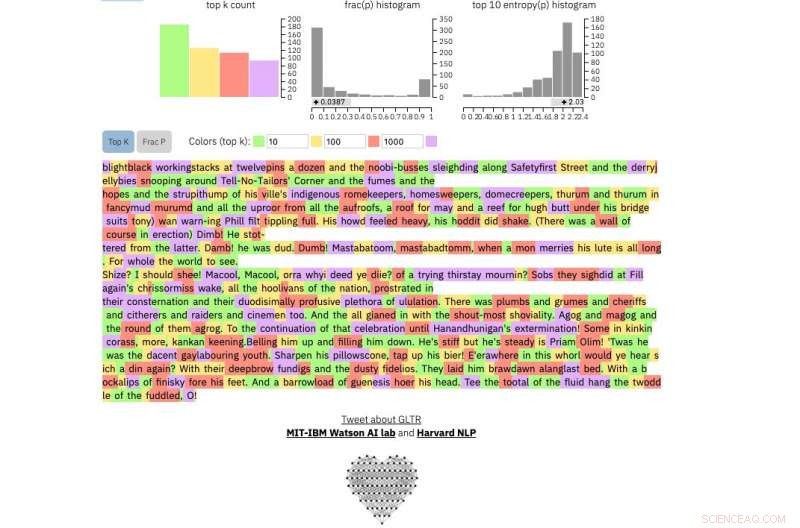
Crédito:Harvard University
O método não pretende substituir os humanos na identificação de textos falsos, mas sim apoiar a intuição e o entendimento humanos. Os pesquisadores testaram o modelo com um grupo de alunos de graduação em uma aula de Ciência da Computação do SEAS.
Sem o modelo, os alunos puderam identificar cerca de 50 por cento do texto gerado por IA. Com a sobreposição de cores, os alunos foram capazes de identificar 72 por cento.
Gehrmann e Strobelt dizem que com um pouco de treinamento e experiência com o programa, o número pode melhorar ainda mais.
"Nosso objetivo é criar sistemas de colaboração humana e de IA, "disse Gehrmann." Esta pesquisa tem como objetivo dar aos humanos mais informações para que possam tomar uma decisão informada sobre o que é real e o que é falso.