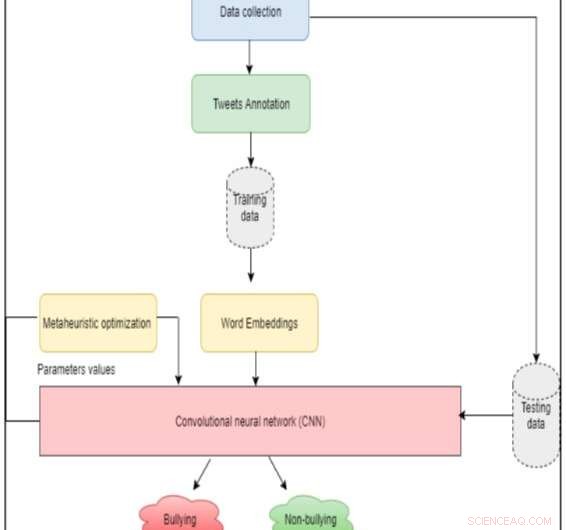
A arquitetura do sistema. Crédito:Al-Ajlan &Ykhlef.
Pesquisadores da King Saud University, na Arábia Saudita, desenvolveram uma nova abordagem para detectar o cyberbullying no Twitter usando aprendizado profundo chamado OCDD. Em contraste com outras abordagens de aprendizado profundo, que extraem recursos de tweets e os alimentam para um classificador, seu método representa um tweet como um conjunto de vetores de palavras.
Nos últimos anos, O cyberbullying nas redes sociais se tornou um problema enorme e amplamente discutido. O cyberbullying envolve o uso de canais de comunicação online para intimidar outros usuários, enviando intimidação, mensagens ameaçadoras ou abusivas. Isso pode ter consequências psicológicas e, às vezes, fatais para as vítimas.
Pesquisadores em todo o mundo têm tentado desenvolver novas maneiras de detectar o cyberbullying, gerenciá-lo e reduzir sua prevalência nas redes sociais. Muitas abordagens de aprendizado profundo para identificar o trabalho do cyberbullying por meio da análise de recursos textuais e do usuário. Contudo, essas técnicas vêm com várias limitações, o que pode reduzir significativamente seu desempenho.
Por exemplo, algumas dessas abordagens tentam melhorar a detecção introduzindo novos recursos. No entanto, aumentar o número de recursos pode complicar as fases de extração e seleção de recursos. Além disso, essas abordagens não consideram que alguns dados do usuário, como idade e data de nascimento, pode ser facilmente fabricado. Para lidar com as limitações dos métodos de detecção de cyberbullying existentes, Monirah A. Al-Ajlan e Mourad Ykhlef, dois pesquisadores da King Saud University, propôs uma nova abordagem chamada detecção otimizada de cyberbullying no Twitter (OCDD).
"Ao contrário do trabalho anterior neste campo, O OCDD não extrai recursos de tweets e os envia a um classificador:Em vez disso, representa um tweet como um conjunto de vetores de palavras, "os pesquisadores explicam em seu artigo, publicado no IEEE Explore e apresentado no 21 st Conferência Nacional de Computação da Saudi Computer Society (NCC). "Desta maneira, a semântica das palavras é preservada, e as fases de extração e seleção de recursos podem ser eliminadas. "
Al-Ajlan e Ykhlef construíram sua abordagem em dados de treinamento rotulados e geraram embeddings de palavras para palavras individuais usando GloVe, um algoritmo de aprendizagem não supervisionado que pode obter representações vetoriais para palavras. Esses embeddings de palavras são então enviados para uma rede neural convolucional (CNN) para detectar se eles podem estar associados ao cyberbullying.
Os algoritmos CNN normalmente consistem em uma camada de entrada e saída, bem como várias outras camadas. Definir parâmetros manualmente para cada uma dessas camadas pode ser uma tarefa demorada e desafiadora. Os pesquisadores decidiram, então, incorporar um algoritmo de otimização metaheurística em seu modelo, o que pode facilitar este processo, identificando valores ótimos ou quase ótimos a serem usados para classificação.
"O OCDD avança o estado atual de detecção de cyberbullying eliminando a difícil tarefa de extração / seleção de recursos e substituindo-os por vetores de palavras que capturam a semântica das palavras e CNN que classifica os tweets de uma forma mais inteligente do que os algoritmos de classificação tradicionais, "os pesquisadores escrevem em seu artigo.
Quando testado em tarefas de mineração de texto, O OCDD alcançou resultados muito promissores. Contudo, ainda não foi implementado e avaliado em contextos de detecção de cyberbullying. Os pesquisadores agora planejam adaptar sua abordagem para que também possam analisar textos em árabe.
© 2019 Science X Network














