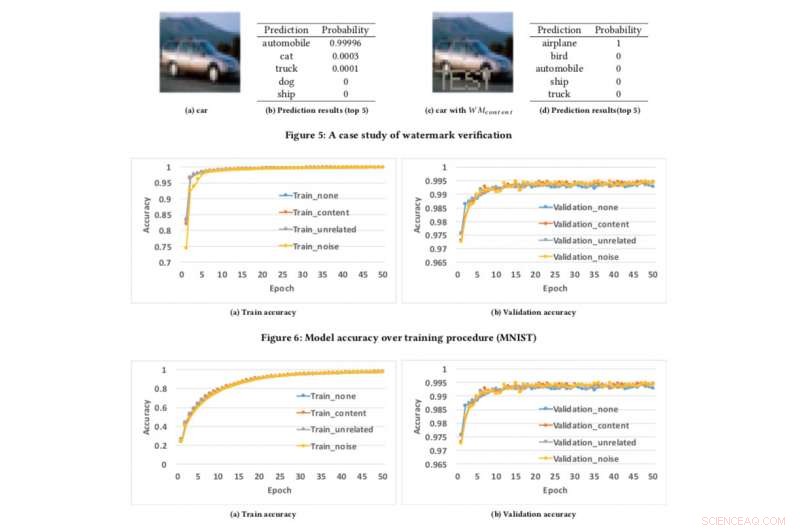
Precisão do modelo sobre o procedimento de treinamento. Crédito:CIFAR10
Se pudermos proteger os vídeos, áudio e fotos com marca d'água digital, por que não modelos de IA?
Esta é a pergunta que meus colegas e eu nos perguntamos enquanto procurávamos desenvolver uma técnica para garantir aos desenvolvedores que seu trabalho árduo na construção de IA, como modelos de aprendizagem profunda, pode ser protegido. Você pode estar pensando, "Protegido de quê?" Nós vamos, por exemplo, e se o seu modelo de IA for roubado ou usado indevidamente para fins nefastos, como oferecer um serviço plagiado baseado em um modelo roubado? Isso é uma preocupação, particularmente para líderes de IA, como a IBM.
No início deste mês, apresentamos nossa pesquisa na conferência AsiaCCS '18 em Incheon, República da Coreia, e temos o orgulho de dizer que nossa técnica de avaliação abrangente para enfrentar esse desafio demonstrou ser altamente eficaz e robusta. Nossa principal inovação é que nosso conceito pode verificar remotamente a propriedade de serviços de rede neural profunda (DNN) usando consultas simples de API.
À medida que os modelos de aprendizagem profunda são mais amplamente implantados e se tornam mais valiosos, eles são cada vez mais alvos de adversários. Nossa ideia, que está com patente pendente, se inspira nas técnicas populares de marca d'água usadas para conteúdo multimídia, como vídeos e fotos.
Ao colocar uma marca d'água em uma foto, há dois estágios:incorporação e detecção. No estágio de incorporação, os proprietários podem sobrepor a palavra "COPYRIGHT" na foto (ou marcas d'água invisíveis à percepção humana) e se ela for roubada e usada por terceiros, confirmamos isso no estágio de detecção, por meio do qual os proprietários podem extrair as marcas d'água como evidência legal para provar a propriedade. A mesma ideia pode ser aplicada ao DNN.
Incorporando marcas d'água em modelos DNN, se eles forem roubados, podemos verificar a propriedade extraindo marcas d'água dos modelos. Contudo, diferente da marca d'água digital, que incorpora marcas d'água em conteúdo multimídia, precisávamos projetar um novo método para incorporar marcas d'água em modelos DNN.
Em nosso jornal, descrevemos uma abordagem para infundir marcas d'água em modelos DNN, e projetar um mecanismo de verificação remota para determinar a propriedade de modelos DNN usando chamadas de API.
Desenvolvemos três algoritmos de geração de marca d'água para gerar diferentes tipos de marcas d'água para modelos DNN:
Para testar nossa estrutura de marca d'água, usamos dois conjuntos de dados públicos:MNIST, um conjunto de dados de reconhecimento de dígitos manuscritos que tem 60, 000 imagens de treinamento e 10, 000 imagens de teste e CIFAR10, um conjunto de dados de classificação de objeto com 50, 000 imagens de treinamento e 10, 000 imagens de teste.
Executar o experimento é bastante simples:simplesmente fornecemos ao DNN uma imagem especificamente criada, que dispara uma resposta inesperada, mas controlada, se o modelo tiver marca d'água. Esta não é a primeira vez que a marca d'água foi considerada, mas os conceitos anteriores eram limitados por exigir acesso aos parâmetros do modelo. Contudo, no mundo real, os modelos roubados são geralmente implantados remotamente, e o serviço plagiado não divulgava os parâmetros dos modelos roubados. Além disso, as marcas d'água incorporadas em modelos DNN são robustas e resistentes a diferentes mecanismos de contra-marca d'água, como o ajuste fino, poda de parâmetro, e ataques de inversão de modelo.
Ai, nossa estrutura tem algumas limitações. Se o modelo que vazou não for implantado como um serviço on-line, mas usado como um serviço interno, então não podemos detectar nenhum roubo, mas é claro que o plagiador não pode monetizar diretamente os modelos roubados.
Além disso, nossa estrutura de marca d'água atual não pode proteger os modelos DNN de serem roubados por meio de APIs de previsão, por meio do qual os invasores podem explorar a tensão entre o acesso à consulta e a confidencialidade dos resultados para aprender os parâmetros dos modelos de aprendizado de máquina. Contudo, tais ataques só demonstraram funcionar bem na prática para algoritmos de aprendizado de máquina convencionais com menos parâmetros de modelo, como árvores de decisão e regressões logísticas.
No momento, estamos procurando implementar isso na IBM e explorar como a tecnologia pode ser fornecida como um serviço para os clientes.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.