Artigo de refutação de pesquisa revela uso indevido de conjuntos de dados do Holocausto
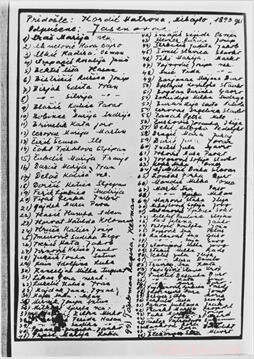 p Um de mais de 7, 000 listas de nomes de campos de concentração no Museu Memorial do Holocausto dos EUA. Esta é uma lista escrita à mão de mulheres sérvias e croatas que foram deportadas para o campo de concentração de Jasenovac. Crédito:Museu Memorial do Holocausto dos Estados Unidos
p Um de mais de 7, 000 listas de nomes de campos de concentração no Museu Memorial do Holocausto dos EUA. Esta é uma lista escrita à mão de mulheres sérvias e croatas que foram deportadas para o campo de concentração de Jasenovac. Crédito:Museu Memorial do Holocausto dos Estados Unidos
p O professor de engenharia aeroespacial Melkior Ornik também é matemático, um aficionado por história, e um forte crente na integridade quando se trata de usar ciência concreta em discussões públicas. Então, quando uma história apareceu em seu feed de notícias sobre dois pesquisadores que desenvolveram um método estatístico para analisar conjuntos de dados e o usaram para supostamente refutar o número de vítimas do Holocausto em um campo de concentração na Croácia, naturalmente chamou sua atenção. p Ornik é professor do Departamento de Engenharia Aeroespacial da Universidade de Illinois Urbana-Champaign. Ele passou a estudar a pesquisa em profundidade e usou o método para reanalisar os mesmos dados do Museu Memorial do Holocausto dos Estados Unidos. Em seguida, ele escreveu um artigo de refutação desmascarando as descobertas dos pesquisadores.
p A refutação de Ornik foi publicada na mesma revista que o artigo original. Ele disse que o editor lhe pediu para incluir uma lista de respostas para algumas das possíveis perguntas que outros cientistas podem ter ao ler seu artigo. Algumas semanas depois, a revista colocou uma nota no artigo original declarando que eles não endossam ou compartilham as opiniões dos autores, e recomendou a leitura do artigo de Ornik.
p "Como cientistas, como engenheiros, Acho que é nosso dever corrigir a ciência falha e falha, "Ornik disse." Há muito esforço para fazer com que o público e os legisladores acreditem na ciência, que quando um especialista em matemática diz que tem provas, dá crédito ao argumento. Mas quando suas afirmações não são comprovadamente verdadeiras, não é bom para a ciência e não é bom para a sociedade. É por isso que é especialmente importante para os cientistas desafiarem descobertas falsas quando as descobrimos. "
p De acordo com Ornik, alguns indivíduos promovem a visão de que os campos de concentração ou não existiam ou não eram usados para matar pessoas, ou que o número de vítimas atualmente amplamente aceito tenha sido substancialmente inflado. A maioria dos historiadores não leva as afirmações a sério à luz dos vastos dados e evidências disponíveis.
p "O fato de os autores do artigo original afirmarem que encontraram provas matemáticas de que a lista de vítimas daquele campo foi fabricada tem implicações históricas óbvias, "Ornik disse." Eu acho, em certa medida, o dano já foi feito, mas senti a necessidade de registrar as suposições, imprecisões, e uso indevido dos dados brutos do museu que encontrei na pesquisa original. "
p O artigo ao qual Ornik respondeu apresenta um novo método para identificar anomalias em um conjunto de histogramas. Ornik disse que não contesta o mérito do método apresentado no artigo original, apenas sua aplicação ao campo de concentração de Jasenovac.
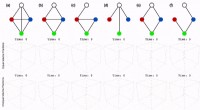
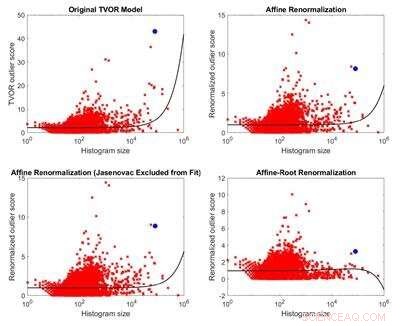 p Comparação do modelo de identificação de outlier original e três modelos derivados dele. Devido à inaplicabilidade de suas suposições ao conjunto de dados considerado, o modelo original não tem fundamento teórico. Três modelos alternativos são menos influenciados pelo tamanho do que o modelo original e produzem resultados opostos. Crédito:Melkior Ornik
p Comparação do modelo de identificação de outlier original e três modelos derivados dele. Devido à inaplicabilidade de suas suposições ao conjunto de dados considerado, o modelo original não tem fundamento teórico. Três modelos alternativos são menos influenciados pelo tamanho do que o modelo original e produzem resultados opostos. Crédito:Melkior Ornik
p Ornik suspeitou das conclusões do artigo porque os pesquisadores deram a entender em um caso que uma lista menor naturalmente tem uma pontuação de outlier menor, mas eles compararam as pontuações entre os tamanhos das listas de vítimas para afirmar que aquela relacionada a Jasenovac, um dos maiores, foi problemático.
p "Comecei a procurar ver se havia algum tipo de viés para o tamanho e se eles eram realmente mais propensos a atribuir o sinal de ser problemático a uma lista maior ou não. apesar das afirmações dos autores, eles eram, Ornik disse. "As listas maiores têm maior probabilidade de serem computadas como problemáticas do que as listas menores quando seu método é aplicado aos dados."
p Ornik, que normalmente usa análises estatísticas semelhantes em aplicações aeroespaciais, explicou outra razão pela qual seu argumento estatístico não funciona.
p "Quando você olha para os dados, uma coleção de qualquer coisa, e você quer descobrir um outlier - algo diferente - você precisa assumir que todas as partes dos dados vêm da mesma fonte, a mesma distribuição. Faça uma lista das vítimas por ano de nascimento. Isso geraria um gráfico das idades de cada pessoa. Digamos que 10% tenham mais de 70 anos. Agora, essa distribuição não seria verdadeira para uma lista de crianças deportadas, por exemplo, porque essa lista, por definição, é estruturalmente diferente. Também é diferente de uma lista de todas as pessoas que têm carteira de identidade. Os bilhetes de identidade são emitidos apenas para pessoas que não sejam crianças. Ainda, as listas com as quais esses pesquisadores trabalharam vieram de uma infinidade de fontes e incluem listas de crianças, listas de pessoas se casando, listas de prisioneiros de guerra - coisas que, por definição, não podem ter vindo da mesma distribuição. "
p Outro grande erro no artigo original, Ornik disse, é que algumas listas duplicadas foram tratadas como duas listas separadas. Isso significava que aproximadamente 67 por cento de todo o banco de dados era, na verdade, sublistas da lista maior.
p "O 7, Mais de 000 listas publicadas online pelo Museu do Holocausto não são comissariadas, "Ornik disse." Por exemplo, existem duas listas que contêm exatamente os mesmos dados; um está em cirílico e o outro usa o alfabeto latino. Mas eles os trataram como duas listas separadas. Existem outras listas que contêm o mesmo nome, mas não há como saber se são a mesma pessoa ou duas pessoas diferentes nascidas no mesmo dia com nomes idênticos. Eles poderiam ter removido os erros mais flagrantes em que uma lista está claramente duplicada, mas o resto, você precisaria de acesso aos dados históricos originais. "
p Tanto o artigo original quanto o artigo de Ornik, "Comentário sobre 'TVOR:Finding Discrete Total Variation Outliers Between Histograms, '"são publicados em
Acesso IEEE .