O estudo destaca como os modelos de IA usam atalhos potencialmente perigosos para resolver tarefas complexas de reconhecimento
Crédito:Universidade de York
Redes neurais convolucionais profundas (DCNNs) não veem objetos da mesma forma que os humanos – usando percepção de forma configural – e isso pode ser perigoso em aplicações de IA do mundo real, diz o professor James Elder, coautor de um estudo da Universidade de York publicado hoje.
Publicado na revista Cell Press
iScience , Modelos de aprendizado profundo falham em capturar a natureza configuracional da percepção da forma humana é um estudo colaborativo de Elder, que detém a cátedra de pesquisa de York em visão humana e computacional e é co-diretor do Centro de IA e sociedade de York e professor assistente de psicologia Nicholas Baker no Loyola College em Chicago, ex-bolsista de pós-doutorado VISTA em York.
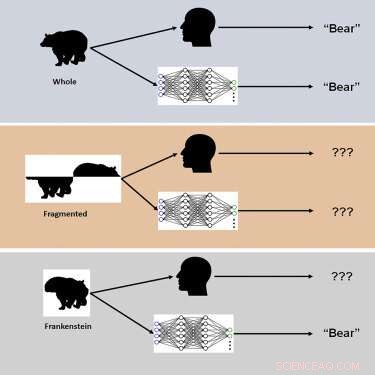
O estudo empregou novos estímulos visuais chamados "Frankensteins" para explorar como o cérebro humano e as DCNNs processam propriedades de objetos holísticos e configurados.
“Frankensteins são simplesmente objetos que foram desmontados e montados de forma errada”, diz Elder. "Como resultado, eles têm todos os recursos locais certos, mas nos lugares errados."
Os pesquisadores descobriram que enquanto o sistema visual humano é confundido com os Frankensteins, os DCNNs não são – revelando uma insensibilidade às propriedades dos objetos de configuração.
“Nossos resultados explicam por que modelos de IA profundos falham sob certas condições e apontam para a necessidade de considerar tarefas além do reconhecimento de objetos para entender o processamento visual no cérebro”, diz Elder. "Esses modelos profundos tendem a usar 'atalhos' ao resolver tarefas complexas de reconhecimento. Embora esses atalhos possam funcionar em muitos casos, eles podem ser perigosos em alguns dos aplicativos de IA do mundo real em que estamos trabalhando atualmente com nossos parceiros do setor e do governo, “Ancião aponta.
Uma dessas aplicações são os sistemas de segurança de vídeo de trânsito:"Os objetos em uma cena de trânsito movimentada - os veículos, bicicletas e pedestres - obstruem uns aos outros e chegam aos olhos de um motorista como um amontoado de fragmentos desconectados", explica Elder. "O cérebro precisa agrupar corretamente esses fragmentos para identificar as categorias e localizações corretas dos objetos. Um sistema de IA para monitoramento de segurança no trânsito que só é capaz de perceber os fragmentos individualmente falhará nessa tarefa, potencialmente entendendo mal os riscos para os usuários vulneráveis da estrada. "
De acordo com os pesquisadores, as modificações no treinamento e na arquitetura destinadas a tornar as redes mais parecidas com o cérebro não levaram ao processamento de configuração, e nenhuma das redes foi capaz de prever com precisão os julgamentos de objetos humanos de teste por teste. "Nós especulamos que, para corresponder à sensibilidade de configuração humana, as redes devem ser treinadas para resolver uma gama mais ampla de tarefas de objetos além do reconhecimento de categorias", observa Elder.
+ Explorar mais Avançando a percepção humana em veículos autônomos














