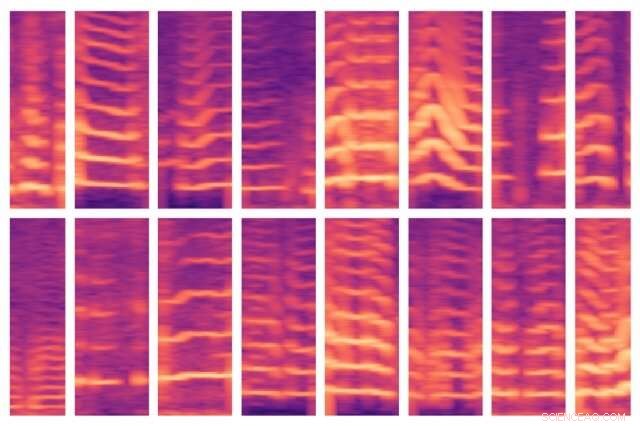
Um novo modelo desenvolvido pelo MIT automatiza uma etapa crítica no uso de IA para a tomada de decisões médicas, onde os especialistas geralmente identificam recursos importantes em grandes conjuntos de dados de pacientes manualmente. O modelo foi capaz de identificar automaticamente os padrões de voz de pessoas com nódulos nas cordas vocais (mostrado aqui) e, por sua vez, use esses recursos para prever quais pessoas têm e não têm o transtorno. Crédito:Massachusetts Institute of Technology
Os cientistas da computação do MIT esperam acelerar o uso da inteligência artificial para melhorar a tomada de decisões médicas, automatizando uma etapa importante que geralmente é feita manualmente - e isso está se tornando mais trabalhoso à medida que certos conjuntos de dados ficam cada vez maiores.
O campo da análise preditiva é cada vez mais promissor para ajudar os médicos a diagnosticar e tratar pacientes. Modelos de aprendizado de máquina podem ser treinados para encontrar padrões nos dados do paciente para auxiliar no tratamento da sepse, projetar regimes de quimioterapia mais seguros, e prever o risco de um paciente ter câncer de mama ou morrer na UTI, para citar apenas alguns exemplos.
Tipicamente, conjuntos de dados de treinamento consistem em muitos indivíduos doentes e saudáveis, mas com relativamente poucos dados para cada assunto. Os especialistas devem então encontrar apenas aqueles aspectos - ou "recursos" - nos conjuntos de dados que serão importantes para fazer previsões.
Essa "engenharia de recursos" pode ser um processo trabalhoso e caro. Mas está se tornando ainda mais desafiador com o surgimento de sensores vestíveis, porque os pesquisadores podem monitorar mais facilmente a biometria dos pacientes por longos períodos, rastreando padrões de sono, maneira de andar, e atividade de voz, por exemplo. Depois de apenas uma semana de monitoramento, os especialistas podem ter vários bilhões de amostras de dados para cada assunto.
Em um artigo apresentado na conferência Machine Learning for Healthcare esta semana, Os pesquisadores do MIT demonstram um modelo que aprende automaticamente os recursos preditivos de distúrbios das cordas vocais. Os recursos vêm de um conjunto de dados de cerca de 100 assuntos, cada um com cerca de uma semana de dados de monitoramento de voz e vários bilhões de amostras - em outras palavras, um pequeno número de assuntos e uma grande quantidade de dados por assunto. O conjunto de dados contém sinais capturados de um pequeno sensor acelerômetro montado no pescoço dos sujeitos.
Em experimentos, o modelo usava recursos extraídos automaticamente desses dados para classificar, com alta precisão, pacientes com e sem nódulos nas cordas vocais. Estas são lesões que se desenvolvem na laringe, muitas vezes por causa de padrões de uso indevido de voz, como cantando ou gritando. Mais importante, o modelo realizou essa tarefa sem um grande conjunto de dados rotulados à mão.
"Está se tornando cada vez mais fácil coletar conjuntos de dados de longas séries de tempo. Mas você tem médicos que precisam aplicar seus conhecimentos para rotular o conjunto de dados, "diz o autor principal Jose Javier Gonzalez Ortiz, um Ph.D. Aluno do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL). "Queremos remover essa parte manual para os especialistas e transferir toda a engenharia de recursos para um modelo de aprendizado de máquina."
O modelo pode ser adaptado para aprender os padrões de qualquer doença ou condição. Mas a capacidade de detectar os padrões de uso diário da voz associados aos nódulos das cordas vocais é um passo importante no desenvolvimento de métodos aprimorados de prevenção, diagnosticar, e tratar a doença, dizem os pesquisadores. Isso pode incluir desenvolver novas maneiras de identificar e alertar as pessoas sobre comportamentos vocais potencialmente prejudiciais.
Juntando-se a Gonzalez Ortiz no papel está John Guttag, o Professor Dugald C. Jackson de Ciência da Computação e Engenharia Elétrica e chefe do Grupo de Inferência de Orientação de Dados do CSAIL; Robert Hillman, Jarrad Van Stan, e Daryush Mehta, todos do Centro de Cirurgia Laríngea e Reabilitação de Voz do Massachusetts General Hospital; e Marzyeh Ghassemi, professor assistente de ciência da computação e medicina na Universidade de Toronto.
Aprendizagem forçada de recursos
Por anos, os pesquisadores do MIT trabalharam com o Centro de Cirurgia Laríngea e Reabilitação de Voz para desenvolver e analisar dados de um sensor para rastrear o uso da voz do sujeito durante todas as horas de vigília. O sensor é um acelerômetro com um nó que se cola ao pescoço e é conectado a um smartphone. Enquanto a pessoa fala, o smartphone coleta dados dos deslocamentos no acelerômetro.
Em seu trabalho, os pesquisadores coletaram esses dados de uma semana - chamados de dados de "séries temporais" - de 104 indivíduos, metade dos quais foi diagnosticado com nódulos nas cordas vocais. Para cada paciente, havia também um controle de correspondência, significando um sujeito saudável de idade semelhante, sexo, ocupação, e outros fatores.
Tradicionalmente, os especialistas precisariam identificar manualmente os recursos que podem ser úteis para um modelo detectar várias doenças ou condições. Isso ajuda a prevenir um problema comum de aprendizado de máquina na área de saúde:overfitting. Isso é quando, em treinamento, um modelo "memoriza" os dados do assunto em vez de aprender apenas os recursos clinicamente relevantes. Em teste, esses modelos muitas vezes falham em discernir padrões semelhantes em assuntos anteriormente não vistos.
"Em vez de aprender recursos que são clinicamente significativos, um modelo vê padrões e diz:"Esta é Sarah, e eu sei que Sarah é saudável, e este é Peter, que tem um nódulo nas cordas vocais. "Então, é apenas memorizar padrões de assuntos. Então, quando vê dados de Andrew, que tem um novo padrão de uso vocal, não consegue descobrir se esses padrões correspondem a uma classificação, "Gonzalez Ortiz diz.
O principal desafio, então, estava evitando overfitting ao mesmo tempo em que automatizava a engenharia manual de recursos. Para esse fim, os pesquisadores forçaram o modelo a aprender recursos sem informações do assunto. Para sua tarefa, isso significava capturar todos os momentos em que os sujeitos falam e a intensidade de suas vozes.
À medida que seu modelo rastreia os dados de um sujeito, é programado para localizar segmentos de voz, que compreendem apenas cerca de 10 por cento dos dados. Para cada uma dessas janelas de voz, o modelo calcula um espectrograma, uma representação visual do espectro de frequências que variam ao longo do tempo, que é freqüentemente usado para tarefas de processamento de voz. Os espectrogramas são então armazenados como grandes matrizes de milhares de valores.
Mas essas matrizes são enormes e difíceis de processar. Então, um autoencoder - uma rede neural otimizada para gerar codificações de dados eficientes a partir de grandes quantidades de dados - primeiro comprime o espectrograma em uma codificação de 30 valores. Em seguida, ele descompacta essa codificação em um espectrograma separado.
Basicamente, o modelo deve garantir que o espectrograma descompactado se pareça muito com a entrada do espectrograma original. Ao fazer isso, ele é forçado a aprender a representação compactada de cada entrada de segmento do espectrograma sobre os dados completos da série temporal de cada sujeito. As representações compactadas são os recursos que ajudam a treinar modelos de aprendizado de máquina para fazer previsões.
Mapeando características normais e anormais
Em treinamento, o modelo aprende a mapear esses recursos para "pacientes" ou "controles". Os pacientes terão mais padrões de voz do que os controles. Em testes em assuntos nunca vistos anteriormente, o modelo condensa da mesma forma todos os segmentos do espectrograma em um conjunto reduzido de recursos. Então, são regras da maioria:se o assunto tem segmentos de voz anormais, eles são classificados como pacientes; se eles têm principalmente normais, eles são classificados como controles.
Em experimentos, o modelo teve um desempenho tão preciso quanto os modelos de última geração que requerem engenharia manual de recursos. Mais importante, o modelo dos pesquisadores foi executado com precisão tanto no treinamento quanto no teste, indicando que está aprendendo padrões clinicamente relevantes a partir dos dados, informações não específicas do assunto.
Próximo, os pesquisadores desejam monitorar como vários tratamentos - como cirurgia e terapia vocal - afetam o comportamento vocal. Se os comportamentos dos pacientes mudarem de anormal para normal ao longo do tempo, eles provavelmente estão melhorando. Eles também esperam usar uma técnica semelhante em dados de eletrocardiograma, que é usado para monitorar as funções musculares do coração.
Esta história foi republicada por cortesia do MIT News (web.mit.edu/newsoffice/), um site popular que cobre notícias sobre pesquisas do MIT, inovação e ensino.