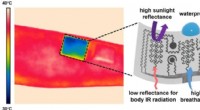
Comparação de modelos de previsão de profundidade com um videoclipe com câmeras e pessoas em movimento. Crédito:Google
Quem disse que a mania viral chamada Mannequin Challenge (MC) acabou? Não tão. Os pesquisadores se voltaram para o Desafio que ganhou atenção em 2016 para cumprir seu objetivo. Eles usaram o MC para treinar uma rede neural que pode reconstruir informações de profundidade dos vídeos.
"Aprendendo as profundezas de mover pessoas observando pessoas congeladas" é o nome do jornal, agora no arXiv, de autoria de Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu e William Freeman. O artigo foi apresentado em abril deste ano.
O Desafio do Manequim? Quem pode esquecer? Esta foi uma tendência do YouTube que se tornou viral. Anthony Alford em InfoQ trouxe os leitores de volta a 2016, quando um meme da internet tinha pessoas agrupadas em grupos que se faziam passar por manequins. Eles estavam "congelados", mas um cinegrafista fazia movimentos ao redor da cena capturando um vídeo de diferentes ângulos.
Alford escreveu, porque a câmera está se movendo e o resto da cena está estático, os métodos de paralaxe podem facilmente reconstruir mapas de profundidade precisos de figuras humanas em uma variedade de poses.
Como os autores declararam, os vídeos envolveram congelamento em diversos, poses naturais, enquanto uma câmera portátil percorria a cena.
Para treinar a rede neural, a equipe converteu 2, 000 dos vídeos em imagens 2-D com dados de profundidade de alta resolução.
Alford disse que de 2, 000 vídeos de MC do YouTube, um conjunto de dados foi produzido de 4, 690 sequências com um total de mais de 170 mil pares de profundidade de imagem válidos. O alvo do sistema de aprendizagem era o mapa de profundidade conhecido para a imagem de entrada, calculado a partir dos vídeos MC. O DNN aprendeu a tirar a imagem de entrada, mapa de profundidade inicial, e máscara humana, e produzir um mapa de profundidade "refinado" onde os valores de profundidade dos humanos foram preenchidos.
Christine Fisher, Engadget :"Para treinar a rede neural, os pesquisadores converteram os clipes em imagens 2-D, estimou a pose da câmera e criou mapas de profundidade. A IA foi então capaz de prever a profundidade de objetos em movimento em vídeos com maior precisão do que era possível anteriormente. "
Aceitar o desafio foi descrito por dois dos co-autores do artigo em maio, em um blog do Google.
"Como toda a cena está parada (apenas a câmera se move), métodos baseados em triangulação - como multi-view-stereo (MVS) - funcionam, e podemos obter mapas de profundidade precisos para toda a cena, incluindo as pessoas nela. Reunimos aproximadamente 2.000 desses vídeos, abrangendo uma ampla gama de cenas realistas com pessoas posando naturalmente em diferentes configurações de grupo. "Tali Dekel, cientista pesquisador e Forrester Cole, engenheiro de software, percepção da máquina, escreveu mais sobre o desafio que enfrentaram.
"O sistema visual humano tem uma capacidade notável de dar sentido ao nosso mundo 3-D a partir de sua projeção 2-D. Mesmo em ambientes complexos com vários objetos em movimento, as pessoas são capazes de manter uma interpretação viável da geometria dos objetos e ordenação de profundidade. O campo da visão computacional há muito estudou como conseguir recursos semelhantes reconstruindo computacionalmente a geometria de uma cena a partir de dados de imagem 2-D, mas uma reconstrução robusta continua difícil em muitos casos. "
Por que isso é importante:"Embora haja um aumento recente no uso de aprendizado de máquina para previsão de profundidade, este trabalho é o primeiro a adaptar uma abordagem baseada em aprendizagem para o caso de câmera simultânea e movimento humano, "disseram no blog de maio." Neste trabalho, focamos especificamente em humanos porque eles são um alvo interessante para realidade aumentada e efeitos de vídeo 3-D. "
Falando sobre resultados, Karen Hao, MIT Technology Review , disse que os pesquisadores converteram 2, 000 dos vídeos em imagens 2-D com dados de profundidade de alta resolução e os usou para treinar uma rede neural. Ele foi então capaz de prever a profundidade de objetos em movimento em um vídeo com uma precisão muito maior do que era possível com métodos de última geração anteriores.
© 2019 Science X Network