Os pesquisadores consideram o problema da navegação da posição inicial até a posição final. Sua abordagem (WayPtNav) consiste em um módulo de percepção baseado em aprendizagem e um módulo de planejamento baseado em modelo de dinâmica. O módulo de percepção prevê um waypoint com base na observação da imagem RGB de primeira pessoa atual. Este waypoint é usado pelo módulo de planejamento baseado em modelo para projetar um controlador que regula suavemente o sistema para este waypoint. Este processo é repetido para a próxima imagem até que o robô alcance o objetivo. Crédito:Bansal e al.
Pesquisadores da UC Berkeley e do Facebook AI Research desenvolveram recentemente uma nova abordagem para a navegação de robôs em ambientes desconhecidos. A abordagem deles, apresentado em um artigo pré-publicado no arXiv, combina técnicas de controle baseadas em modelos com percepção baseada em aprendizagem.
O desenvolvimento de ferramentas que permitem aos robôs navegar pelos ambientes circundantes é um desafio chave e constante no campo da robótica. Nas décadas recentes, os pesquisadores tentaram resolver esse problema de várias maneiras.
A comunidade de pesquisa de controle investigou principalmente a navegação para um agente (ou sistema) conhecido dentro de um ambiente conhecido. Nestes casos, um modelo de dinâmica do agente e um mapa geométrico do ambiente em que ele estará navegando estão disponíveis, portanto, esquemas de controle ótimo podem ser usados para obter trajetórias suaves e sem colisões para o robô chegar a um local desejado.
Esses esquemas são normalmente usados para controlar uma série de sistemas físicos reais, como aviões ou robôs industriais. Contudo, essas abordagens são um tanto limitadas, pois exigem conhecimento explícito do ambiente em que um sistema estará navegando. Na comunidade de pesquisa de aprendizagem, por outro lado, A navegação do robô é geralmente estudada para um agente desconhecido explorando um ambiente desconhecido. Isso significa que um sistema adquire políticas para mapear diretamente as leituras dos sensores integrados para controlar os comandos de ponta a ponta.
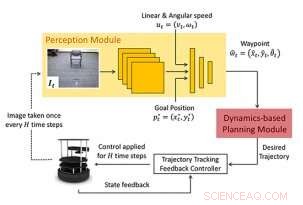
Estrutura proposta:A nova abordagem para navegação consiste em um módulo de percepção baseado em aprendizagem e um módulo de planejamento baseado em modelo de dinâmica. O módulo de percepção consiste em um CNN que emite um próximo estado ou ponto de passagem desejado. Este waypoint é usado pelo módulo de planejamento baseado em modelo para projetar um controlador para regular suavemente o sistema para o waypoint. Crédito:Bansal e al.
Essas abordagens podem ter várias vantagens, pois permitem que as políticas sejam aprendidas sem nenhum conhecimento do sistema e do ambiente em que estará navegando. Apesar disso, estudos anteriores sugerem que essas técnicas não generalizam bem entre os diferentes agentes. Além disso, aprender tais políticas freqüentemente requer um grande número de amostras de treinamento.
"Nesse artigo, estudamos a navegação do robô em ambientes estáticos sob o pressuposto da medição perfeita do estado do robô, "os pesquisadores escreveram em seu artigo." Fazemos a observação crucial de que os problemas mais interessantes envolvem um sistema conhecido em um ambiente desconhecido. Esta observação motiva o projeto de uma abordagem fatorada que usa o aprendizado para lidar com ambientes desconhecidos e alavanca o controle ideal usando a dinâmica do sistema conhecido para produzir uma locomoção suave. "
A equipe de pesquisadores da UC Berkeley e do Facebook treinou um modelo de rede neural convolucional (CNN) baseado em políticas de alto nível, que usam observações de imagens RGB atuais para produzir uma sequência de estados intermediários, ou 'waypoints'. Em última análise, esses pontos de referência guiam um robô para o local desejado seguindo um caminho livre de colisão, em ambientes anteriormente desconhecidos.
A abordagem deles, apelidada de navegação baseada em waypoint (WayPtNav), essencialmente acopla as técnicas de controle baseadas em modelos com a percepção baseada na aprendizagem. O módulo de percepção baseado em aprendizagem gera pontos de referência, que guiam o robô até seu local de destino por meio de um caminho livre de colisões. O planejador baseado em modelo, por outro lado, usa esses pontos de referência para gerar uma trajetória suave e dinamicamente viável, que é então executado no sistema usando o controle de feedback.
Os pesquisadores avaliaram sua abordagem em uma bancada de teste de hardware, chamado TurtleBot2. Seus testes coletaram resultados altamente promissores, com o WayPtNav permitindo a navegação em ambientes desordenados e dinâmicos, ao mesmo tempo, superando uma abordagem de aprendizagem ponta a ponta.
"Nossos experimentos em ambientes desordenados simulados do mundo real e em um veículo terrestre real demonstram que a abordagem proposta pode alcançar os locais de destino de maneira mais confiável e eficiente em ambientes novos, em comparação com uma alternativa baseada em aprendizagem puramente ponta a ponta, "escreveram os pesquisadores.
A nova abordagem apresentada por esta equipe de pesquisadores pode melhorar a navegação do robô em novos ambientes internos. Estudos futuros podem tentar melhorar ainda mais o WayPtNav, abordando algumas de suas limitações atuais.
"Nossa abordagem proposta assume uma estimativa perfeita do estado do robô e emprega uma política puramente reativa, "os pesquisadores explicaram." Essas suposições e escolhas podem não ser ideais, especialmente para tarefas de longo alcance. Incorporar memória espacial ou visual para lidar com essas limitações seria direções futuras frutíferas. "
© 2019 Science X Network