Crédito:Prasad, Das &Bhowmick.
Pesquisadores do grupo Embedded Systems and Robotics da TCS Research &Innovation desenvolveram recentemente uma rede de profundidade de duas visões para inferir profundidade e movimento do ego a partir de sequências monoculares consecutivas. A abordagem deles, apresentado em um artigo pré-publicado no arXiv, também incorpora restrições epipolares, que aumentam a compreensão geométrica da rede.
"Nossa ideia principal era tentar prever a profundidade dos pixels e o movimento da câmera diretamente a partir de sequências de imagens individuais, "Dr. Brojeshwar Bhowmick, um dos pesquisadores que realizou o estudo, disse TechXplore. "Tradicionalmente, estrutura de algoritmos de reconstrução baseados em movimento fornecem saídas de profundidade esparsas para pontos de interesse salientes na imagem, que são rastreados em várias imagens usando a geometria de múltiplas visualizações. Com o aprendizado profundo ganhando popularidade em tarefas de visão computacional, pensamos em aproveitar os métodos existentes para ajudar nossa causa, abordando o problema de uma maneira mais fundamental, usando uma combinação de conceitos de geometria epipolar e aprendizado profundo. "
A maioria das abordagens existentes de aprendizado profundo para prever a profundidade monocular e o movimento do ego otimizam a consistência fotométrica em sequências de imagens, distorcendo uma visão em outra. Ao inferir a profundidade de uma única visão, Contudo, esses métodos podem falhar em capturar a relação entre pixels e, assim, fornecer correspondências de pixel adequadas.
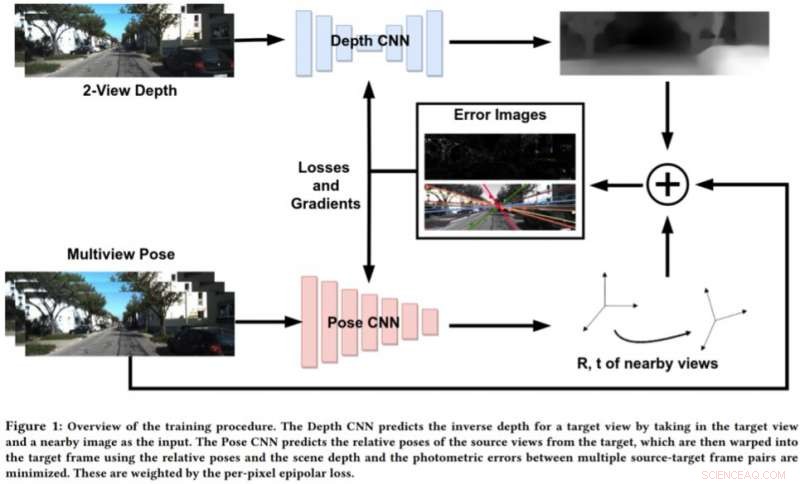
Para lidar com as limitações dessas abordagens, Bhowmick e seus colegas desenvolveram uma nova abordagem que combina visão computacional geométrica e paradigmas de aprendizado profundo. A abordagem deles usa duas redes neurais, um para prever a profundidade de uma única vista de referência e outro para prever as poses relativas de um conjunto de vistas em relação à vista de referência.

Crédito:Prasad, Das &Bhowmick.
"A cena da imagem alvo pode ser reconstruída a partir de qualquer uma das poses dadas, distorcendo-as com base na profundidade e nas poses relativas, "Bhowmick explicou." Dada esta imagem reconstruída e a imagem de referência, calculamos o erro nas intensidades de pixel, que atua como nossa principal perda. Adicionamos a novidade de usar a perda epipolar por pixel, um conceito de geometria multi-visão, na perda geral, que garante melhores correspondências e tem a vantagem adicional de descontar objetos em movimento na cena que podem deteriorar o aprendizado. "
Em vez de prever a profundidade analisando uma única imagem, essa nova abordagem funciona analisando um par de imagens de um vídeo e aprendendo as relações entre pixels para prever a profundidade. É algo semelhante aos algoritmos SLAM / SfM tradicionais, que pode observar os movimentos dos pixels ao longo do tempo.
"As descobertas mais significativas de nosso estudo são que usar duas visualizações para prever a profundidade funciona melhor do que uma única imagem, e que mesmo a aplicação fraca de correspondências de nível de pixel por meio de restrições epipolares funciona bem, "Bhowmick disse." Uma vez que esses métodos amadurecem e melhoram na generalização, poderíamos aplicá-los para percepção em drones, onde se deseja extrair o máximo de informação sensorial consumindo o mínimo de energia possível, que pode ser alcançado usando uma única câmera. "
Em avaliações preliminares, os pesquisadores descobriram que seu método pode prever profundidade com maior precisão do que as abordagens existentes, produzindo estimativas de profundidade mais nítidas e estimativas de pose aprimoradas. Contudo, Atualmente, sua abordagem só pode realizar inferências em nível de pixel. Trabalhos futuros podem resolver essa limitação integrando a semântica da cena ao modelo, o que pode levar a melhores correlações entre os objetos na cena e as estimativas de profundidade e de movimento do ego.
"Estamos investigando ainda mais a generalização desse método e de outros métodos semelhantes em várias cenas, tanto interno quanto externo, "Bhowmick disse." Atualmente, a maioria dos trabalhos tem um bom desempenho com dados externos, como dados de direção, mas tem um desempenho muito fraco em sequências internas com movimentos arbitrários. "
© 2019 Science X Network