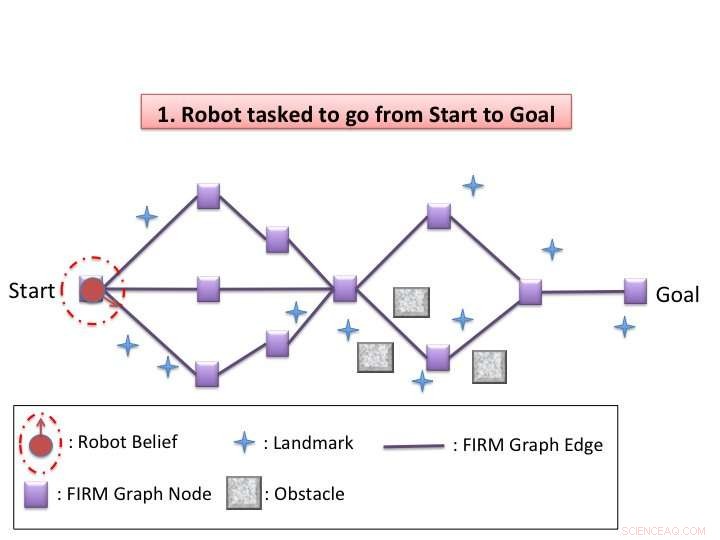
Ilustração do algoritmo. Crédito:Agha-mohammadi et al.
Pesquisadores do Laboratório de Propulsão a Jato da NASA (JPL), Texas A&M University, e a Carnegie Mellon University recentemente realizaram um projeto de pesquisa com o objetivo de habilitar os recursos de localização e planejamento simultâneos (SLAP) em robôs autônomos. Seu papel, publicado em Transações IEEE em robótica , apresenta um esquema de replanejamento dinâmico no espaço de crenças, o que pode ser particularmente útil para robôs operando sob incerteza, como em ambientes mutáveis.
"Robôs que operam no mundo real precisam lidar com a incerteza, "Sung Kyun Kim, um dos pesquisadores que realizaram o estudo disse ao TechXplore. "Por exemplo, um Mars rover é para navegar para locais de destino científicos, mas também precisa evitar a colisão com obstáculos. Assim, tanto a localização precisa quanto o planejamento de caminho com custo reduzido são recursos essenciais. "
SLAP é uma habilidade chave para robôs autônomos que operam sob incerteza, permitindo-lhes navegar efetivamente pelos espaços, evite obstáculos, e planeje seu caminho para os locais de destino. O processo de tomada de decisão sequencial de um robô sob incerteza pode ser formulado como um POMDP (processo de decisão de Markov parcialmente observável), que precisa ser continuamente resolvido online. Contudo, garantir que os robôs resolvam POMDPs com eficácia e precisão pode ser um desafio considerável.
"Tínhamos duas ideias principais para resolver problemas SLAP, "Kim explicou." Um é utilizar controladores de feedback para tornar um estado de crença acessível. Isso pode efetivamente quebrar a 'maldição da história, 'que nos ajuda a resolver problemas maiores. A outra é replanejar dinamicamente e melhorar a decisão em tempo de execução, aumentando a qualidade e robustez da solução. O replanejamento dinâmico é especialmente benéfico quando há erros de modelagem do sistema, mudanças dinâmicas de ambiente, ou falhas intermitentes do sensor / atuador. "

Exemplo do rover de Marte. Crédito:NASA / JPL-Caltech.
Kim e seus colegas conceberam um esquema de replanejamento dinâmico no espaço de crenças que permite aos robôs navegar efetivamente pelo espaço ao seu redor em situações de incerteza, como em ambientes variáveis ou quando confrontados com obstáculos inesperados. Seu algoritmo tem duas fases, offline e online.
“Na fase offline, nosso algoritmo constrói um gráfico esparso no espaço de crença com um controlador de feedback para cada nó e, em seguida, resolve a política global grosseira (decidindo que ação tomar no estado de crença atual) no gráfico, "Kim disse." Na fase online, o replanejamento dinâmico é conduzido toda vez que o estado de crença é atualizado. O algoritmo avalia localmente cada ação de mover para um nó próximo no gráfico e seleciona aquele com o custo mínimo. Depois de executar a ação selecionada e atualizar a crença atual, ele repete o processo de replanejamento. "
O esquema desenvolvido por Kim e seus colegas explora o comportamento dos controladores de feedback no espaço de crenças. Em outras palavras, controladores de feedback atuam como um funil no espaço de crença, com um estado de crença próximo potencialmente convergindo com o estado de crença alvo de controle. Isso efetivamente aborda uma questão-chave na solução de POMPDs - complexidade exponencial no horizonte de planejamento.
Na verdade, uma vez que a crença atual do algoritmo converge com uma crença conhecida, não há necessidade de considerar ações e observações que levem à crença atual. Em última análise, isso leva a uma melhor escalabilidade, permitindo que os robôs resolvam problemas de navegação mais complexos.
Exemplo do rover de Marte. Crédito:NASA / JPL-Caltech / MSSS.
"Durante o replanejamento dinâmico, o método proposto inicializa a otimização local com a política global (grosseira), "Disse Kim." Isso significa que pode tomar uma decisão não míope, ao contrário de outros planejadores online com um horizonte de recuo finito. Resumidamente, este método pode se adaptar a mudanças dinâmicas no ambiente e operar de forma robusta, apesar de uma perturbação ou erros não modelados, ao fazer planos de baixo custo no sentido global. "
Ao eliminar etapas de estabilização desnecessárias, o método desenvolvido por Kim e seus colegas superou o roteiro de informações com base em feedback (FIRM), uma técnica de última geração para resolver POMDPs. No futuro, este esquema de replanejamento dinâmico no espaço de crenças poderia permitir melhores recursos SLAP em robôs operando sob vários graus de incerteza.
"Agora planejamos aplicar nosso método a problemas do mundo real, "Kim disse." Uma aplicação possível é um protótipo de navegação e coordenação de helicópteros rover de Marte para exploração planetária, um projeto liderado pelo Dr. Ali-akbar Agha-mohammadi no JPL. Um helicóptero voando sobre o terreno pode fornecer um mapa aproximado para que uma política global grosseira possa ser obtida na fase off-line. Subseqüentemente, um rover iria replanejar dinamicamente na fase online, para realizar missões de navegação seguras e econômicas. "
© 2018 Tech Xplore














