Berkeley Lab, Intel, Cray aproveita o poder do aprendizado profundo para estudar o universo
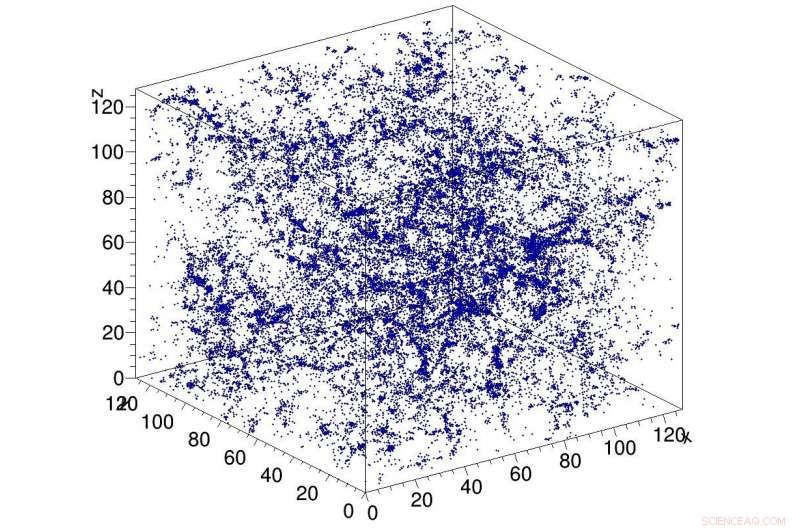 p Exemplo de simulação de matéria escura no universo, usado como entrada para a rede CosmoFlow. CosmoFlow é o primeiro aplicativo científico em grande escala a usar a estrutura TensorFlow em uma plataforma de computação de alto desempenho baseada em CPU com treinamento síncrono. Crédito:Laboratório Nacional Lawrence Berkeley
p Exemplo de simulação de matéria escura no universo, usado como entrada para a rede CosmoFlow. CosmoFlow é o primeiro aplicativo científico em grande escala a usar a estrutura TensorFlow em uma plataforma de computação de alto desempenho baseada em CPU com treinamento síncrono. Crédito:Laboratório Nacional Lawrence Berkeley
p Uma colaboração de Big Data Center entre cientistas computacionais do Lawrence Berkeley National Laboratory (Berkeley Lab) do National Energy Research Scientific Computing Center (NERSC) e engenheiros da Intel e Cray resultou em outra inovação na busca de aplicar o aprendizado profundo à ciência intensiva de dados:CosmoFlow , o primeiro aplicativo científico em grande escala a usar a estrutura TensorFlow em uma plataforma de computação de alto desempenho baseada em CPU com treinamento síncrono. É também o primeiro a processar volumes de dados espaciais tridimensionais (3-D) nesta escala, dando aos cientistas uma plataforma inteiramente nova para obter uma compreensão mais profunda do universo. p Os problemas cosmológicos de "big data" vão além do simples volume de dados armazenados em disco. As observações do universo são necessariamente finitas, e o desafio que os pesquisadores enfrentam é como extrair o máximo de informações das observações e simulações disponíveis. Para agravar a questão, os cosmologistas normalmente caracterizam a distribuição da matéria no universo usando medidas estatísticas da estrutura da matéria na forma de funções de dois ou três pontos ou outras estatísticas reduzidas. Métodos como o aprendizado profundo, que podem capturar todas as características na distribuição da matéria, forneceriam uma maior compreensão da natureza da energia escura. Os primeiros a perceber que o aprendizado profundo poderia ser aplicado a este problema foram Siamak Ravanbakhsh e seus colegas, conforme referenciado nos anais da 33ª Conferência Internacional sobre Aprendizado de Máquina. Contudo, gargalos computacionais durante a ampliação da rede e do conjunto de dados limitaram o escopo do problema que poderia ser resolvido.
p Motivado para enfrentar esses desafios, CosmoFlow foi projetado para ser altamente escalável; para processar grandes, Conjuntos de dados de cosmologia 3-D; e para melhorar o desempenho do treinamento de aprendizado profundo em supercomputadores HPC modernos, como o supercomputador Cray XC40 Cori baseado no processador Intel no NERSC. O CosmoFlow é baseado na popular estrutura de aprendizado de máquina TensorFlow e usa Python como front end. O aplicativo aproveita o Cray PE Machine Learning Plugin para alcançar o dimensionamento sem precedentes da estrutura TensorFlow Deep Learning para mais de 8, 000 nós. Ele também se beneficia da tecnologia de acelerador DataWarp I / O da Cray, que fornece a taxa de transferência de E / S necessária para atingir esse nível de escalabilidade.
p Em um artigo técnico a ser apresentado no SC18 em novembro, a equipe do CosmoFlow descreve a aplicação e os experimentos iniciais usando simulações de corpos N de matéria escura produzidas usando os pacotes MUSIC e pycola no supercomputador Cori no NERSC. Em uma série de experimentos de escalonamento de nó único e vários nós, a equipe foi capaz de demonstrar treinamento paralelo de dados totalmente síncrono em 8, 192 de Cori com 77% de eficiência paralela e 3,5 Pflop / s de desempenho sustentado.
p "Nosso objetivo era demonstrar que o TensorFlow pode ser executado em escala em vários nós de forma eficiente, "disse Deborah Bard, arquiteto de big data no NERSC e co-autor do artigo técnico. "Até onde sabemos, esta é a maior implantação do TensorFlow em CPUs, e achamos que é a maior tentativa de executar o TensorFlow no maior número de nós de CPU. "
p Logo no início, a equipe do CosmoFlow definiu três objetivos principais para este projeto:ciência, otimização e escalonamento de um único nó. O objetivo da ciência era demonstrar que o aprendizado profundo pode ser usado em volumes 3-D para aprender a física do universo. A equipe também queria garantir que o TensorFlow fosse executado com eficiência e eficácia em um único nó do processador Intel Xeon Phi com volumes 3-D, que são comuns na ciência, mas não tanto na indústria, onde a maioria dos aplicativos de aprendizado profundo lidam com conjuntos de dados de imagem 2-D. E finalmente, garantem alta eficiência e desempenho quando dimensionados em 1000 nós no sistema de supercomputador Cori.
p Como Joe Curley, Diretor sênior da Organização de Modernização de Código no Grupo de Data Center da Intel, observado, "A colaboração do Big Data Center produziu resultados surpreendentes em ciência da computação por meio da combinação da tecnologia Intel e esforços dedicados de otimização de software. Durante o projeto CosmoFlow, identificamos a estrutura, otimização de kernel e comunicação que levou a um aumento de desempenho de mais de 750x para um único nó. Igualmente impressionante, a equipe resolveu problemas que limitavam o dimensionamento das técnicas de aprendizado profundo para 128 a 256 nós - para agora permitir que o aplicativo CosmoFlow seja dimensionado de forma eficiente para 8, 192 nós do supercomputador Cori no NERSC. "
p "Estamos entusiasmados com os resultados e os avanços em aplicativos de inteligência artificial a partir deste projeto colaborativo com NERSC e Intel, "disse Per Nyberg, vice-presidente de desenvolvimento de mercado, inteligência artificial e nuvem na Cray. "É empolgante ver a equipe CosmoFlow aproveitar as vantagens da tecnologia exclusiva da Cray e alavancar o poder de um supercomputador Cray para dimensionar efetivamente os modelos de aprendizagem profunda. É um grande exemplo do que muitos de nossos clientes estão se esforçando para convergir a modelagem tradicional e simulação com novos algoritmos de análise e aprendizagem profunda, tudo em um único, plataforma escalável. "
p Prabhat, Líder do Grupo de Serviços de Dados e Análise da NERSC, adicionado, "Do meu ponto de vista, CosmoFlow é um projeto exemplar para a colaboração de Big Data Center. Nós realmente alavancamos as competências de várias instituições para resolver um problema científico difícil e melhorar nossa pilha de produção, o que pode beneficiar a comunidade mais ampla de usuários do NERSC. "
p Além de Bard e Prabhat, os co-autores do artigo SC18 incluem Amrita Mathuriya, Lawrence Meadows, Lei Shao, Tuomas Karna, John Pennycook, Jason Sewall, Nalini Kumar e Victor Lee da Intel; Peter Mendygral, Diana Moise, Kristyn Maschhoff e Michael Ringenburg de Cray; Siyu He e Shirley Ho, do Flatiron Institute; e James Arnemann da UC Berkeley.