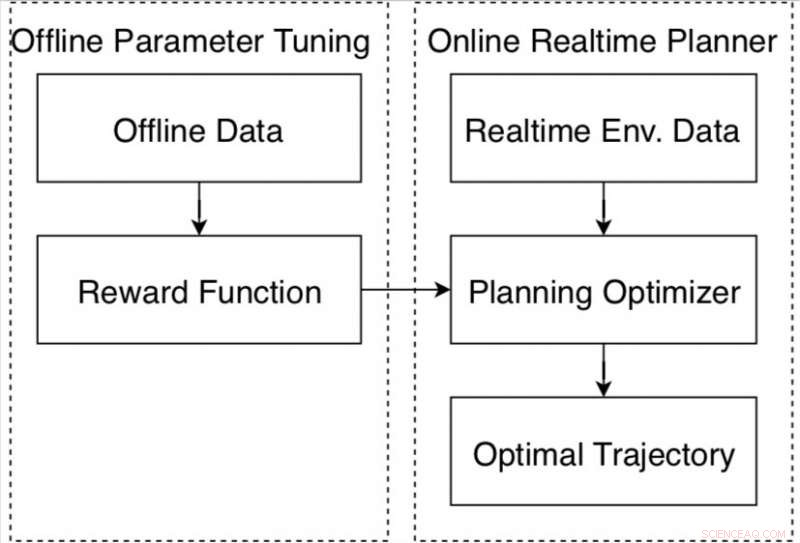
Planejador de movimento de direção autônomo baseado em dados na plataforma Apollo. Crédito:Fan et al.
Pesquisadores da empresa multinacional chinesa de tecnologia Baidu desenvolveram recentemente uma estrutura de autoajuste orientada a dados para veículos autônomos com base na plataforma de direção autônoma Apollo. O quadro, apresentado em um artigo pré-publicado no arXiv, consiste em um novo algoritmo de aprendizagem por reforço e uma estratégia de treinamento offline, bem como um método automático de coleta e rotulagem de dados.
Um planejador de movimento para direção autônoma é um sistema projetado para gerar uma trajetória segura e confortável para chegar ao destino desejado. Projetar e ajustar esses sistemas para garantir que tenham um bom desempenho em diferentes condições de direção é uma tarefa difícil que várias empresas e pesquisadores em todo o mundo estão tentando enfrentar.
"O planejamento de movimento para carros de direção autônoma tem muitos problemas desafiadores, "Fan Haoyang, um dos pesquisadores que realizou o estudo, disse Tech Xplore. "Um dos principais desafios é que ele tem que lidar com milhares de cenários diferentes. Normalmente, definimos um ajuste funcional de recompensa / custo que pode adaptar essas diferenças nos cenários. Contudo, achamos que é uma tarefa difícil. "
Tipicamente, o ajuste funcional de custo-recompensa requer um extenso trabalho em nome dos pesquisadores, bem como recursos e tempo gasto em simulações e testes de estrada. Além disso, o ambiente pode mudar drasticamente ao longo do tempo e conforme as condições de direção se tornam mais complicadas, ajustar o desempenho do planejador de movimento torna-se cada vez mais difícil.

Loop de ajuste de algoritmo para o planejador de movimento na plataforma de direção autônoma Apollo. Crédito:Fan et al.
"Para resolver sistematicamente este problema, desenvolvemos uma estrutura de ajuste automático orientado por dados com base na estrutura de direção autônoma Apollo, "Fan disse." A ideia do auto-ajuste é aprender os parâmetros de dados de direção demonstrados por humanos. Por exemplo, gostaríamos de entender, a partir dos dados, como os motoristas humanos equilibram a velocidade e a conveniência de dirigir com as distâncias de obstáculos. Mas em cenários mais complicados, por exemplo, uma cidade lotada, o que podemos aprender com os motoristas humanos? "
A estrutura de autoajuste desenvolvida no Baidu inclui um novo algoritmo de aprendizagem por reforço, que pode aprender com os dados e melhorar seu desempenho ao longo do tempo. Em comparação com a maioria dos algoritmos de aprendizagem por reforço inverso, pode ser aplicado com eficácia a diferentes cenários de direção.
A estrutura também inclui uma estratégia de treinamento offline, oferecendo uma maneira segura para os pesquisadores ajustarem os parâmetros antes que um veículo autônomo seja testado em vias públicas. Ele também coleta dados de motoristas especializados e informações sobre o ambiente, rotulando-os automaticamente para que possam ser analisados pelo algoritmo de aprendizagem por reforço.
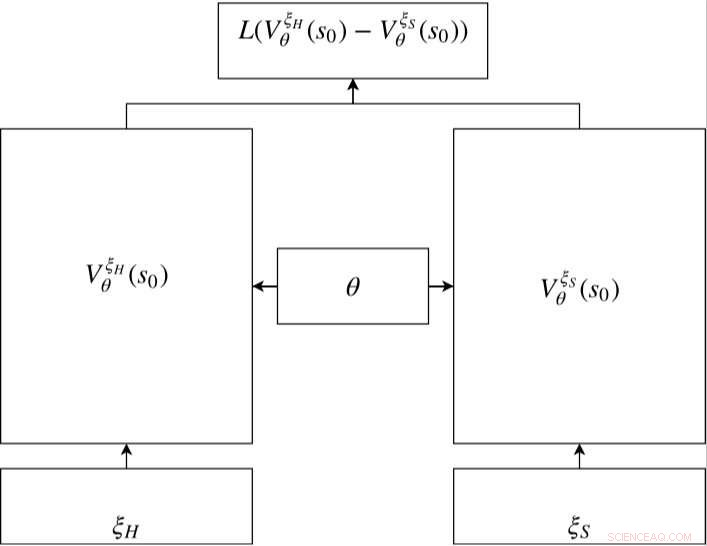
Rede siamesa em RC-IRL. As redes de valor das trajetórias humanas e amostradas compartilham as mesmas configurações de parâmetros de rede. A função de perda avalia a diferença entre os dados amostrados e a trajetória gerada por meio das saídas da rede de valor. Crédito:Fan et al.
"Acho que desenvolvemos um pipeline seguro para tornar um sistema escalonável de aprendizado de máquina usando dados de demonstração humana, "Fan disse." Os dados de demonstração humana de loop aberto são coletados e não precisam de rotulagem extra. Uma vez que o processo de treinamento também é offline, nosso método é adequado para planejamento de movimento de direção autônomo, mantendo a segurança do teste rodoviário público. "
Os pesquisadores avaliaram um planejador de movimento ajustado usando sua estrutura tanto em simulações quanto em testes de estradas públicas. Em comparação com as abordagens existentes, seu método baseado em dados foi mais capaz de se adaptar a diferentes cenários de direção, desempenho consistentemente bom sob uma variedade de condições.
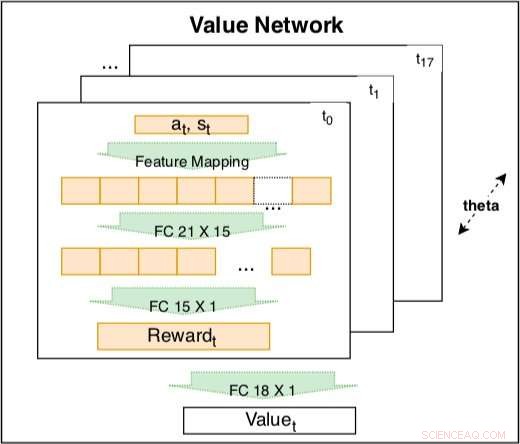
A rede de valor dentro do modelo siamês é usada para capturar o comportamento de direção com base em recursos codificados. A rede é uma combinação linear treinável de recompensas codificadas em diferentes tempos t =t0, ..., t17. O peso da recompensa codificada é um fator de redução de tempo que pode ser aprendido. A recompensa codificada inclui uma camada de entrada com 21 recursos brutos e uma camada oculta com 15 nós para cobrir possíveis interações. Os parâmetros da recompensa em momentos diferentes compartilham o mesmo θ para manter a consistência. Crédito:Fan et al.
"Nossa pesquisa é baseada na plataforma Baidu Apollo Open Source Autonomous Driving, "Fan disse." Esperamos que mais e mais pessoas da academia e da indústria possam contribuir para o ecossistema de direção autônoma por meio da Apollo. No futuro, planejamos melhorar a estrutura atual do Baidu Apollo para um sistema escalonável de aprendizado de máquina que pode melhorar sistematicamente a cobertura do cenário de carros autônomos. "
© 2018 Tech Xplore