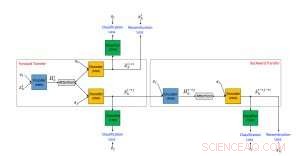
Estrutura proposta de um algoritmo de transferência de estilo de texto neural usando dados não paralelos. Crédito:IBM
A mídia social online se tornou uma das formas mais importantes de se comunicar e trocar ideias. Infelizmente, o discurso é frequentemente prejudicado por linguagem abusiva que pode ter efeitos prejudiciais para os usuários das redes sociais. Por exemplo, uma pesquisa recente do YouGov.uk descobriu que, entre as informações que os empregadores podem encontrar online sobre candidatos a empregos, linguagem agressiva ou ofensiva é a atividade de mídia social que mais prejudica profissionalmente. As redes de mídia social online normalmente lidam com o problema de linguagem ofensiva simplesmente filtrando uma postagem quando ela é sinalizada como ofensiva.
No artigo "Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer, "que foi apresentado na 56ª Reunião Anual da Association for Computational Linguistics (ACL 2018), introduzimos uma abordagem completamente nova para lidar com esse problema. Nossa abordagem usa a transferência não supervisionada de estilo de texto para traduzir frases ofensivas em formas não ofensivas correspondentes. Para o melhor de nosso conhecimento, todos os trabalhos anteriores abordando o problema da linguagem ofensiva nas redes sociais focalizaram apenas a classificação do texto. Esses métodos podem, portanto, ser usados principalmente para sinalizar e filtrar o conteúdo ofensivo, mas nossa abordagem proposta vai um passo à frente e produz uma versão alternativa não ofensiva do conteúdo. Isso tem dois benefícios potenciais para usuários de mídia social. Para os usuários que planejam postar uma mensagem ofensiva, receber um alerta de que o conteúdo é ofensivo e será bloqueado, junto com uma versão mais educada da mensagem que pode ser postada, pode encorajá-los a mudar de ideia e evitar palavrões. Adicionalmente, para usuários que consomem conteúdo online, isso permite que eles ainda vejam e entendam a mensagem, mas em um tom educado e não ofensivo.
Uma arquitetura para substituir a linguagem ofensiva
Nosso método é baseado na agora popular arquitetura de rede neural codificador-decodificador, que é a abordagem de última geração para tradução automática. Na tradução automática, o treinamento de rede neural codificador-decodificador pressupõe a existência de uma "Pedra de Roseta", onde o mesmo texto é escrito nas línguas de origem e de destino. Esses dados emparelhados permitem que os desenvolvedores determinem facilmente se um sistema traduz corretamente e, portanto, treinem um sistema codificador-decodificador para ter um bom desempenho. Infelizmente, ao contrário da tradução automática, até onde sabemos, não existe nenhum conjunto de dados pareados disponível para o caso de sentenças ofensivas a não ofensivas. Além disso, o texto transferido deve usar um vocabulário comum em um domínio de aplicativo específico. Portanto, métodos não supervisionados que não usam dados emparelhados são necessários para executar esta tarefa.

Propusemos uma abordagem de transferência de estilo de texto não supervisionada composta de três componentes principais, cada um recebe uma tarefa separada durante o treinamento. Um (um codificador RNN) analisa uma frase ofensiva e compacta as informações mais relevantes em um vetor de valor real. Isso é lido por outro componente (um decodificador RNN), que gera uma nova frase que é a versão traduzida da original. A frase traduzida é então avaliada pelo terceiro componente (um classificador da CNN) para identificar se a saída foi traduzida corretamente do estilo ofensivo para o não ofensivo. Adicionalmente, a frase gerada também é "retrotraduzida" de não ofensiva para ofensiva e comparada com a frase original para verificar se o conteúdo foi preservado. Se os resultados de qualquer uma das avaliações acima contiverem erros, o sistema é ajustado em conformidade. O codificador e o decodificador também são, em paralelo, treinado usando uma configuração de codificação automática onde o objetivo consiste em reconstruir a frase de entrada. Também utilizamos o mecanismo de atenção que ajuda a garantir a preservação do conteúdo. Nossa principal contribuição em termos de arquitetura é o uso combinado de um classificador colaborativo, atenção, e transferência de volta.
Traduzindo linguagem ofensiva
Testamos nosso método proposto usando dados de duas redes sociais populares:Twitter e Reddit. Criamos conjuntos de dados de textos ofensivos e não ofensivos, classificando aproximadamente 10 milhões de postagens usando um classificador de linguagem ofensiva proposto por Davidson et al. (2017). A tabela a seguir mostra exemplos de sentenças ofensivas originais e as traduções não ofensivas geradas por um método de transferência de estilo de texto proposto por Shen et al. (2017) e por nossa abordagem. Nosso sistema demonstrou melhor desempenho na tradução de frases ofensivas em não ofensivas, preservando o conteúdo geral, mas às vezes produz frases estranhas.
Este trabalho é um primeiro passo na direção de uma nova abordagem promissora para combater postagens abusivas nas redes sociais. A transferência não supervisionada de estilo de texto é uma área de pesquisa que apenas começou a ver alguns resultados promissores. Nosso trabalho é uma boa prova de conceito de que os métodos atuais de transferência de estilo de texto não supervisionado podem ser aplicados a tarefas úteis. Contudo, é importante notar que as abordagens atuais de transferência não supervisionada de estilo de texto podem lidar bem apenas com os casos em que o problema de linguagem ofensiva é lexical (como os exemplos mostrados na tabela) e pode ser resolvido alterando ou removendo algumas palavras. Os modelos que usamos não serão eficazes em casos de viés implícito, onde palavras normalmente inofensivas são usadas de forma ofensiva.
Acreditamos que versões melhoradas do método proposto, junto com o uso de volumes muito maiores de dados de treinamento, será capaz de lidar com outras postagens abusivas, como postagens contendo discurso de ódio, racismo, e sexismo. Imaginamos que nosso método poderia ser usado para melhorar a IA de conversação, garantindo que os chatbots que aprendem interagindo com usuários on-line não reproduzirão posteriormente linguagem ofensiva e discurso de ódio. O controle dos pais é outro uso potencial do sistema proposto.
Esta história foi republicada por cortesia da IBM Research.