As previsões de sons foram alcançadas por um método aprimorado desenvolvido por uma equipe internacional de pesquisadores. Crédito: IEEE / CAA Journal of Automatica Sinica
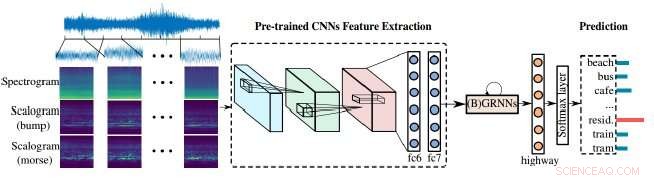
Os pesquisadores demonstraram um método aprimorado para que as máquinas de análise de áudio processem nosso mundo barulhento. Sua abordagem depende da combinação de escalogramas e espectrogramas - as representações visuais de áudio - bem como redes neurais convolucionais (CNNs), as máquinas de ferramentas de aprendizagem usam para analisar melhor as imagens visuais. Nesse caso, as imagens visuais são usadas para analisar o áudio para melhor identificar e classificar o som.
A equipe publicou seus resultados no jornal IEEE / CAA Journal of Automatica Sinica ( JAS ), uma publicação conjunta do IEEE e da Associação Chinesa de Automação.
"As máquinas fizeram um grande progresso na análise da fala e da música, mas a análise geral de som tem ficado para trás - normalmente, a maioria dos "eventos" de som isolados, como tiros de arma de fogo e similares, foram alvejados no passado, "disse Björn Schuller, professor e presidente de Embedded Intelligence for Health Care and Wellbeing na University of Augsburg, na Alemanha, quem liderou a pesquisa. "O áudio do mundo real geralmente é uma mistura altamente combinada de diferentes fontes de som - cada uma com diferentes estados e características."
Schuller cita o som de um carro como exemplo. Não é um evento de áudio único; bastante diferentes partes das peças do carro, seus pneus interagindo com a estrada, a marca e a velocidade do carro fornecem suas próprias assinaturas exclusivas.
"Ao mesmo tempo, pode haver música ou fala no carro, "disse Schuller, que também é professor associado de aprendizado de máquina no Imperial College London, e um professor visitante na Escola de Ciência da Computação e Tecnologia do Harbin Institute of Technology na China. "Uma vez que os computadores podem entender todas as partes desta 'cena acústica', eles serão consideravelmente melhores em decompor em cada parte e atribuir cada parte conforme descrito. "
Os espectrogramas fornecem uma representação visual de cenas de áudio, mas eles têm uma resolução fixa de tempo e frequência, esse é o momento em que as frequências mudam. Escalogramas, por outro lado, oferecem uma representação visual mais detalhada de cenas acústicas do que espectrogramas, por exemplo, Agora, cenas acústicas como a música ou a fala ou outros sons no carro podem ser melhor representadas.
"Normalmente, há vários sons acontecendo em uma cena, então ... deve haver várias frequências e elas mudam com o tempo, "disse Zhao Ren, um autor no artigo e um Ph.D. candidato da Universidade de Augsburg que trabalha com Schuller. "Felizmente, os escalogramas podem resolver esse problema exatamente porque incorpora várias escalas. "
"Os escalogramas podem ser empregados para ajudar os espectrogramas na extração de recursos para classificação de cena acústica, "Ren disse, e tanto os espectrogramas quanto os escalogramas precisam ser capazes de aprender para continuar melhorando.
"Avançar, redes neurais pré-treinadas constroem uma ponte entre [a] imagem e o processamento de áudio. "
As redes neurais pré-treinadas que os autores usaram são Redes Neurais Convolucionais (CNNs). CNNs são inspirados em como os neurônios funcionam no córtex visual dos animais e as redes neurais artificiais podem ser usadas para processar imagens visuais com sucesso. Essas redes são cruciais no aprendizado de máquina, e neste caso, ajudando a melhorar os escalogramas.
CNNs recebem algum treinamento antes de serem aplicados em uma cena, mas eles aprendem principalmente com a exposição. Ao aprender sons de uma combinação de diferentes frequências e escalas, o algoritmo pode prever melhor as fontes e, eventualmente, prever o resultado de um ruído incomum, como o mau funcionamento do motor de um carro.
"O objetivo final é ouvir / escutar por máquina de maneira holística ... através da fala, música, e soar exatamente como um ser humano faria, "Schuller disse, observando que isso se combinaria com o trabalho já avançado em análise de fala para fornecer uma compreensão mais rica e profunda, "para, então, ser capaz de obter 'a imagem completa' no áudio."