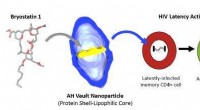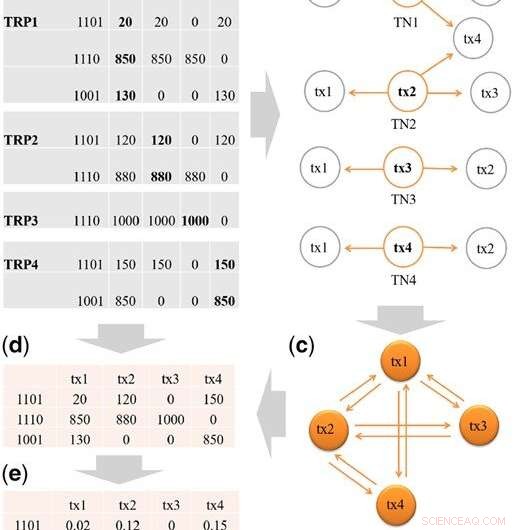
Passos para construir a matriz de design inicial X. (a) TRPs de tx1, tx2, tx3 e tx4, e o resumo dos padrões de ocupação binários dos TRPs. A transcrição tx5 não passa na filtragem (H =2,5%) e é filtrada de TRP1. Em cada padrão binário, dígito 1 significa que há leituras originadas de uma eqclass, e 0 caso contrário. Por exemplo, existem três eqclasses em TRP1:eqclass1, eqclass2 e eqclass3. Para eq1, o padrão binário é 1101, o que significa três transcrições, ou seja, tx1, tx2 e tx4 têm leituras de eq1. (b) Vizinhos da transcrição (TNs) para tx1 a tx4. (c) Ilustração da construção do cluster de transcrição (TC) dos TNs. Primeiro, coletamos os TNs de tx1, tx2, tx3 e tx4, e, em seguida, adicione as conexões entre as transcrições no TC. Por exemplo, da TN1, adicionamos a conexão de tx1-tx2, tx1-tx3 e tx1-tx4. No fim, um TC conteria todas as conexões entre as transcrições que compartilham exons. (d) O conjunto único de padrões binários é mantido, portanto, três padrões únicos permanecem:1101, 1001, 1110. Em seguida, preenchemos as contagens de leitura de cada TRP de origem. Por exemplo, para o padrão 1101, em TRP1, a contagem de leitura é 20 para tx1, em TRP2, a contagem de leitura é 120 para tx2 e em TRP4 a contagem de leitura é 150 para tx4. (e) As leituras totais de cada transcrição em (d) são padronizadas para somar 1 para criar a matriz de design inicial X. Crédito:DOI:10.1093 / bioinformática / btz640
A tecnologia de ômicas de alto rendimento revolucionou a pesquisa biológica e biomédica e grandes volumes de dados ômicos foram produzidos. Por esta, ferramentas computacionais para gerenciar e analisar os dados ômicos foram desenvolvidas e existem grandes desafios em como processar e interpretar os dados ômicos da melhor maneira. Wenjiang Deng trabalhou para desenvolver novas metodologias estatísticas e algoritmos para análise de dados ômicos, usando dados de câncer simulados e reais para testar os métodos.
Você poderia descrever alguns dos resultados de sua tese?
Sim, no meu primeiro estudo, identificamos vários genes associados à sobrevivência de pacientes com neuroblastoma de alto risco, diz Wenjiang Deng, Ph.D. estudante do Departamento de epidemiologia médica e bioestatística, MEB. O neuroblastoma é o câncer mais comum e mortal em crianças menores de cinco anos. Acreditamos que nossas descobertas fornecerão evidências significativas para o tratamento e gerenciamento de pacientes. Nossos resultados também podem ser significativos para entender os mecanismos fisiológicos da doença.
Por que você escolheu estudar esta área em particular?
Estamos vivendo na era do "big data, "e os dados de sequenciamento de alto rendimento são os" big data "predominantes nas ciências da vida. Quando ouvi pela primeira vez o conceito de dados ômicos, Fiquei surpreso com seu enorme volume e o grande potencial da pesquisa médica. Hoje em dia é muito fácil produzir dados de sequenciamento, mas ainda precisamos de ferramentas eficientes e precisas para analisá-los, então decidi estudar o desenvolvimento de algoritmos durante meu tempo como doutorado. estudante.
O que você fará em seguida?
Depois da minha defesa, Vou ficar no MEB por um tempo para encerrar meus manuscritos. Eu irei então para Shenzhen, China, e começar a trabalhar em uma empresa de biotecnologia que visa desenvolver novos métodos para o diagnóstico precoce de cânceres. Espero que nosso trabalho lá contribua para a saúde geral dos seres humanos.