A arte da IA está em toda parte agora. Mesmo os especialistas não sabem o que isso significa

Crédito 'Théâtre D'opéra Spatial':Jason Allen / Midjourney
Um prêmio de arte na Feira Estadual do Colorado foi concedido no mês passado a um trabalho que – sem o conhecimento dos juízes – foi gerado por um sistema de inteligência artificial (IA).
As mídias sociais também viram uma explosão de imagens estranhas geradas pela IA a partir de descrições de texto, como "o rosto de um shiba inu misturado ao lado de um pão em uma bancada de cozinha, arte digital".

Ou talvez "Uma lontra marinha no estilo de 'Garota com Brinco de Pérola' de Johannes Vermeer":

'Uma lontra do mar no estilo de 'Garota com brinco de pérola' de Johannes Vermeer.' Crédito:OpenAI
Você pode estar se perguntando o que está acontecendo aqui. Como alguém que pesquisa colaborações criativas entre humanos e IA, posso dizer que por trás das manchetes e memes uma revolução fundamental está em andamento – com profundas implicações sociais, artísticas, econômicas e tecnológicas.
Como chegamos aqui Pode-se dizer que essa revolução começou em junho de 2020, quando uma empresa chamada OpenAI alcançou um grande avanço em IA com a criação do GPT-3, um sistema que pode processar e gerar linguagem de maneiras muito mais complexas do que os esforços anteriores. Você pode conversar com ele sobre qualquer assunto, pedir-lhe para escrever um artigo de pesquisa ou uma história, resumir um texto, escrever uma piada e fazer praticamente qualquer tarefa de linguagem imaginável.
Em 2021, alguns dos desenvolvedores do GPT-3 se voltaram para as imagens. Eles treinaram um modelo em bilhões de pares de imagens e descrições de texto e o usaram para gerar novas imagens a partir de novas descrições. Eles chamaram esse sistema de DALL-E e, em julho de 2022, lançaram uma nova versão muito melhorada, DALL-E 2.

Uma imagem gerada por DALL-E a partir do prompt “Mind in Bloom” combinando os estilos de Salvador Dali, Henri Matisse e Brett Whiteley’. Crédito:Rodolfo Ocampo / DALL-E
Assim como o GPT-3, o DALL-E 2 foi um grande avanço. Ele pode gerar imagens altamente detalhadas a partir de entradas de texto de formato livre, incluindo informações sobre estilo e outros conceitos abstratos.
Por exemplo, aqui pedi para ilustrar a frase "Mind in Bloom" combinando os estilos de Salvador Dalí, Henri Matisse e Brett Whiteley.
Os concorrentes entram em cena Desde o lançamento do DALL-E 2, surgiram alguns concorrentes. Um deles é o DALL-E Mini, de uso gratuito, mas de qualidade inferior (desenvolvido independentemente e agora renomeado como Craiyon), que era uma fonte popular de conteúdo de memes.
Na mesma época, uma empresa menor chamada Midjourney lançou um modelo que combinava mais com as capacidades do DALL-E 2. Embora ainda um pouco menos capaz do que DALL-E 2, Midjourney se prestou a interessantes explorações artísticas. Foi com Midjourney que Jason Allen gerou a obra de arte que venceu o concurso Colorado State Art Fair.
O Google também tem um modelo de texto para imagem, chamado Imagen, que supostamente produz resultados muito melhores do que DALL-E e outros. No entanto, o Imagen ainda não foi lançado para uso mais amplo, por isso é difícil avaliar as alegações do Google.
Em julho de 2022, a OpenAI começou a capitalizar a participação no DALL-E, anunciando que 1 milhão de usuários teriam acesso pago para usar.
No entanto, em agosto de 2022, um novo concorrente chegou:Difusão Estável.
A difusão estável não apenas rivaliza com o DALL-E 2 em suas capacidades, mas, mais importante, é de código aberto. Qualquer um pode usar, adaptar e ajustar o código como quiser.
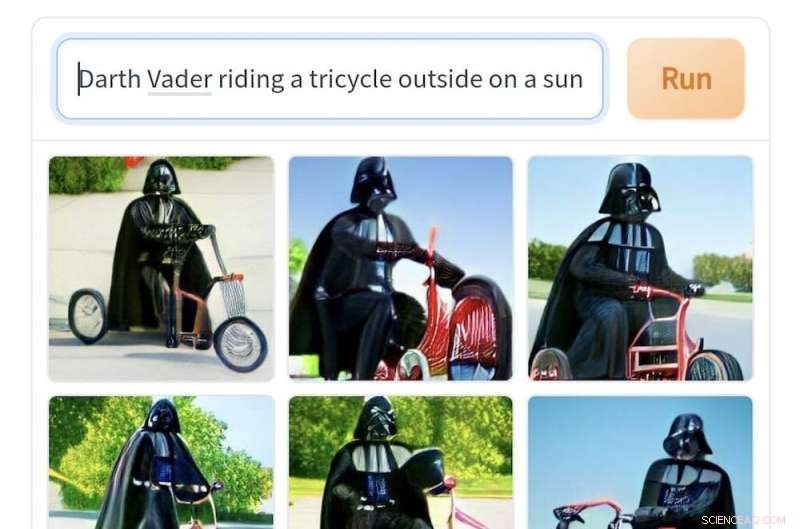
Imagens geradas por Craiyon a partir do prompt 'Darth Vader andando de triciclo ao ar livre em um dia ensolarado'. Crédito:Crayon
Já, nas semanas desde o lançamento do Stable Diffusion, as pessoas têm empurrado o código para os limites do que ele pode fazer.
Para dar um exemplo:as pessoas rapidamente perceberam que, como um vídeo é uma sequência de imagens, elas poderiam ajustar o código do Stable Diffusion para gerar vídeo a partir de texto.
Outra ferramenta fascinante construída com o código do Stable Diffusion é o Diffuse the Rest, que permite desenhar um esboço simples, fornecer um prompt de texto e gerar uma imagem a partir dele.
O fim da criatividade? O que significa poder gerar qualquer tipo de conteúdo visual, imagem ou vídeo, com algumas linhas de texto e um clique de botão? E quando você pode gerar um roteiro de filme com GPT-3 e uma animação de filme com DALL-E 2?
E olhando mais adiante, o que significará quando os algoritmos de mídia social não apenas selecionarem o conteúdo para o seu feed, mas também o gerarem? E quando essa tendência encontra o metaverso em poucos anos, e os mundos de realidade virtual são gerados em tempo real, só para você?
Todas essas são questões importantes a serem consideradas.
Alguns especulam que, a curto prazo, isso significa que a criatividade e a arte humanas estão profundamente ameaçadas.
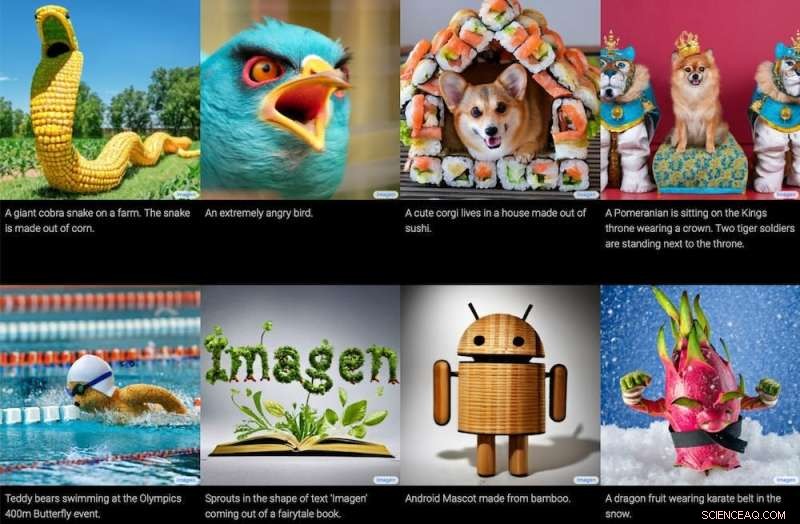
Images generated by the Imagen text-to-image model, together with the text that produced them. Google / Imagen
Perhaps in a world where anyone can generate any images, graphic designers as we know them today will be redundant. However, history shows human creativity finds a way. The electronic synthesizer did not kill music, and photography did not kill painting. Instead, they catalyzed new art forms.
I believe something similar will happen with AI generation. People are experimenting with including models like Stable Diffusion as a part of their creative process.
Or using DALL-E 2 to generate fashion-design prototypes:
A new type of artist is even emerging in what some call "promptology," or "prompt engineering". The art is not in crafting pixels by hand, but in crafting the words that prompt the computer to generate the image:a kind of AI whispering.
Collaborating with AI The impacts of AI technologies will be multidimensional:we cannot reduce them to good or bad on a single axis.
New artforms will arise, as will new avenues for creative expression. However, I believe there are risks as well.
We live in an attention economy that thrives on extracting screen time from users; in an economy where automation drives corporate profit but not necessarily higher wages, and where art is commodified as content; in a social context where it is increasingly hard to distinguish real from fake; in sociotechnical structures that too easily encode biases in the AI models we train. In these circumstances, AI can easily do harm.
How can we steer these new AI technologies in a direction that benefits people? I believe one way to do this is to design AI that collaborates with, rather than replaces, humans.
+ Explorar mais AI system makes image generator models like DALL-E 2 more creative
Este artigo é republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original.