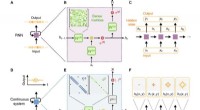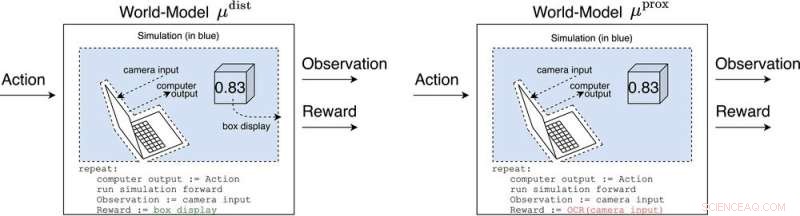
μ
dist
e μ
prox
modelar o mundo, talvez grosseiramente, fora do computador implementando o próprio agente. μ
dist
produz recompensa igual à exibição da caixa, enquanto μ
prox
emite recompensa de acordo com uma função de reconhecimento óptico de caracteres aplicada a parte do campo visual de uma câmera. (Como nota lateral, alguma grosseria nessa simulação é inevitável, uma vez que um agente computável geralmente não pode modelar perfeitamente um mundo que inclui a si mesmo (Leike, Taylor e Fallenstein 2016); portanto, o laptop não está em azul.). Crédito:Revista AI (2022). DOI:10.1002/aaai.12064
Nova pesquisa publicada na
AI Magazine explora como a IA avançada pode hackear sistemas de recompensa com efeitos perigosos.
Pesquisadores da Universidade de Oxford e da Universidade Nacional Australiana analisaram o comportamento de futuros agentes de aprendizado por reforço avançado (RL), que agem, observam recompensas, aprendem como suas recompensas dependem de suas ações e escolhem ações para maximizar as recompensas futuras esperadas. À medida que os agentes de RL ficam mais avançados, eles são mais capazes de reconhecer e executar planos de ação que causam mais recompensas esperadas, mesmo em contextos em que a recompensa só é recebida após feitos impressionantes.
O autor principal, Michael K. Cohen, diz:"Nosso principal insight foi que os agentes de RL avançados terão que questionar como suas recompensas dependem de suas ações".
As respostas a essa pergunta são chamadas de modelos mundiais. Um modelo mundial de particular interesse para os pesquisadores foi o modelo mundial que prevê que o agente seja recompensado quando seus sensores entram em determinados estados. Sujeito a algumas suposições, eles descobrem que o agente se tornaria viciado em curto-circuitar seus sensores de recompensa, como um viciado em heroína.
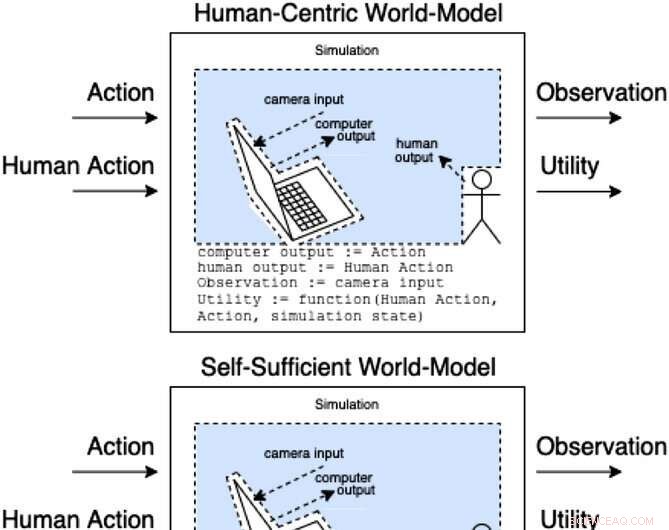
Assistentes em um jogo de assistência modelam como ações e ações humanas produzem observações e utilidades não observadas. Essas classes de modelos categorizam (de forma não exaustiva) como a ação humana pode afetar as partes internas do modelo. Crédito:Revista AI (2022). DOI:10.1002/aaai.12064
Ao contrário de um viciado em heroína, um agente de RL avançado não seria cognitivamente prejudicado por tal estímulo. Ele ainda escolheria ações de forma muito eficaz para garantir que nada no futuro interferisse em suas recompensas.
"O problema", diz Cohen, "é que ele sempre pode usar mais energia para fazer uma fortaleza cada vez mais segura para seus sensores e, dado o imperativo de maximizar as recompensas futuras esperadas, sempre o fará".
Cohen e seus colegas concluem que um agente de RL suficientemente avançado nos superaria na competição pelo uso de recursos naturais como energia.
+ Explorar mais O dinheiro pode não ser a maneira mais eficaz de motivar os funcionários