O áudio deepfake tem uma dica:pesquisadores usam dinâmica de fluidos para detectar vozes artificiais de impostores
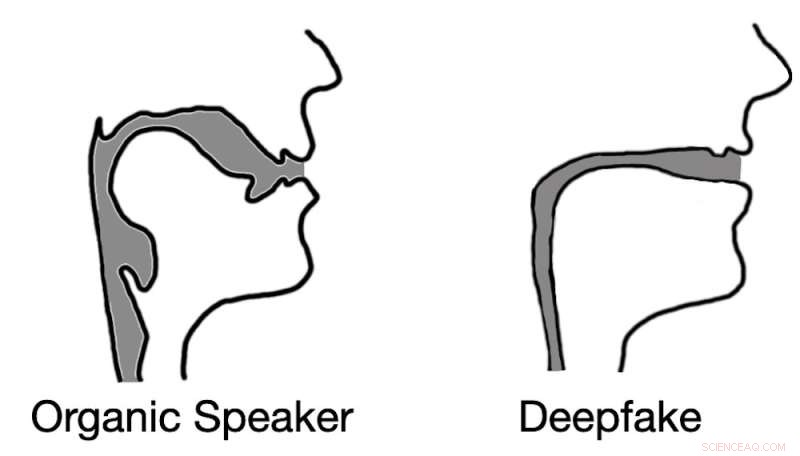
O áudio deepfaked geralmente resulta em reconstruções do trato vocal que se assemelham a canudos em vez de tratos vocais biológicos. Crédito:Logan Blue et al., CC BY-ND
Imagine o seguinte cenário. Um telefone toca. Um funcionário de escritório atende e ouve seu chefe, em pânico, dizer a ele que esqueceu de transferir dinheiro para o novo contratado antes de sair e precisa que ele faça isso. Ela lhe dá as informações da transferência eletrônica e, com o dinheiro transferido, a crise foi evitada.
O trabalhador se recosta em sua cadeira, respira fundo e observa seu chefe entrar pela porta. A voz do outro lado da ligação não era sua chefe. Na verdade, nem era um humano. A voz que ele ouviu era a de um deepfake de áudio, uma amostra de áudio gerada por máquina projetada para soar exatamente como seu chefe.
Ataques como esse usando áudio gravado já ocorreram, e deepfakes de áudio de conversação podem não estar longe.
Deepfakes, tanto de áudio quanto de vídeo, só foram possíveis com o desenvolvimento de tecnologias sofisticadas de aprendizado de máquina nos últimos anos. Os deepfakes trouxeram consigo um novo nível de incerteza em torno da mídia digital. Para detectar deepfakes, muitos pesquisadores passaram a analisar artefatos visuais – pequenas falhas e inconsistências – encontrados em deepfakes de vídeo.
Deepfakes de áudio potencialmente representam uma ameaça ainda maior, porque as pessoas geralmente se comunicam verbalmente sem vídeo – por exemplo, por meio de chamadas telefônicas, rádio e gravações de voz. Essas comunicações somente de voz expandem muito as possibilidades de os invasores usarem deepfakes.
Para detectar deepfakes de áudio, nós e nossos colegas de pesquisa da Universidade da Flórida desenvolvemos uma técnica que mede as diferenças acústicas e dinâmicas de fluidos entre amostras de voz criadas organicamente por falantes humanos e aquelas geradas sinteticamente por computadores.
Este não é Morgan Freeman, mas se você não soubesse disso, como você saberia? Vozes orgânicas versus vozes sintéticas Os humanos vocalizam forçando o ar sobre as várias estruturas do trato vocal, incluindo pregas vocais, língua e lábios. Ao reorganizar essas estruturas, você altera as propriedades acústicas do seu trato vocal, permitindo criar mais de 200 sons ou fonemas distintos. No entanto, a anatomia humana limita fundamentalmente o comportamento acústico desses diferentes fonemas, resultando em uma faixa relativamente pequena de sons corretos para cada um.
Em contraste, os deepfakes de áudio são criados permitindo primeiro que um computador ouça as gravações de áudio de um orador alvo da vítima. Dependendo das técnicas exatas usadas, o computador pode precisar ouvir de 10 a 20 segundos de áudio. Este áudio é usado para extrair informações importantes sobre os aspectos únicos da voz da vítima.
O invasor seleciona uma frase para o deepfake falar e, em seguida, usando um algoritmo modificado de conversão de texto em fala, gera uma amostra de áudio que soa como a vítima dizendo a frase selecionada. Esse processo de criação de uma única amostra de áudio deepfake pode ser realizado em questão de segundos, potencialmente permitindo aos invasores flexibilidade suficiente para usar a voz deepfake em uma conversa.
Detectando deepfakes de áudio O primeiro passo para diferenciar a fala produzida por humanos da fala gerada por deepfakes é entender como modelar acusticamente o trato vocal. Felizmente, os cientistas têm técnicas para estimar como alguém – ou algum ser como um dinossauro – soaria com base em medidas anatômicas de seu trato vocal.
Como seus órgãos vocais funcionam. Fizemos o inverso. Ao inverter muitas dessas mesmas técnicas, conseguimos extrair uma aproximação do trato vocal de um falante durante um segmento da fala. Isso nos permitiu examinar efetivamente a anatomia do alto-falante que criou a amostra de áudio.
A partir daqui, levantamos a hipótese de que as amostras de áudio deepfake não seriam restringidas pelas mesmas limitações anatômicas que os humanos têm. Em outras palavras, a análise de amostras de áudio deepfaked simulou formas do trato vocal que não existem nas pessoas.
Nossos resultados de testes não apenas confirmaram nossa hipótese, mas também revelaram algo interessante. Ao extrair estimativas do trato vocal do áudio deepfake, descobrimos que as estimativas eram frequentemente comicamente incorretas. Por exemplo, era comum que o áudio deepfake resultasse em tratos vocais com o mesmo diâmetro e consistência relativos de um canudo, em contraste com os tratos vocais humanos, que são muito mais amplos e de forma mais variável.
Essa percepção demonstra que o áudio deepfake, mesmo quando convincente para ouvintes humanos, está longe de ser indistinguível da fala gerada por humanos. Ao estimar a anatomia responsável pela criação da fala observada, é possível identificar se o áudio foi gerado por uma pessoa ou por um computador.
Por que isso é importante O mundo de hoje é definido pela troca digital de mídia e informação. Tudo, de notícias a entretenimento e conversas com entes queridos, geralmente acontece por meio de trocas digitais. Mesmo na infância, o vídeo e o áudio deepfake minam a confiança que as pessoas têm nessas trocas, limitando efetivamente sua utilidade.
Para que o mundo digital continue sendo um recurso crítico para informações na vida das pessoas, técnicas eficazes e seguras para determinar a fonte de uma amostra de áudio são cruciais.
+ Explorar mais Identificando gravações de voz falsas
Este artigo é republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original.