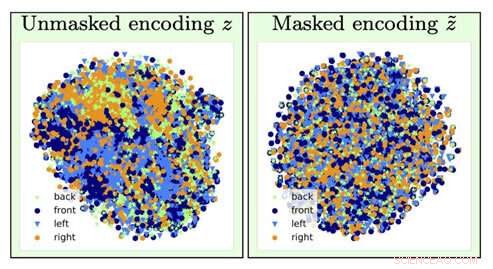
Para identificar o tipo de imagem de uma cadeira, informações sobre a orientação da cadeira (um fator incômodo) são perdidas pela operação de esquecimento (indo da visualização da esquerda para a direita). Crédito:University of Southern California
Imagine se da próxima vez que você solicitar um empréstimo, um algoritmo de computador determina que você precisa pagar uma taxa mais alta com base principalmente em sua raça, sexo ou código postal.
Agora, imagine que fosse possível treinar um modelo de aprendizado profundo de IA para analisar os dados subjacentes induzindo a amnésia:ele esquece certos dados e se concentra apenas em outros.
Se você está pensando que isso soa como a versão do cientista da computação de "The Eternal Sunshine of the Spotless Mind", "você acertaria em cheio. E graças aos pesquisadores de IA do Instituto de Ciências da Informação da USC (ISI), este conceito, chamado de esquecimento adversário, agora é um mecanismo real.
A importância de abordar e remover vieses na IA está se tornando mais importante à medida que a IA se torna cada vez mais prevalente em nossas vidas diárias, observou Ayush Jaiswal, o autor principal do artigo e Ph.D. candidato na Escola de Engenharia da USC Viterbi.
"AI e, mais especificamente, modelos de aprendizado de máquina herdam os preconceitos presentes nos dados em que foram treinados e são propensos a até mesmo amplificar esses preconceitos, "ele explicou." A IA está sendo usada para tomar várias decisões da vida real que afetam a todos nós, [como] determinar limites de crédito, aprovando empréstimos, pontuação de pedidos de emprego, etc. Se, por exemplo, modelos para tomar essas decisões são treinados cegamente em dados históricos, sem controle de vieses, eles aprenderiam a tratar injustamente os indivíduos que pertencem a setores historicamente desfavorecidos da população, como mulheres e pessoas de cor. "
A pesquisa foi liderada por Wael AbdAlmageed, líder da equipe de pesquisa do ISI e professor associado de pesquisa do Departamento de Engenharia Elétrica e de Computação da USC Viterbi Ming Hsieh, e o professor associado de pesquisa Greg Ver Steeg, bem como Premkumar Natarajan, professor pesquisador de ciência da computação e diretor executivo do ISI (de licença). Sob sua orientação, Jaiswal e co-autor Daniel Moyer, Ph.D., desenvolveu a abordagem de esquecimento adversário, que ensina modelos de aprendizagem profunda a desconsiderar específicos, fatores de dados indesejados para que os resultados que eles produzem sejam imparciais e mais precisos.
O artigo de pesquisa, intitulado "Representações Invariantes por meio do Esquecimento Adversarial, "foi apresentado na conferência Association for the Advancement for Artificial Intelligence na cidade de Nova York em 10 de fevereiro, 2020.
Incômodos e redes neurais
O aprendizado profundo é um componente central da IA e pode ensinar os computadores a encontrar correlações e fazer previsões com dados, ajudando a identificar pessoas ou objetos, por exemplo. Os modelos procuram, essencialmente, associações entre diferentes recursos nos dados e o destino que eles devem prever. Se um modelo foi encarregado de encontrar uma pessoa específica de um grupo, ele analisaria as características faciais para diferenciar todos e, em seguida, identificar a pessoa visada. Simples, direito?
Infelizmente, as coisas nem sempre funcionam tão bem, já que o modelo pode acabar aprendendo coisas que podem parecer contra-intuitivas. Ele pode associar sua identidade a um determinado plano de fundo ou configuração de iluminação e ser incapaz de identificá-lo se a iluminação ou o plano de fundo foram alterados; pode associar a sua caligrafia a uma determinada palavra, e ficar confuso se a mesma palavra foi escrita com a letra de outra pessoa. Esses fatores incômodos apropriadamente nomeados não estão relacionados à tarefa que você está tentando realizar, e associá-los erroneamente ao alvo de previsão pode realmente acabar sendo perigoso.
Os modelos também podem aprender vieses nos dados que estão correlacionados com o alvo de predição, mas são indesejados. Por exemplo, em tarefas realizadas por modelos envolvendo dados socioeconômicos historicamente coletados, como determinar pontuações de crédito, linhas de crédito, e elegibilidade para empréstimos, o modelo pode fazer previsões falsas e mostrar tendências ao fazer conexões entre as tendências e o alvo da previsão. Pode chegar à conclusão de que, uma vez que está analisando os dados de uma mulher, ela deve ter uma pontuação de crédito baixa; já que está analisando os dados de uma pessoa negra, eles não devem ser elegíveis para um empréstimo. Não faltam histórias de bancos que estão sendo criticados por suas decisões tendenciosas de algoritmos sobre quanto eles cobram das pessoas que tomaram empréstimos com base em sua raça, Gênero sexual, e educação, mesmo que tenham exatamente o mesmo perfil de crédito que alguém em um segmento populacional mais socialmente privilegiado.
Como Jaiswal explicou, o mecanismo de esquecimento adversário "conserta" redes neurais, que são modelos de aprendizado profundo poderosos que aprendem a prever alvos a partir de dados. O limite de crédito do novo cartão de crédito que você assinou? Uma rede neural provavelmente analisou seus dados financeiros para chegar a esse número.
A equipe de pesquisa desenvolveu o mecanismo de esquecimento adversarial para que pudesse primeiro treinar a rede neural para representar todos os aspectos subjacentes dos dados que está analisando e, em seguida, esquecer os preconceitos especificados. No exemplo do limite do cartão de crédito, isso significaria que o mecanismo poderia ensinar o algoritmo do banco a prever o limite enquanto se esquece, ou sendo invariante para, os dados específicos relativos a gênero ou raça. "[O mecanismo] pode ser usado para treinar redes neurais para serem invariantes a vieses conhecidos em conjuntos de dados de treinamento, "Jaiswal disse." Isto, por sua vez, resultaria em modelos treinados que não seriam tendenciosos ao tomar decisões. "
Algoritmos de aprendizado profundo são ótimos para aprender coisas, mas é mais difícil ter certeza de que os algoritmos não aprendem certas coisas. O desenvolvimento de algoritmos é um processo muito orientado por dados, e os dados tendem a conter vieses.
Mas não podemos simplesmente tirar todos os dados sobre raça, Gênero sexual, e educação para remover os preconceitos?
Não inteiramente. Existem muitos outros fatores de dados que estão correlacionados a esses fatores sensíveis que são importantes para os algoritmos analisarem. A chave, como os pesquisadores da ISI AI descobriram, está adicionando restrições no processo de treinamento do modelo para forçá-lo a fazer previsões enquanto é invariável para fatores específicos de dados - essencialmente, esquecimento seletivo.
Vieses de luta
A invariância se refere à capacidade de identificar um objeto específico, mesmo que sua aparência (ou seja, dados) é alterado de alguma forma, e Jaiswal e seus colegas começaram a pensar sobre como esse conceito poderia ser aplicado para melhorar algoritmos. "Meu co-autor, Dan [Moyer], e eu realmente tive essa ideia com base em nossas experiências anteriores no campo da aprendizagem de representação invariante, "ele comentou. Mas desenvolver o conceito não foi uma tarefa simples." As partes mais desafiadoras foram [a] comparação rigorosa com trabalhos anteriores neste domínio em uma ampla gama de conjuntos de dados (que exigiu a execução de um grande número de experimentos) e [ desenvolver] uma análise teórica do processo de esquecimento, " ele disse.
O mecanismo de esquecimento adversário também pode ser usado para ajudar a melhorar a geração de conteúdo em uma variedade de campos. "O campo emergente do aprendizado de máquina justo busca maneiras de reduzir o viés na tomada de decisão algorítmica com base nos dados do consumidor, "disse Ver Steeg." Uma área mais especulativa envolve a pesquisa sobre o uso de IA para gerar conteúdo, incluindo tentativas de livros, música, arte, jogos, e até receitas. Para que a geração de conteúdo tenha sucesso, precisamos de novas maneiras de controlar e manipular as representações da rede neural e o mecanismo de esquecimento pode ser uma maneira de fazer isso. "
Então, como os preconceitos aparecem no modelo em primeiro lugar?
A maioria dos modelos usa dados históricos, que, Infelizmente, pode ser amplamente inclinado para comunidades tradicionalmente marginalizadas, como as mulheres, minorias, até mesmo certos códigos postais. É caro e complicado coletar dados, então os cientistas tendem a recorrer a dados que já existem e treinar modelos com base nisso, que é como os preconceitos entram em cena.
A boa notícia é que esses preconceitos estão sendo reconhecidos, e embora o problema esteja longe de ser resolvido, avanços estão sendo feitos para entender e resolver essas questões. " na comunidade de pesquisa, as pessoas estão definitivamente se tornando cada vez mais conscientes dos preconceitos do conjunto de dados, e projetar e analisar protocolos de coleta para controlar tendências conhecidas, "disse Jaiswal." O estudo de preconceitos e justiça no aprendizado de máquina cresceu rapidamente como um campo de pesquisa nos últimos anos. "
A determinação de quais fatores devem ser considerados irrelevantes ou tendenciosos é feita por especialistas do domínio e com base em análises estatísticas. "Até aqui, invariância tem sido usada principalmente para remover fatores que são amplamente considerados indesejados / irrelevantes dentro da comunidade de pesquisa com base em evidências estatísticas, "Jaiswal afirmou.
Contudo, uma vez que os pesquisadores determinam o que é irrelevante ou tendencioso, pode haver um potencial para que essas determinações se transformem em preconceitos. Esse é um fator no qual os pesquisadores também estão trabalhando. "Descobrir quais fatores esquecer é um problema crítico que pode facilmente levar a consequências indesejadas, "observou Ver Steeg." Um artigo recente da Nature sobre o aprendizado justo mostra que temos que entender os mecanismos por trás da discriminação se esperamos especificar corretamente as soluções algorítmicas. "
O processamento de informações humanas é extremamente complexo, e o mecanismo de esquecimento adversário nos ajuda a dar um passo mais perto do desenvolvimento de IA que pode pensar como nós. Como Ver Steeg observou, os humanos tendem a separar diferentes formas de informação sobre o mundo ao seu redor por meio de algoritmos de captação de instintos para fazer o mesmo é o desafio em questão.
"Se alguém pisar na frente do seu carro, você bate no freio e o slogan em sua camisa nem passa pela sua mente, "disse Ver Steeg." Mas se você conheceu essa pessoa em um contexto social, essas informações podem ser relevantes e ajudá-lo a iniciar uma conversa. Para IA, diferentes tipos de informação são misturados. Se pudermos ensinar as redes neurais a separar conceitos que são úteis para diferentes tarefas, esperamos que leve a IA a uma compreensão mais humana do mundo. "
O processamento de informações humanas é extremamente complexo, e o mecanismo de esquecimento adversário nos ajuda a dar um passo mais perto do desenvolvimento de IA que pode pensar como nós. Como Ver Steeg observou, os humanos tendem a separar diferentes formas de informação sobre o mundo ao seu redor por instinto - fazer com que os algoritmos façam o mesmo é o grande desafio.
"Se alguém pisar na frente do seu carro, você bate no freio e o slogan em sua camisa nem passa pela sua mente, "disse Ver Steeg." Mas se você conheceu essa pessoa em um contexto social, essas informações podem ser relevantes e ajudá-lo a iniciar uma conversa. Para IA, diferentes tipos de informação são misturados. Se pudermos ensinar as redes neurais a separar conceitos que são úteis para diferentes tarefas, esperamos que leve a IA a uma compreensão mais humana do mundo. "