Crédito:Massachusetts Institute of Technology
Por todo o progresso que os pesquisadores fizeram com o aprendizado de máquina nos ajudando a fazer coisas como cálculos, dirigir carros e detectar câncer, raramente pensamos sobre o quanto consome energia para manter os enormes data centers que tornam esse trabalho possível. De fato, um estudo de 2017 previu que, em 2025, dispositivos conectados à Internet estariam usando 20% da eletricidade mundial.
A ineficiência do aprendizado de máquina é parcialmente uma função de como esses sistemas são criados. As redes neurais são normalmente desenvolvidas gerando um modelo inicial, ajustando alguns parâmetros, tentando de novo, e depois enxágue e repita. Mas essa abordagem significa um tempo significativo, os recursos de energia e computação são gastos em um projeto antes que alguém saiba se ele realmente funcionará.
O estudante de pós-graduação do MIT Jonathan Rosenfeld compara-o aos cientistas do século 17 que buscam entender a gravidade e o movimento dos planetas. Ele diz que a maneira como desenvolvemos sistemas de aprendizado de máquina hoje - na ausência de tais entendimentos - tem poder preditivo limitado e, portanto, é muito ineficiente.
"Ainda não há uma maneira unificada de prever o desempenho de uma rede neural, dados certos fatores, como a forma do modelo ou a quantidade de dados em que foi treinado, "diz Rosenfeld, que recentemente desenvolveu uma nova estrutura sobre o tópico com colegas do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL). "Queríamos explorar se poderíamos levar o aprendizado de máquina adiante tentando entender os diferentes relacionamentos que afetam a precisão de uma rede."
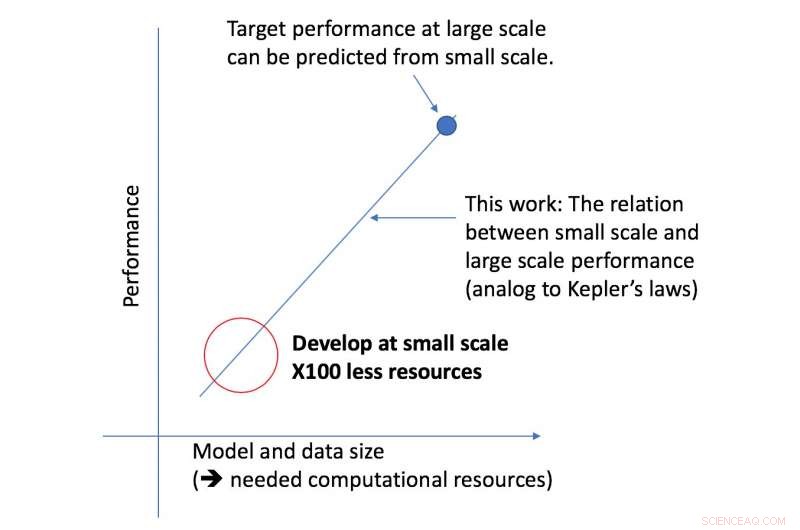
A nova estrutura da equipe CSAIL analisa um determinado algoritmo em uma escala menor, e, com base em fatores como sua forma, pode prever o quão bem ele terá um desempenho em uma escala maior. Isso permite que um cientista de dados determine se vale a pena continuar a dedicar mais recursos para treinar ainda mais o sistema.
"Nossa abordagem nos diz coisas como a quantidade de dados necessários para uma arquitetura entregar um desempenho de destino específico, ou a compensação mais eficiente do ponto de vista computacional entre os dados e o tamanho do modelo, "diz o professor do MIT Nir Shavit, que co-escreveu o novo artigo com Rosenfeld, o ex-aluno de PhD Yonatan Belinkov e Amir Rosenfeld da York University. "Vemos essas descobertas como tendo implicações de longo alcance no campo, permitindo que pesquisadores na academia e na indústria entendam melhor as relações entre os diferentes fatores que devem ser avaliados ao desenvolver modelos de aprendizagem profunda, e fazer isso com os recursos computacionais limitados disponíveis para acadêmicos. "
A estrutura permitiu aos pesquisadores prever com precisão o desempenho em grandes escalas de modelo e dados usando cinqüenta vezes menos poder computacional.
O aspecto do desempenho de aprendizagem profunda em que a equipe se concentrou é o chamado "erro de generalização, "que se refere ao erro gerado quando um algoritmo é testado em dados do mundo real. A equipe utilizou o conceito de escala de modelo, que envolve alterar a forma do modelo de maneiras específicas para ver seu efeito no erro.
Como próxima etapa, a equipe planeja explorar as teorias subjacentes sobre o que faz o desempenho de um algoritmo específico ter sucesso ou falhar. Isso inclui experimentar outros fatores que podem impactar o treinamento de modelos de aprendizado profundo.














