Oier Mees demonstrando como a nova abordagem funciona. Crédito:Mees et al.
Com mais robôs agora abrindo caminho em uma série de configurações, os pesquisadores estão tentando tornar suas interações com os humanos o mais suaves e naturais possíveis. Treinando robôs para responder imediatamente às instruções faladas, como "pegue o copo, mova para a direita, "etc., seria ideal em muitas situações, pois, em última análise, permitiria interações humano-robô mais diretas e intuitivas. Contudo, Isso não é sempre fácil, pois requer que o robô entenda as instruções do usuário, mas também saber mover objetos de acordo com relações espaciais específicas.
Pesquisadores da Universidade de Freiburg, na Alemanha, desenvolveram recentemente uma nova abordagem para ensinar robôs como mover objetos conforme instruído por usuários humanos, que funciona classificando representações de cenas "alucinadas". Seu papel, pré-publicado no arXiv, será apresentado na Conferência Internacional IEEE sobre Robótica e Automação (ICRA) em Paris, junho deste ano.
“No nosso trabalho, nos concentramos nas instruções relacionais de colocação de objetos, como 'coloque a caneca à direita da caixa' ou 'coloque o brinquedo amarelo em cima da caixa, '' Oier Mees, um dos pesquisadores que realizou o estudo, disse TechXplore. "Para fazer isso, o robô precisa raciocinar sobre onde colocar a caneca em relação à caixa ou qualquer outro objeto de referência para reproduzir a relação espacial descrita por um usuário. "
Treinar robôs para entender as relações espaciais e mover objetos de acordo pode ser muito difícil, já que as instruções do usuário normalmente não delineiam um local específico dentro de uma cena maior observada pelo robô. Em outras palavras, se um usuário humano disser "coloque a caneca à esquerda do relógio, "a que distância do relógio o robô deve colocar a caneca e onde é o limite exato entre as diferentes direções (por exemplo, direito, deixou, em frente, atrás, etc.)?
"Devido a essa ambigüidade inerente, também não há verdade ou dados "corretos" que podem ser usados para aprender a modelar relações espaciais, "Disse Mees." Abordamos o problema da indisponibilidade de anotações pixelwise de verdade terrestre das relações espaciais da perspectiva do aprendizado auxiliar. "
A ideia principal por trás da abordagem desenvolvida por Mees e seus colegas é que, quando dados dois objetos e uma imagem que representa o contexto em que se encontram, é mais fácil determinar a relação espacial entre eles. Isso permite que os robôs detectem se um objeto está à esquerda do outro, no topo disso, na frente dele, etc.
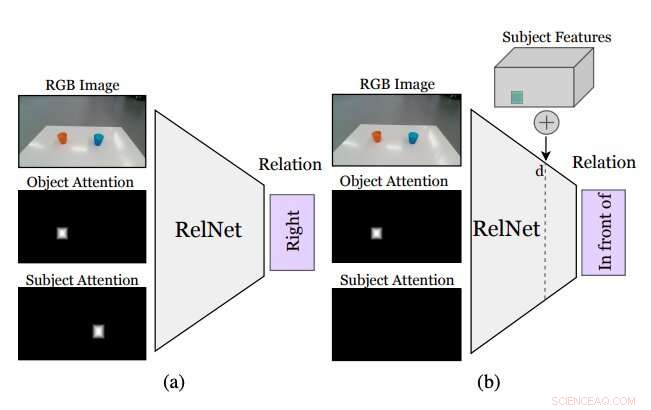
Figura resumindo como funciona a abordagem idealizada pelos pesquisadores. Uma CNN auxiliar, chamado RelNet, é treinado para prever relações espaciais com base na imagem de entrada e duas máscaras de atenção referentes a dois objetos formando uma relação. (a) após o treinamento, a rede pode ser "enganada" para classificar cenas alucinadas (b) implementando recursos de alto nível de itens em diferentes localizações espaciais. Crédito:Mees et al.
Embora a identificação de uma relação espacial entre dois objetos não especifica onde os objetos devem ser colocados para reproduzir essa relação, inserir outros objetos na cena poderia permitir ao robô inferir uma distribuição em várias relações espaciais. Adicionando esses inexistentes (ou seja, objetos alucinados) para o que o robô está vendo deve permitir que ele avalie como a cena ficaria se realizasse uma determinada ação (ou seja, colocar um dos objetos em um local específico na mesa ou superfície na frente dela).
"Mais comumente, 'colar' objetos realisticamente em uma imagem requer acesso a modelos e silhuetas 3-D ou projetar cuidadosamente o procedimento de otimização de redes adversárias geradoras (GANs), "Mees disse." Além disso, "colar" ingenuamente máscaras de objeto em imagens cria artefatos de pixel sutis que levam a características visivelmente diferentes e ao treinamento focado erroneamente nessas discrepâncias. Tomamos uma abordagem diferente e implantamos características de alto nível de objetos em mapas de características da cena gerados por uma rede neural convolucional para alucinar representações de cena, que são então classificados como tarefas auxiliares para obter o sinal de aprendizagem. "
Antes de treinar uma rede neural convolucional (CNN) para aprender as relações espaciais com base em objetos alucinados, os pesquisadores precisavam garantir que ele fosse capaz de classificar as relações entre pares individuais de objetos com base em uma única imagem. Subseqüentemente, eles "enganaram" sua rede, apelidado de RelNet, na classificação de cenas "alucinadas", implantando recursos de alto nível de itens em diferentes localizações espaciais.
"Nossa abordagem permite que um robô siga as instruções de colocação em linguagem natural fornecidas por usuários humanos com o mínimo de coleta de dados ou heurística, "Disse Mees." Todos gostariam de ter um robô de serviço em casa que pudesse realizar tarefas ao entender as instruções em linguagem natural. Este é o primeiro passo para permitir que um robô entenda melhor o significado das preposições espaciais comumente usadas. "
A maioria dos métodos existentes para treinar robôs para mover objetos usam informações relacionadas aos objetos "formas 3-D para modelar relações espaciais de pares. Uma limitação importante dessas técnicas é que elas geralmente requerem componentes tecnológicos adicionais, como sistemas de rastreamento que podem rastrear os movimentos de diferentes objetos. A abordagem proposta por Mees e seus colegas, por outro lado, não requer ferramentas adicionais, uma vez que não é baseado em técnicas de visão 3-D.
Os pesquisadores avaliaram seu método em uma série de experimentos envolvendo robôs e usuários humanos reais. Os resultados desses testes foram altamente promissores, já que seu método permitiu que os robôs identificassem efetivamente as melhores estratégias para colocar objetos em uma mesa de acordo com as relações espaciais delineadas pelas instruções faladas de um usuário humano.
"Nossa nova abordagem de representações de cenas alucinantes também pode ter várias aplicações nas comunidades de robótica e visão computacional, já que muitas vezes os robôs precisam ser capazes de estimar o quão bom um estado futuro pode ser para raciocinar sobre as ações que eles precisam tomar, "Disse Mees." Também poderia ser usado para melhorar o desempenho de muitas redes neurais, como redes de detecção de objetos, usando representações de cenas alucinadas como uma forma de aumento de dados. "
Mees e seus colegas foram capazes de modelar um conjunto de preposições espaciais de linguagem natural (por exemplo, à direita, deixou, Em cima de, etc.) de forma confiável e sem o uso de ferramentas de visão 3-D. No futuro, a abordagem apresentada em seu estudo pode ser usada para aprimorar as capacidades dos robôs existentes, permitindo que eles concluam tarefas simples de deslocamento de objetos com mais eficiência, enquanto seguem as instruções faladas de um usuário humano.
Enquanto isso, seu artigo pode informar o desenvolvimento de técnicas semelhantes para melhorar as interações entre humanos e robôs durante outras tarefas de manipulação de objetos. Se combinado com métodos auxiliares de aprendizagem, a abordagem desenvolvida por Mees e seus colegas também pode reduzir os custos e esforços associados à compilação de conjuntos de dados para pesquisa robótica, uma vez que permite a previsão de probabilidades pixelwise sem exigir grandes conjuntos de dados anotados.
"Sentimos que este é um primeiro passo promissor para permitir um entendimento compartilhado entre humanos e robôs, "Mees concluiu." No futuro, queremos estender nossa abordagem para incorporar uma compreensão das expressões de referência, a fim de desenvolver um sistema pick-and-place que segue as instruções da linguagem natural. "
© 2020 Science X Network