Um dos três considerados ambientes de aprendizagem, ou seja, locomoção. Em locomoção, os agentes aprendem a navegar no ambiente evitando obstáculos (retângulos escuros) e outros agentes. Crédito:Amine Boumaza.
Recombinação, o rearranjo de materiais genéticos como resultado do acasalamento ou da combinação de segmentos de DNA de diferentes organismos, tem inúmeras vantagens evolutivas. Por exemplo, permite que os organismos removam mutações deletérias de seus genomas e realizem mutações mais úteis.
Amine Boumaza, um pesquisador da Université de Lorraine, recentemente tentou aplicar este processo à robótica evolucionária incorporada online, uma área da robótica que se concentra em replicar teorias da evolução em robôs. Em seu jornal, publicado na revista GECCO '19 Proceedings of the Genetic and Evolutionary Computation Conference, ele desenvolveu um operador de recombinação inspirado na evolução e o treinou em três tarefas que requerem colaboração entre vários robôs.
"Minha pesquisa se enquadra no assunto mais amplo de IA, e mais especificamente, entender como podemos projetar agentes que podem aprender a realizar tarefas interessantes, "Boumaza disse." Este tópico de pesquisa não é novo, mas bastante antigo, e tem recebido muita atenção ultimamente por causa dos resultados impressionantes do aprendizado profundo. No meu caso, Estou mais interessado em robótica de enxame, onde o objetivo é fazer com que um grande número de pequenos robôs cooperem para resolver uma tarefa e se adaptar às mudanças em seu ambiente. "
Fascinado pelas estratégias evolutivas, particularmente recombinação, que melhor equipam os organismos vivos para enfrentar os desafios da vida, Boumaza começou a investigar se mecanismos semelhantes poderiam ser aplicados a abordagens de robótica. Sua hipótese era que, se replicada com sucesso em robôs, a recombinação aumentaria seu desempenho e eficiência.
"Quando falamos sobre agentes robóticos, geralmente assumimos uma entidade física incorporada em um ambiente (um robô aspirador em uma sala, por exemplo), "Boumaza disse." Este agente percebe seus arredores usando um conjunto de sensores (sensores de obstáculos, Câmera, etc.), que pode dar a ele algum tipo de representação de seu ambiente. O agente também pode atuar no ambiente por meio de efetores (motores, braços, escova de limpeza, etc.). Essas ações são os resultados de um cálculo que é a saída do que comumente chamamos de controlador (ou seja, algum tipo de programa de decisão). "

Um dos três considerados ambientes de aprendizagem, ou seja, coleção de itens. Na coleção de itens, os agentes devem coletar o máximo de itens (pontos vermelhos) possível. Crédito:Amine Boumaza.
Um controlador é essencialmente um programa que processa as percepções adquiridas por um robô por meio de seus sensores e envia comandos para seus efetuadores. No caso de um aspirador de pó robótico, por exemplo, um controlador processaria informações sobre seus arredores, detectar se há poeira na frente dele, em seguida, produza saídas que farão o robô ativar o vácuo e avançar para aspirar a poeira.
"Dando um passo adiante, também podemos considerar vários agentes que podem evoluir no mesmo ambiente, "Boumaza disse." Projetar controladores para cada agente em tais ambientes é um problema muito difícil para o qual ainda não existe uma técnica eficiente. Nesse caso, podemos ter poucos (por exemplo, 10 a 100) robôs complexos, ou muitos robôs muito simples (por exemplo, centenas) que interagem de maneiras que geralmente são inspiradas no comportamento dos insetos; isso é o que chamamos de robótica de enxame. "
Ao desenvolver um robô que pode efetivamente completar uma tarefa específica, os pesquisadores precisam projetar um controlador adaptado a essa tarefa específica. Se o ambiente em que o robô deve operar for simples, projetar este controlador pode ser bastante fácil, mas na maioria das vezes, Este não é o caso.
Isso se torna ainda mais difícil, se não impossível, ao considerar vários robôs interagindo em um determinado ambiente. A principal razão para isso é que um desenvolvedor humano não pode prever todas as situações que cada robô encontrará, bem como as ações mais eficazes para enfrentar cada uma dessas situações. Felizmente, nos últimos anos, os avanços no aprendizado de máquina abriram novas possibilidades interessantes para a pesquisa em robótica, permitindo que os desenvolvedores incorporem ferramentas que permitem o aprendizado contínuo, essencialmente treinando o controlador para lidar com várias situações ao longo do tempo.
"Uma maneira de projetar um controlador dessa forma é usar algoritmos evolutivos, que, falando livremente, tente imitar a evolução natural das espécies para desenvolver controladores de agentes robóticos, "Boumaza disse." É um processo iterativo onde, à medida que os animais se adaptam melhor a seus ambientes, o controlador fica melhor na resolução de uma tarefa. O objetivo não é simular a evolução natural, mas sim inspirar-se nele. "
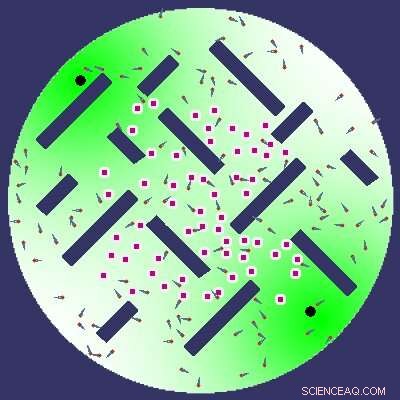
Um dos três considerados ambientes de aprendizagem, ou seja, forrageamento. Na coleta, os agentes devem coletar itens e carregá-los de volta ao ninho (um dos dois círculos pretos). O piso verde é uma trilha de feromônios que adiciona um senso de direção, é altamente concentrado nos locais dos ninhos e menos concentrado mais longe. Crédito:Amine Boumaza.
A robótica evolucionária é apenas uma das muitas técnicas que os pesquisadores podem usar para projetar controladores de robôs. Nos últimos anos, Contudo, abordagens evolutivas ganharam popularidade, com um número crescente de estudos voltados para a replicação de estratégias evolutivas observadas em animais e humanos.
"A robótica evolucionária tem algumas vantagens, como aquele fato de que não precisamos especificar como resolver a tarefa (ela é descoberta / aprendida pelo algoritmo), mas apenas precisa especificar uma maneira de medir o quão bem a tarefa é executada, "Boumaza disse. Também tem algumas desvantagens, pois é um processo muito lento e computacionalmente intensivo, isso pode ser muito difícil de executar em robôs reais. Além disso, essas abordagens são normalmente muito sensíveis às medidas de desempenho, na medida em que condicionam o comportamento aprendido pelos agentes. "
Boumaza, como outros pesquisadores da área, tem tentado desenvolver novas abordagens para superar as deficiências das técnicas de robótica evolutiva existentes. Em seu estudo recente, ele propôs especificamente o uso de um novo "operador de acasalamento" inspirado pela recombinação, que pode melhorar a velocidade de convergência em simulações de robôs. Esta é uma conquista notável, pois isso poderia reduzir o tempo necessário para transferir uma abordagem de simulações para robôs reais.
Ele aplicou seu operador de recombinação a três tarefas coletivas de robótica:locomoção, coleta de itens e forrageamento de itens. Ele então comparou o desempenho obtido usando uma versão puramente mutativa de seu algoritmo com o de diferentes operadores de recombinação. Os resultados reunidos em seus experimentos sugerem que, quando projetado corretamente, As estratégias de recombinação podem de fato melhorar a adaptação de um enxame de robôs em todas as tarefas que ele considerou.
No futuro, a nova abordagem de robótica evolutiva que ele propôs pode ser usada para melhorar o desempenho e a adaptabilidade de robôs em tarefas que requerem colaboração entre vários agentes. Enquanto isso, Contudo, Boumaza planeja testar seu algoritmo em novas tarefas, para determinar se a melhoria que ele observou nas três tarefas em que se concentrou ainda se mantém.
"Também seria interessante verificar se minha abordagem pode ser implementada em robôs reais, "Boumaza disse." Teoricamente nada impede isso, exceto ter um grande número de robôs físicos e aceitar lidar com a 'lacuna de realidade' (ou seja, o que vemos na simulação geralmente não é o que aconteceria na realidade, devido às simplificações de simulação. A robótica de enxame tem tudo a ver com números e as falhas de um único robô não devem atrapalhar o enxame. Em última análise, Portanto, para verificar a validade desta abordagem, ela deve ser testada na realidade, em robôs físicos. "
© 2019 Science X Network