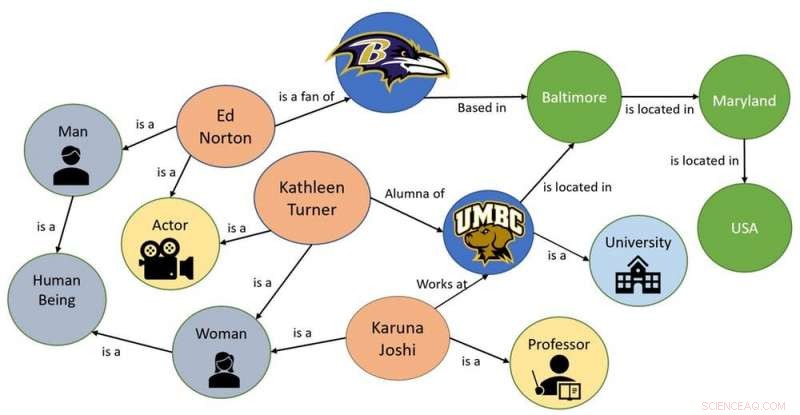
Um exemplo de gráfico de conhecimento simples. Crédito:Karuna Pande Joshi, CC BY-ND
Você está rastreando dados pessoais, como números de cartão de crédito, preferências de compras e quais artigos de notícias você lê - enquanto viaja pela internet. Grandes empresas da Internet ganham dinheiro com esse tipo de informação pessoal, compartilhando-as com suas subsidiárias e terceiros. A preocupação do público com a privacidade online resultou em leis destinadas a controlar quem obtém esses dados e como eles podem usá-los.
A batalha continua. Os democratas no Senado dos EUA recentemente apresentaram um projeto de lei que inclui penalidades para empresas de tecnologia que manuseiam indevidamente os dados pessoais dos usuários. Essa lei se juntaria a uma longa lista de regras e regulamentos em todo o mundo, incluindo o padrão de segurança de dados da indústria de cartões de pagamento que regula as transações on-line com cartão de crédito, o Regulamento Geral de Proteção de Dados da União Europeia, a Lei de Privacidade do Consumidor da Califórnia que entrou em vigor em janeiro, e a Lei de Proteção à Privacidade On-line de Crianças dos EUA.
As empresas de Internet devem aderir a esses regulamentos ou arriscar-se a processos judiciais caros ou sanções governamentais, como a recente multa de US $ 5 bilhões da Federal Trade Commission imposta ao Facebook.
Mas é tecnicamente desafiador determinar em tempo real se ocorreu uma violação de privacidade, um problema que está se tornando ainda mais problemático à medida que os dados da Internet atingem uma escala extrema. Para garantir que seus sistemas estejam em conformidade, as empresas contam com especialistas humanos para interpretar as leis - uma tarefa complexa e demorada para organizações que lançam e atualizam serviços constantemente.
Meu grupo de pesquisa na Universidade de Maryland, Condado de Baltimore, desenvolveu novas tecnologias para que as máquinas entendam as leis de privacidade de dados e garantam a conformidade com elas usando inteligência artificial. Essas tecnologias permitirão que as empresas garantam que seus serviços estejam em conformidade com as leis de privacidade e também ajudarão os governos a identificar em tempo real as empresas que violam os direitos de privacidade dos consumidores.
Ajudando as máquinas a entender os regulamentos
Os governos geram regulamentações de privacidade online como documentos de texto simples que são fáceis de ler, mas difíceis de interpretar pelas máquinas. Como resultado, os regulamentos precisam ser examinados manualmente para garantir que nenhuma regra seja quebrada quando os dados privados de um cidadão são analisados ou compartilhados. Isso afeta as empresas que agora precisam cumprir uma série de regulamentações.
As regras e regulamentos geralmente são ambíguos por design, porque as sociedades desejam flexibilidade para implementá-los. Conceitos subjetivos como bom e mau variam entre as culturas e ao longo do tempo, assim, as leis são redigidas em termos gerais ou vagos para permitir espaço para modificações futuras. As máquinas não podem processar essa imprecisão - elas operam em 1s e 0s - portanto, não podem "entender" a privacidade da maneira como os humanos o fazem. As máquinas precisam de instruções específicas para compreender o conhecimento no qual se baseia um regulamento.

O aplicativo dos pesquisadores extraiu automaticamente as regras deônticas, como permissões e obrigações, de dois regulamentos de privacidade. As entidades envolvidas nas regras são destacadas em amarelo. Palavras modais que ajudam a identificar se uma regra é uma permissão, proibição ou obrigação são destacadas em azul. Cinza indica o aspecto temporal ou baseado no tempo da regra. Crédito:Karuna Pande Joshi, CC BY-ND
Uma maneira de ajudar as máquinas a entender um conceito abstrato é construindo uma ontologia, ou um gráfico que representa o conhecimento desse conceito. Tomando emprestados os conceitos de ontologia da filosofia, novas linguagens de computador, como OWL, foram desenvolvidos em IA. Essas linguagens podem definir conceitos e categorias em uma área de assunto ou domínio, mostram suas propriedades e mostram as relações entre elas. Ontologias são às vezes chamadas de "gráficos de conhecimento, "porque eles são armazenados em estruturas semelhantes a gráficos.
Quando meus colegas e eu começamos a encarar o desafio de tornar os regulamentos de privacidade compreensíveis por máquinas, determinamos que o primeiro passo seria capturar todo o conhecimento-chave dessas leis e criar gráficos de conhecimento para armazená-lo.
Extraindo os termos e regras
O conhecimento chave nos regulamentos consiste em três partes.
Primeiro, existem "termos da arte":palavras ou frases que têm definições precisas dentro de uma lei. Eles ajudam a identificar a entidade que o regulamento descreve e nos permitem descrever suas funções e responsabilidades em uma linguagem que os computadores possam entender. Por exemplo, do Regulamento Geral de Proteção de Dados da UE, extraímos termos da arte, como "Consumidores e Provedores" e "Multas e Execução".
Próximo, identificamos regras deônticas:sentenças ou frases que nos fornecem uma lógica modal filosófica, que lida com o comportamento dedutivo. As regras deônticas (ou morais) incluem sentenças que descrevem deveres ou obrigações e caem principalmente em quatro categorias. "Permissões" definem os direitos de uma entidade / ator. “Obrigações” definem as responsabilidades de uma entidade / ator. "Proibições" são condições ou ações que não são permitidas. "Dispensações" são declarações opcionais ou não obrigatórias.
Para explicar isso com um exemplo simples, considere o seguinte:

gráfico de conhecimento para regulamentações GDPR. Crédito:Karuna Pande Joshi, CC BY-ND
Algumas dessas regras se aplicam a todos uniformemente em todas as condições; enquanto outros podem se aplicar parcialmente, a apenas uma entidade ou com base em condições acordadas por todos.
Regras semelhantes que descrevem o que fazer e o que não fazer se aplicam aos dados pessoais online. Existem permissões e proibições para evitar violações de dados. Existem obrigações para as empresas que armazenam os dados para garantir a sua segurança. E há dispensas para grupos demográficos vulneráveis, como menores.
Meu grupo desenvolveu técnicas para extrair automaticamente essas regras dos regulamentos e salvá-las em um gráfico de conhecimento.
Em terceiro lugar, também tivemos que descobrir como incluir as referências cruzadas que são frequentemente usadas em regulamentos legais para fazer referência a textos em outra seção do regulamento ou em um documento separado. Esses são elementos de conhecimento importantes que também devem ser armazenados no gráfico de conhecimento.
Regras em vigor, escaneando para conformidade
Depois de definir todas as entidades-chave, propriedades, relações, regras e políticas de uma lei de privacidade de dados em um gráfico de conhecimento, meus colegas e eu podemos criar aplicativos que podem raciocinar sobre as regras de privacidade de dados usando esses gráficos de conhecimento.
Esses aplicativos podem reduzir significativamente o tempo que as empresas levam para determinar se estão cumprindo os regulamentos de proteção de dados. Eles também podem ajudar os reguladores a monitorar as trilhas de auditoria de dados para determinar se as empresas que supervisionam estão cumprindo as regras.
Essa tecnologia também pode ajudar os indivíduos a obter um instantâneo rápido de seus direitos e responsabilidades com relação aos dados privados que compartilham com as empresas. Uma vez que as máquinas podem interpretar rapidamente longos, políticas de privacidade complexas, as pessoas serão capazes de automatizar muitas atividades rotineiras de conformidade que são feitas manualmente hoje. Eles também podem tornar essas políticas mais compreensíveis para os consumidores.
Este artigo foi republicado de The Conversation sob uma licença Creative Commons. Leia o artigo original.