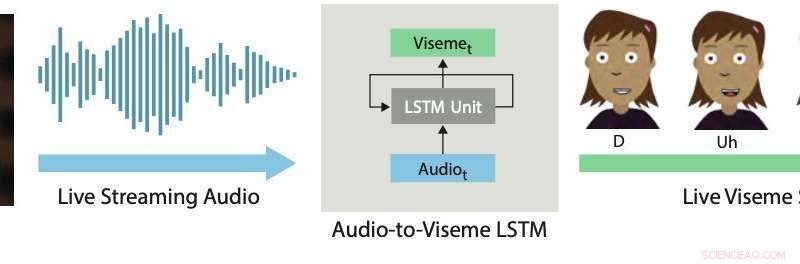
Sincronização labial em tempo real. Nossa abordagem de aprendizado profundo usa um LSTM para converter áudio de streaming ao vivo em visemas discretos para personagens 2D. Crédito:Aneja &Li.
A animação 2-D ao vivo é uma forma de comunicação relativamente nova e poderosa que permite que os atores humanos controlem os personagens de desenhos animados em tempo real enquanto interagem e improvisam com outros atores ou membros do público. Exemplos recentes incluem Stephen Colbert entrevistando convidados de desenhos animados no The Late Show , Homer respondendo perguntas ao vivo por telefone de espectadores durante um segmento de Os Simpsons , Archer falando ao vivo na ComicCon, e as estrelas da Disney Star vs. The Forces of Evil e Meu pequeno Pônei hospedar sessões de chat ao vivo com fãs via YouTube ou Facebook Live.
A produção de animações 2-D realistas e eficazes ao vivo requer o uso de sistemas interativos que podem transformar automaticamente performances humanas em animações em tempo real. Um aspecto fundamental desses sistemas é obter uma boa sincronização labial, o que significa essencialmente que as bocas dos personagens animados se movem de maneira adequada quando falam, imitando os movimentos observados na boca dos performers.
Uma boa sincronização labial pode tornar a animação 2-D ao vivo mais convincente e poderosa, permitindo que personagens animados incorporem a performance de forma mais realista. Por outro lado, A sincronização labial deficiente normalmente quebra a ilusão dos personagens como participantes ao vivo em uma performance ou diálogo.
Em um artigo publicado recentemente em arXiv, dois pesquisadores da Adobe Research e da University of Washington introduziram um sistema interativo baseado em aprendizado profundo que gera automaticamente sincronização labial ao vivo para personagens animados em 2-D em camadas. O sistema que desenvolveram usa um modelo de memória de longo prazo (LSTM), uma arquitetura de rede neural recorrente (RNN), muitas vezes aplicada a tarefas que envolvem classificação ou processamento de dados, bem como fazer previsões.
"Como a fala é o componente dominante de quase todas as animações ao vivo, acreditamos que o problema mais crítico a ser abordado neste domínio é a sincronização labial ao vivo, que envolve transformar a fala de um ator em movimentos de boca correspondentes (ou seja, sequência viseme) no personagem animado. Nesse trabalho, nos concentramos na criação de sincronização labial de alta qualidade para animação 2-D ao vivo, "Wilmot Li e Deepali Aneja, os dois pesquisadores que realizaram a pesquisa, disse ao TechXplore por e-mail.
Li é um cientista principal da Adobe Research com um Ph.D. em ciência da computação, que tem conduzido uma extensa pesquisa com foco em tópicos na interseção de computação gráfica e interação humano-computador. Aneja, por outro lado, atualmente está concluindo seu doutorado. em ciência da computação na Universidade de Washington, onde faz parte do Laboratório de Gráficos e Imagens.
O sistema desenvolvido por Li e Aneja usa um modelo LSTM simples para converter a entrada de áudio de streaming em uma sequência viseme correspondente a 24 quadros por segundo, com latência inferior a 200 milissegundos. Em outras palavras, seu sistema permite que os lábios de um personagem animado se movam de maneira semelhante aos de um usuário humano falando em tempo real, com menos de 200 milissegundos de atraso entre a voz e o movimento labial.
"Nesse trabalho, fazemos duas contribuições - identificar a representação de recurso apropriada e configuração de rede para obter resultados de ponta para sincronização labial 2-D ao vivo e desenvolver um novo método de aumento para coletar dados de treinamento para o modelo, "Li e Aneja explicaram.
"Para sincronização labial de autoria manual, animadores profissionais tomam decisões estilísticas sobre a escolha específica de visemas e o tempo e o número de transições. Como resultado, treinar um único modelo de 'uso geral' provavelmente não será suficiente para a maioria das aplicações, "Li e Aneja disseram. Além disso, obter dados de sincronização labial rotulados para treinar modelos de aprendizado profundo pode ser caro e demorado. Os animadores profissionais podem gastar de cinco a sete horas de trabalho por minuto de fala para criar sequências viseme manualmente. Ciente dessas limitações, Li e Aneja desenvolveram um método que pode gerar dados de treinamento de forma mais rápida e eficaz.
Para treinar seu modelo LSTM de forma mais eficaz, Li e Aneja introduziram uma nova técnica que aumenta os dados de treinamento de autoria manual usando sincronização de tempo de áudio. Este procedimento de aumento de dados obteve boa sincronização labial, mesmo ao treinar seu modelo em um pequeno conjunto de dados rotulado.
Para avaliar a eficácia de seu sistema interativo na produção de sincronização labial em tempo real, os pesquisadores pediram aos espectadores humanos que classificassem a qualidade das animações ao vivo desenvolvidas por seu modelo com aquelas produzidas usando ferramentas comerciais de animação 2-D. Eles descobriram que a maioria dos espectadores preferia a sincronização labial gerada por sua abordagem em vez daquela produzida por outras técnicas.
"Também investigamos a relação entre a qualidade da sincronização labial e a quantidade de dados de treinamento, e descobrimos que nosso método de aumento de dados melhora significativamente a saída do modelo, "Li e Aneja disseram." Em geral, podemos produzir resultados razoáveis com apenas 15 minutos de dados de sincronização labial de autoria manual. "
Interessantemente, os pesquisadores descobriram que seu modelo LSTM pode adquirir diferentes estilos de sincronização labial com base nos dados em que é treinado, ao mesmo tempo, generalizando bem em uma ampla gama de alto-falantes. Impressionado com os resultados encorajadores alcançados pelo modelo, A Adobe decidiu integrar uma versão dele em seu software Adobe Character Animator, lançado no outono de 2018.
"Preciso, a sincronização labial de baixa latência é importante para quase todas as configurações de animação ao vivo, e nossos experimentos de julgamento humano mostram que nossa técnica melhora os motores de sincronização labial 2D de última geração existentes, a maioria dos quais requer processamento offline, "Li e Aneja disseram. Assim, os pesquisadores acreditam que seu trabalho tem implicações práticas imediatas para a produção de animações 2-D ao vivo e não ao vivo. Os pesquisadores não estão cientes do trabalho anterior de sincronização labial 2-D com comparações igualmente abrangentes com ferramentas comerciais.
Em seu estudo recente, Li e Aneja conseguiram enfrentar alguns dos principais desafios técnicos associados ao desenvolvimento de técnicas de animação 2-D ao vivo. Primeiro, eles demonstraram um novo método para codificar regras artísticas para sincronização labial 2-D usando RNNs, que pode ser melhorado no futuro.
Os pesquisadores acreditam que há muito mais oportunidades de aplicar técnicas modernas de aprendizado de máquina para melhorar os fluxos de trabalho de animação 2-D. "Até agora, um desafio tem sido a falta de dados de treinamento, que é caro para coletar. Contudo, como mostramos neste trabalho, pode haver maneiras de aproveitar dados estruturados e algoritmos de edição automática (por exemplo, sincronização de tempo dinâmica) para maximizar a utilidade dos dados de animação feitos à mão, "Li e Aneja disseram.
Embora a estratégia de aumento de dados proposta pelos pesquisadores possa reduzir significativamente os requisitos de dados de treinamento para modelos projetados para produzir sincronização labial em tempo real, animar manualmente conteúdo de sincronização labial suficiente para treinar novos modelos ainda requer trabalho e esforço consideráveis. De acordo com Li e Aneja, Contudo, Pode ser desnecessário treinar um modelo inteiro do zero para cada novo estilo de sincronização labial que encontrar.
Os pesquisadores estão interessados em explorar estratégias de ajuste fino que podem permitir aos animadores adaptar o modelo a estilos diferentes com uma quantidade muito menor de entrada do usuário. "Uma ideia relacionada é aprender diretamente um modelo de sincronização labial que inclui explicitamente parâmetros estilísticos ajustáveis. Embora isso possa exigir um conjunto de dados de treinamento muito maior, o benefício potencial é um modelo que é geral o suficiente para suportar uma variedade de estilos de sincronização labial sem treinamento adicional, "disseram os pesquisadores.
Interessantemente, em seus experimentos, os pesquisadores observaram que a simples perda de entropia cruzada que usaram para treinar seu modelo não refletia com precisão as diferenças perceptivas mais relevantes entre as sequências de sincronização labial. Mais especificamente, eles descobriram que certas discrepâncias (por exemplo, perder uma transição ou substituir um viseme de boca fechada por um viseme de boca aberta) são muito mais óbvios do que outros. "Achamos que projetar ou aprender uma perda baseada na percepção em pesquisas futuras pode levar a melhorias no modelo resultante, "Li e Aneja disseram.
© 2019 Science X Network