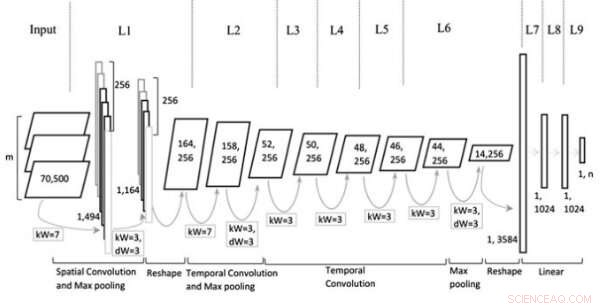
Arquitetura do modelo. Crédito:Jin et al, Jornal Wiley Computational Intelligence.
Ao longo da última década ou assim, Redes neurais convolucionais (CNNs) provaram ser muito eficazes para lidar com uma variedade de tarefas, incluindo tarefas de processamento de linguagem natural (PNL). A PNL envolve o uso de técnicas computacionais para analisar ou sintetizar a linguagem, tanto na forma escrita como falada. Os pesquisadores aplicaram CNNs com sucesso a várias tarefas de PNL, incluindo análise semântica, recuperação de consulta de pesquisa e classificação de texto.
Tipicamente, CNNs treinados para tarefas de classificação de texto processam sentenças no nível da palavra, representando palavras individuais como vetores. Embora esta abordagem possa parecer consistente com a forma como os humanos processam a linguagem, estudos recentes mostraram que as CNNs que processam sentenças no nível do personagem também podem alcançar resultados notáveis.
Uma das principais vantagens das análises em nível de caractere é que elas não exigem conhecimento prévio das palavras. Isso torna mais fácil para os CNNs se adaptarem a diferentes idiomas e adquirir palavras anormais causadas por erros ortográficos.
Estudos anteriores sugerem que diferentes níveis de incorporação de texto (ou seja, caractere-, palavra-, ou nível de documento) são mais eficazes para diferentes tipos de tarefas, mas ainda não há uma orientação clara sobre como escolher a incorporação certa ou quando mudar para outra. Com isso em mente, uma equipe de pesquisadores da Tianjin Polytechnic University, na China, desenvolveu recentemente uma nova arquitetura CNN baseada em tipos de representação normalmente usados em tarefas de classificação de texto.
“Nós propomos uma nova arquitetura da CNN baseada em múltiplas representações para classificação de texto através da construção de múltiplos planos para que mais informações possam ser despejadas nas redes, como diferentes partes do texto obtidas por meio de um reconhecedor de entidade nomeada ou ferramentas de marcação de classes gramaticais, diferentes níveis de incorporação de texto ou frases contextuais, "escreveram os pesquisadores em seu artigo.
O modelo multi-representacional CNN (Mr-CNN) desenvolvido pelos pesquisadores é baseado na suposição de que todas as partes do texto escrito (por exemplo, substantivos, verbos, etc.) desempenham um papel fundamental nas tarefas de classificação e que diferentes embeddings de texto são mais eficazes para diferentes fins. Seu modelo combina duas ferramentas principais, o reconhecedor de entidade nomeado de Stanford (NER) e o identificador de classes gramaticais (POS). O primeiro é um método para marcar papéis semânticos de coisas em textos (por exemplo, pessoa, empresa, etc.); a última é uma técnica usada para atribuir marcas de classe gramatical a cada bloco de texto (por exemplo, substantivo ou verbo).
Os pesquisadores usaram essas ferramentas para pré-processar frases, obter vários subconjuntos da frase original, cada um dos quais contém tipos específicos de palavras no texto. Eles então usaram os subconjuntos e a frase completa como múltiplas representações para seu modelo Mr-CNN.
Quando avaliado em tarefas de classificação de texto com texto de vários conjuntos de dados de grande escala e específicos de domínio, o modelo Mr-CNN obteve desempenho notável, com no máximo 13% de melhoria na taxa de erro em um conjunto de dados e 8% em outro. Isso sugere que múltiplas representações de texto permitem que a rede concentre sua atenção de forma adaptativa nas informações mais relevantes, aprimorando suas capacidades de classificação.
"Vários em grande escala, conjuntos de dados específicos de domínio foram usados para validar a arquitetura proposta, "escreveram os pesquisadores." As tarefas analisadas incluem a classificação de documentos ontológicos, categorização de eventos biomédicos, e análise de sentimento, mostrando que CNNs multi-representacionais, que aprendem a focar a atenção em representações específicas de texto, pode obter ganhos adicionais de desempenho em relação aos modelos de rede neural profunda de última geração. "
Em seu trabalho futuro, os pesquisadores planejam investigar se recursos de baixa granularidade podem ajudar a evitar o sobreajuste do conjunto de dados de treinamento. Eles também querem explorar outros métodos que podem aprimorar a análise de partes específicas das frases, potencialmente melhorando ainda mais o desempenho do modelo.
© 2019 Science X Network