Crédito:arXiv:1905.09773 [cs.CV]
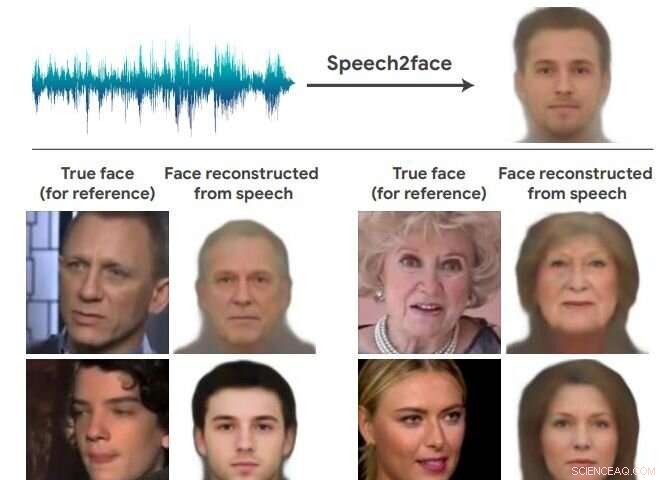
Mais uma vez, equipes de inteligência artificial exploram o reino do impossível e apresentam resultados surpreendentes. Esta equipe no noticiário descobriu como pode ser o rosto de uma pessoa apenas com base na voz. Bem-vindo ao Speech2Face. A equipe de pesquisa encontrou uma maneira de reconstruir a semelhança muito grosseira de algumas pessoas com base em pequenos clipes de áudio.
O artigo que descreve o trabalho deles está disponível no arXiv, e é intitulado "Speech2Face:Aprendendo o rosto por trás de uma voz." Os autores são Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William Freemany, Michael Rubinstein e Wojciech Matusiky. "Nosso objetivo neste trabalho é estudar até que ponto podemos inferir a aparência de uma pessoa a partir da maneira como fala."
Eles avaliam e quantificam numericamente como, e de que maneira, suas reconstruções Speech2Face a partir de áudio se assemelham às imagens reais dos alto-falantes.
Os autores aparentemente queriam ter certeza de que sua intenção era clara, não como uma tentativa de ligar vozes a imagens de pessoas específicas que realmente falaram, como "nosso objetivo não é prever uma imagem reconhecível do rosto exato, mas sim para capturar traços faciais dominantes da pessoa que estão correlacionados com a fala de entrada. "
Os autores do GitHub disseram que também acharam importante discutir no artigo as considerações éticas "devido ao potencial de sensibilidade das informações faciais".
Eles disseram em seu artigo que seu método "não pode recuperar a verdadeira identidade de uma pessoa a partir de sua voz (ou seja, uma imagem exata de seu rosto). Isso ocorre porque nosso modelo é treinado para capturar recursos visuais (relacionados à idade, Gênero sexual, etc.) que são comuns a muitos indivíduos, e apenas nos casos em que há evidências fortes o suficiente para conectar esses recursos visuais com atributos vocais / de fala nos dados. "
Eles também disseram que o modelo produzirá rostos de aparência média - apenas rostos de aparência média - com características visuais correlacionadas com a fala de entrada.
Jackie Snow, Fast Company , escreveu sobre seu método. Snow disse que o conjunto de dados que eles pegaram era composto de clipes do YouTube. O Speech2Face foi treinado por cientistas em vídeos da internet que mostravam pessoas conversando. Eles criaram um modelo baseado em rede neural que "aprende os atributos vocais associados às características faciais dos vídeos".
Neve adicionada, "Agora, quando o sistema ouve um novo som, a IA pode usar o que aprendeu para adivinhar a aparência do rosto. "
Neurohive discutiram o trabalho deles:"Dos vídeos, eles extraem pares de fala, que são alimentados em dois ramos da arquitetura. As imagens são codificadas em um vetor latente usando o modelo de reconhecimento facial pré-treinado, enquanto a forma de onda é alimentada em um codificador de voz na forma de um espectrograma, a fim de utilizar o poder das arquiteturas convolucionais. O vetor codificado do codificador de voz é alimentado no decodificador de face para obter a reconstrução final da face. "
Também é possível obter um relatório preciso sobre seu método e como eles testaram com um artigo sobre Packt :
"Eles disseram que avaliaram e quantificaram numericamente como seu Speech2Face reconstrói, obtém resultados diretamente do áudio, e como se assemelha às imagens reais do rosto dos alto-falantes. Por esta, eles testaram seu modelo qualitativa e quantitativamente no conjunto de dados AVSpeech e no conjunto de dados VoxCeleb. "
Como suas descobertas podem ajudar os aplicativos do mundo real? Eles disseram, "acreditamos que a previsão de imagens de rosto diretamente por voz pode oferecer suporte a aplicativos úteis, como anexar um representante a chamadas de telefone / vídeo com base na voz do locutor. "
Por que seu trabalho é importante:pense em padrões. "Pesquisas anteriores exploraram métodos para prever idade e sexo a partir da fala, "disse Snow, "mas neste caso, os pesquisadores afirmam que também detectaram correlações com alguns padrões faciais. "
© 2019 Science X Network














