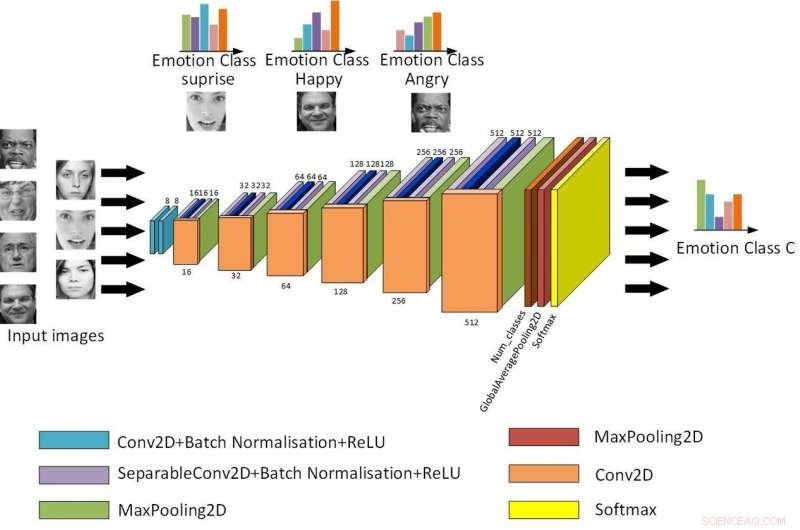
A estrutura básica do Light-CNN. Crédito:Jie &Yongsheng.
Dois pesquisadores da Universidade de Energia Elétrica de Xangai desenvolveram e avaliaram recentemente novos modelos de rede neural para reconhecimento de expressão facial (FER) na natureza. Seu estudo, publicado no jornal Neurocomputing da Elsevier, apresenta três modelos de redes neurais convolucionais (CNNs):um Light-CNN, uma CNN de filial dupla e uma CNN pré-treinada.
“Devido à falta de informação em faces não frontais, FER em estado selvagem é um ponto difícil na visão computacional, "Qian Yongsheng, um dos pesquisadores que realizou o estudo, disse TechXplore. "Os métodos existentes de reconhecimento de expressão facial natural com base em redes neurais convolucionais profundas (CNNs) apresentam vários problemas, incluindo sobreajuste, alta complexidade computacional, recurso único e amostras limitadas. "
Embora muitos pesquisadores tenham desenvolvido abordagens CNN para FER, até aqui, muito poucos deles tentaram determinar que tipo de rede é mais adequado para essa tarefa específica. Ciente dessa lacuna na literatura, Yongsheng e seu colega Shao Jie desenvolveram três CNN diferentes para FER e realizaram uma série de avaliações para identificar seus pontos fortes e fracos.
"Nosso primeiro modelo é um CNN de luz rasa que apresenta um módulo separável em profundidade com o módulo de rede residual, reduzindo os parâmetros de rede alterando o método de convolução, "Yongsheng disse." A segunda é uma CNN de filial dupla, que combina recursos globais e recursos de textura locais, tentando obter recursos mais ricos e compensar a falta de invariância de rotação da convolução. O terceiro CNN pré-treinado usa pesos treinados no mesmo grande banco de dados distribuído para retreinar em seu próprio banco de dados pequeno, reduzindo o tempo de treinamento e melhorando a taxa de reconhecimento. "
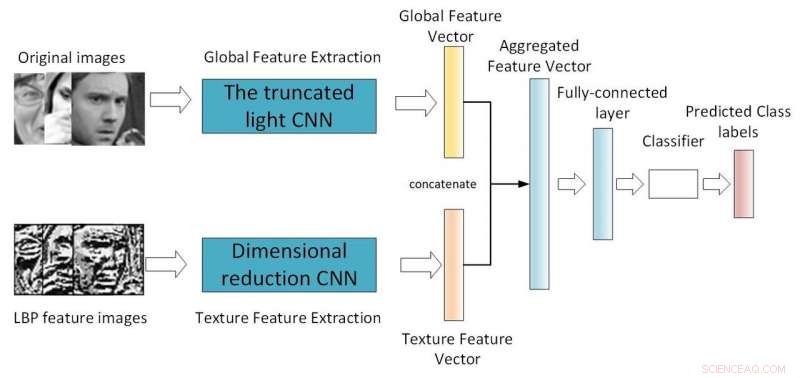
Estrutura da CNN de filial dupla. Crédito:Jie &Yongsheng.
Os pesquisadores realizaram avaliações extensas de seus modelos CNN em três conjuntos de dados que são comumente usados para FER:o CK + público, conjuntos de dados BU-3DEF e FER2013 multi-view. Embora os três modelos da CNN apresentassem diferenças de desempenho, todos eles alcançaram resultados promissores, superando várias abordagens de última geração para FER.
"Atualmente, os três modelos CNN são usados separadamente, "Yongsheng explicou." A rede superficial é mais adequada para hardware embarcado. A CNN pré-treinada pode alcançar melhores resultados, mas requer pesos pré-treinados. A rede de ramificação dupla não é muito eficaz. Claro, também se pode tentar usar os três modelos juntos. "
Em suas avaliações, os pesquisadores observaram que, ao combinar o módulo de rede residual e o módulo separável em profundidade, como fizeram com seu primeiro modelo da CNN, os parâmetros de rede podem ser reduzidos. Isso poderia resolver algumas das deficiências do hardware de computação. Além disso, eles descobriram que o modelo CNN pré-treinado transferiu um grande banco de dados para seu próprio banco de dados e poderia, portanto, ser treinado com amostras limitadas.
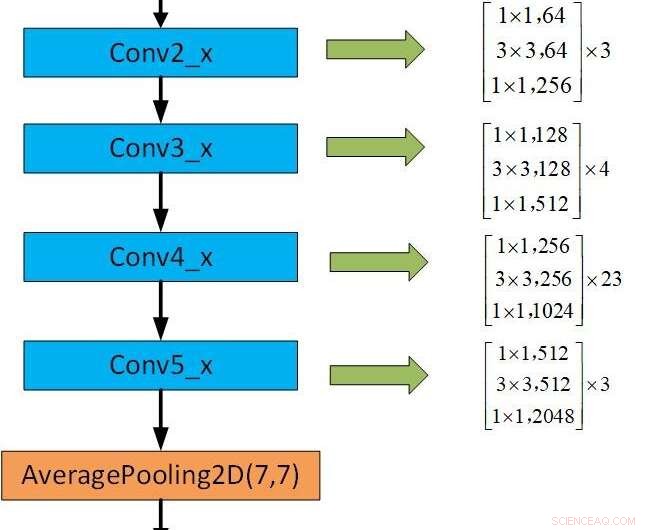
A estrutura da CNN pré-treinada. Crédito:Jie &Yongsheng.
As três CNNs para FER propostas por Yongsheng e Jie podem ter inúmeras aplicações, por exemplo, auxiliando no desenvolvimento de robôs que podem identificar as expressões faciais dos humanos com os quais estão interagindo. Os pesquisadores agora planejam fazer ajustes adicionais em seus modelos, a fim de melhorar ainda mais seu desempenho.
"Em nosso trabalho futuro, tentaremos adicionar diferentes recursos manuais tradicionais para ingressar na CNN de ramificação dupla e alterar o modo de fusão, "Yongsheng disse." Também usaremos parâmetros de rede de treinamento de banco de dados cruzado para obter melhores capacidades de generalização e adotar uma abordagem de aprendizagem de transferência profunda mais eficaz. "
© 2019 Science X Network