Crédito:Liu et al.
Pesquisadores da Universidade de Leiden e da Universidade Nacional de Tecnologia de Defesa (NUDT), na China, desenvolveram recentemente uma nova abordagem para correspondência de imagem e texto, chamado CycleMatch. A abordagem deles, apresentado em um artigo publicado na Elsevier's Reconhecimento de padrões Diário, é baseado na aprendizagem consistente com o ciclo, uma técnica que às vezes é usada para treinar redes neurais artificiais em tarefas de tradução imagem a imagem. A ideia geral por trás da consistência do ciclo é que, ao transformar dados de origem em dados de destino e vice-versa, deve-se finalmente obter as amostras da fonte original.
Quando se trata de desenvolver ferramentas de inteligência artificial (IA) que funcionam bem em tarefas multimodais ou baseadas em multimídia, encontrar maneiras de unir imagens e representações de texto é de crucial importância. Estudos anteriores tentaram alcançar isso descobrindo semânticas ou recursos que são relevantes para a visão e a linguagem.
Ao treinar algoritmos em correlações entre diferentes modalidades, Contudo, esses estudos frequentemente negligenciaram ou falharam em abordar a consistência semântica intra-modal, que é a consistência da semântica para as modalidades individuais (ou seja, visão e linguagem). Para resolver esta lacuna, a equipe de pesquisadores da Universidade de Leiden e NUDT propôs uma abordagem que aplica embeddings consistentes de ciclo a uma rede neural profunda para corresponder representações visuais e textuais.
"Nossa abordagem, nomeado como CycleMatch, pode manter ambas as correlações intermodais e a consistência intra-modal ao colocar em cascata mapeamentos duais e mapeamentos reconstruídos de uma forma cíclica, "os pesquisadores escreveram em seu artigo." Além disso, a fim de alcançar uma inferência robusta, propomos o emprego de duas abordagens de fusão tardia:fusão média e fusão adaptativa. "
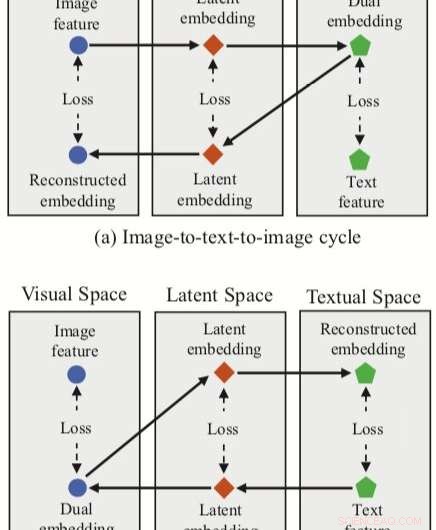
A abordagem desenvolvida pelos pesquisadores integra três embeddings de recursos (dual, embeddings reconstruídos e latentes) com uma rede neural para correspondência de imagem-texto. O método tem dois ramos de ciclo, um partindo de um recurso de imagem no espaço visual e outro de um recurso de texto no espaço textual.
Para cada um desses ciclos, sua abordagem alcança um mapeamento duplo, traduzir um recurso de entrada no espaço de origem em uma incorporação dupla no espaço de destino. Os pesquisadores então aplicam o mapeamento reconstruído, tentando traduzir essa dupla incorporação de volta ao espaço de origem.
Sua abordagem também permite que os pesquisadores adquiram um "espaço latente" durante os mapeamentos duais e reconstruídos, e subsequentemente correlacionar embeddings latentes. Ao contrário de outras técnicas de correspondência de imagem e texto, Portanto, seu método pode aprender mapeamentos intermodais (ou seja, imagem para texto e texto para imagem) e mapeamentos intramodais (imagem para imagem e texto para texto).
Para avaliar sua abordagem, os pesquisadores realizaram uma série de experimentos usando dois conjuntos de dados multimodais renomados, Flickr30K e MSCOCO. Seu método alcançou resultados de última geração, superando as abordagens tradicionais e levando a melhorias significativas na recuperação modal.
Essas descobertas sugerem que os embeddings consistentes com o ciclo podem melhorar o desempenho das redes neurais em tarefas multimodais, como correspondência imagem-texto, permitindo-lhes adquirir mapeamentos intermodais e intramodais. Em seu trabalho futuro, os pesquisadores planejam desenvolver ainda mais sua abordagem, levando em consideração as relações locais na correspondência de imagens e texto (por exemplo, correlações semânticas entre regiões visuais e frases).
© 2019 Science X Network