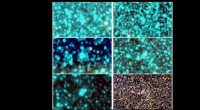
O laboratório dos pesquisadores, como visto pelo sensor de visão dinâmico. Crédito:Grupo de Percepção e Robótica, University of Maryland.
José Altuve, do Houston Astros, chega à mesa com uma contagem de 3-2, estuda o arremessador e a situação, obtém o sinal verde da terceira base, rastreia o lançamento da bola, balanços ... e obtém um único no meio. Apenas mais uma viagem ao prato do tricampeão de rebatidas da Liga Americana.
Um robô poderia ser atingido na mesma situação? Não é provável.
Altuve aprimorou os reflexos naturais, anos de experiência, conhecimento das tendências do arremessador, e uma compreensão das trajetórias de vários arremessos. O que ele vê, ouve, e a sensação combina perfeitamente com sua memória cerebral e muscular para cronometrar o swing que produz o golpe. O robô, por outro lado, precisa usar um sistema de ligação para coordenar lentamente os dados de seus sensores com os recursos do motor. E não consegue se lembrar de nada. Golpeie três!
Mas pode haver esperança para o robô. Um artigo de pesquisadores da Universidade de Maryland recém-publicado na revista Ciência Robótica apresenta uma nova maneira de combinar a percepção e os comandos motores usando a chamada teoria da computação hiperdimensional, que poderia alterar e melhorar fundamentalmente a tarefa básica de inteligência artificial (IA) de representação sensório-motora - como agentes como robôs traduzem o que sentem no que fazem.
"Aprendendo o controle sensório-motor com sensores neuromórficos:em direção à percepção ativa hiperdimensional" foi escrito por Ph.D. em ciência da computação. alunos Anton Mitrokhin e Peter Sutor, Jr .; Cornelia Fermüller, um cientista pesquisador associado do Instituto de Estudos Avançados de Computação da Universidade de Maryland; e o professor de ciência da computação Yiannis Aloimonos. Mitrokhin e Sutor são aconselhados por Aloimonos.
A integração é o desafio mais importante que o campo da robótica enfrenta. Os sensores de um robô e os atuadores que o movem são sistemas separados, ligados entre si por um mecanismo de aprendizagem central que infere uma ação necessária, dados os dados do sensor, ou vice-versa.
O complicado sistema de IA de três partes - cada parte falando seu próprio idioma - é uma maneira lenta de fazer com que os robôs realizem tarefas sensório-motoras. O próximo passo na robótica será integrar as percepções de um robô com suas capacidades motoras. Esta fusão, conhecido como "percepção ativa, "forneceria uma maneira mais eficiente e rápida para o robô concluir as tarefas.
Na nova teoria da computação dos autores, o sistema operacional de um robô seria baseado em vetores binários hiperdimensionais (HBVs), que existem em um espaço esparso e de dimensão extremamente elevada. Os HBVs podem representar coisas distintas e distintas - por exemplo, uma única imagem, um conceito, um som ou uma instrução; sequências feitas de coisas discretas; e agrupamentos de coisas e sequências discretas. Eles podem explicar todos esses tipos de informação de uma forma significativamente construída, ligando cada modalidade junto em vetores longos de 1s e 0s com dimensões iguais. Neste sistema, possibilidades de ação, entrada sensorial e outras informações ocupam o mesmo espaço, estão no mesmo idioma, e são fundidos, criando uma espécie de memória para o robô.
o Ciência Robótica o papel marca a primeira vez que percepção e ação foram integradas.
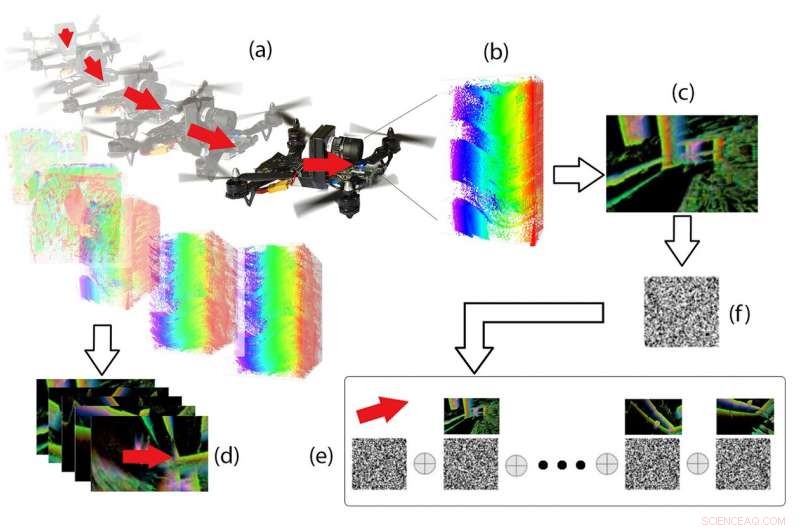
Pipeline hiperdimensional. A partir dos dados do evento (b) registrados no DVS durante o voo do drone (a), "Imagens de eventos" (c) e vetores de movimento 3D (d) são calculados, e ambos são codificados como vetores binários e combinados na memória por meio de operações vetoriais especiais (e). Dada uma nova imagem de evento (f), o movimento 3D associado pode ser recuperado da memória. Crédito:Grupo de Percepção e Robótica, University of Maryland.
Uma estrutura hiperdimensional pode transformar qualquer sequência de "instantes" em novos HBVs, e agrupar HBVs existentes, todos no mesmo comprimento vetorial. Esta é uma maneira natural de criar "memórias" semanticamente significativas e informadas. A codificação de mais e mais informações, por sua vez, leva a vetores de "história" e à capacidade de lembrar. Os sinais se tornam vetores, indexar se traduz em memória, e a aprendizagem acontece por meio de agrupamento.
As memórias do robô sobre o que sentiu e fez no passado podem levá-lo a esperar uma percepção futura e influenciar suas ações futuras. Essa percepção ativa permitiria ao robô se tornar mais autônomo e mais capaz de completar tarefas.
"Um observador ativo sabe por que deseja sentir, então escolhe o que perceber, e determina como, quando e onde alcançar a percepção, "diz Aloimonos." Ele seleciona e fixa as cenas, momentos no tempo, e episódios. Em seguida, ele alinha seus mecanismos, sensores, e outros componentes para agir de acordo com o que deseja ver, e seleciona pontos de vista para melhor capturar o que pretende. "
"Nossa estrutura hiperdimensional pode atender a cada um desses objetivos."
As aplicações da pesquisa de Maryland podem se estender muito além da robótica. O objetivo final é ser capaz de fazer IA em si de uma maneira fundamentalmente diferente:de conceitos a sinais e linguagem. A computação hiperdimensional pode fornecer um modelo alternativo mais rápido e eficiente para a rede neural iterativa e métodos de IA de aprendizagem profunda atualmente usados em aplicativos de computação, como mineração de dados, reconhecimento visual e tradução de imagens em texto.
"Os métodos de IA baseados em rede neural são grandes e lentos, porque eles não são capazes de se lembrar, "diz Mitrokhin." Nosso método de teoria hiperdimensional pode criar memórias, o que exigirá muito menos computação, e deve tornar essas tarefas muito mais rápidas e eficientes. "
Melhor detecção de movimento é uma das melhorias mais importantes necessárias para integrar a detecção de um robô com suas ações. Usar um sensor de visão dinâmico (DVS) em vez de câmeras convencionais para essa tarefa tem sido um componente chave para testar a teoria da computação hiperdimensional.
Câmeras digitais e técnicas de visão por computador capturam cenas com base em pixels e intensidades em quadros que só existem "no momento". Eles não representam bem o movimento porque o movimento é uma entidade contínua.
Um DVS opera de maneira diferente. Não "tira fotos" no sentido usual, mas mostra uma construção diferente da realidade que é adequada aos propósitos dos robôs que precisam lidar com o movimento. Ele captura a ideia de ver o movimento, particularmente as bordas dos objetos à medida que se movem. Também conhecido como "retina de silício, "este sensor inspirado na visão dos mamíferos registra de forma assíncrona as mudanças de iluminação que ocorrem em cada pixel DVS. O sensor acomoda uma grande variedade de condições de iluminação, do escuro ao claro, e pode resolver movimentos muito rápidos em baixa latência - propriedades ideais para aplicações em tempo real em robótica, como a navegação autônoma. Os dados que ele acumula são muito mais adequados ao ambiente integrado da teoria da computação hiperdimensional.
Um DVS registra um fluxo contínuo de eventos, onde um evento é gerado quando um pixel individual detecta uma certa mudança predefinida no logaritmo da intensidade da luz. Isso é realizado por circuitos analógicos integrados em cada pixel, e cada evento é relatado com sua localização de pixel e registro de data e hora de precisão de microssegundo.
"Os dados deste sensor, as nuvens de eventos, são muito mais esparsos do que sequências de imagens, "diz Cornelia Fermüller, um dos autores do artigo Science Robotics. "Além disso, as nuvens de eventos contêm as informações essenciais para a codificação de espaço e movimento, conceitualmente os contornos da cena e seu movimento. "
Fatias de nuvens de eventos são codificadas como vetores binários. Isso torna o DVS uma boa ferramenta para implementar a teoria da computação hiperdimensional para fundir a percepção com as habilidades motoras.
Um DVS vê eventos esparsos no tempo, fornecendo informações densas sobre as mudanças em uma cena, e permitindo precisão, percepção rápida e esparsa dos aspectos dinâmicos do mundo. É um sensor diferencial assíncrono onde cada pixel atua como um circuito completamente independente que rastreia as mudanças de intensidade da luz. Quando a detecção de movimento é realmente o tipo de visão necessária, o DVS é a ferramenta de escolha.