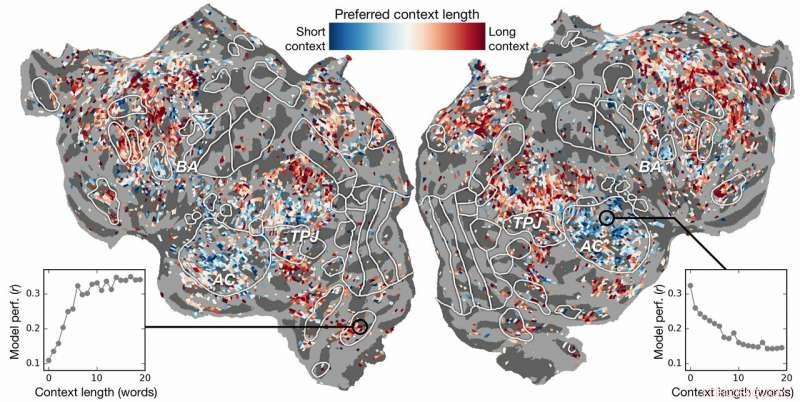
 p Preferência de comprimento de contexto através do córtex. Um índice de preferência de comprimento de contexto é calculado para cada voxel em um sujeito e projetado na superfície cortical desse sujeito. Voxels mostrados em azul são melhor modelados usando contexto curto, enquanto os voxels vermelhos são mais bem modelados com contexto longo. Crédito:Huth lab, UT Austin
p Preferência de comprimento de contexto através do córtex. Um índice de preferência de comprimento de contexto é calculado para cada voxel em um sujeito e projetado na superfície cortical desse sujeito. Voxels mostrados em azul são melhor modelados usando contexto curto, enquanto os voxels vermelhos são mais bem modelados com contexto longo. Crédito:Huth lab, UT Austin
p A inteligência artificial (IA) pode nos ajudar a entender como o cérebro entende a linguagem? A neurociência pode nos ajudar a entender por que a IA e as redes neurais são eficazes em prever a percepção humana? p A pesquisa de Alexander Huth e Shailee Jain da Universidade do Texas em Austin (UT Austin) sugere que ambos são possíveis.
p Em um artigo apresentado na Conferência sobre Sistemas de Processamento de Informação Neural (NeurIPS) de 2018, os estudiosos descreveram os resultados de experimentos que usaram redes neurais artificiais para prever com maior precisão do que nunca como diferentes áreas do cérebro respondem a palavras específicas.
p "À medida que as palavras vêm em nossas cabeças, nós formamos ideias sobre o que alguém está nos dizendo, e queremos entender como isso chega até nós dentro do cérebro, "disse Huth, professor assistente de Neurociência e Ciência da Computação na UT Austin. "Parece que deveria haver sistemas para isso, mas praticamente, não é assim que a linguagem funciona. Como tudo na biologia, é muito difícil reduzir a um simples conjunto de equações. "
p O trabalho empregou um tipo de rede neural recorrente chamada long short-term memory (LSTM) que inclui em seus cálculos as relações de cada palavra com o que veio antes para melhor preservar o contexto.
p "Se uma palavra tem vários significados, você infere o significado dessa palavra para aquela frase em particular, dependendo do que foi dito anteriormente, "disse Jain, um Ph.D. estudante no laboratório de Huth na UT Austin. "Nossa hipótese é que isso levaria a melhores previsões da atividade cerebral porque o cérebro se preocupa com o contexto."
p Parece óbvio, mas por décadas os experimentos da neurociência consideraram a resposta do cérebro a palavras individuais sem uma sensação de sua conexão com cadeias de palavras ou frases. (Huth descreve a importância de fazer "neurociência do mundo real" em um artigo de março de 2019 no
Journal of Cognitive Neuroscience .)
p Em seu trabalho, os pesquisadores realizaram experimentos para testar, e, finalmente, prever, como diferentes áreas do cérebro responderiam ao ouvir histórias (especificamente, hora de rádio da traça). Eles usaram dados coletados de máquinas de fMRI (imagem de ressonância magnética funcional) que capturam mudanças no nível de oxigenação do sangue no cérebro com base em quão ativos são os grupos de neurônios. Isso serve como um correspondente para onde os conceitos de linguagem são "representados" no cérebro.
p Usando poderosos supercomputadores no Texas Advanced Computing Center (TACC), eles treinaram um modelo de linguagem usando o método LSTM para que pudesse prever com eficácia qual palavra viria a seguir - uma tarefa semelhante às pesquisas de autocompletar do Google, em que a mente humana é particularmente adepta.
p "Ao tentar prever a próxima palavra, este modelo tem que aprender implicitamente todas essas outras coisas sobre como a linguagem funciona, "disse Huth, "como quais palavras tendem a seguir outras palavras, sem nunca acessar o cérebro ou quaisquer dados sobre o cérebro. "
p Com base no modelo de linguagem e nos dados de fMRI, eles treinaram um sistema que poderia prever como o cérebro responderia quando ouvisse cada palavra em uma nova história pela primeira vez.
p Esforços anteriores mostraram que é possível localizar respostas de linguagem no cérebro de forma eficaz. Contudo, a nova pesquisa mostrou que adicionar o elemento contextual - neste caso, até 20 palavras anteriores - melhorou significativamente as previsões da atividade cerebral. Eles descobriram que suas previsões melhoram mesmo quando a menor quantidade de contexto é usada. Quanto mais contexto for fornecido, melhor será a precisão de suas previsões.
p "Nossa análise mostrou que se o LSTM incorporar mais palavras, então fica melhor em prever a próxima palavra, "disse Jain, "o que significa que deve incluir informações de todas as palavras do passado."
p A pesquisa foi além. Ele explorou quais partes do cérebro eram mais sensíveis à quantidade de contexto incluída. Eles encontraram, por exemplo, que os conceitos que parecem estar localizados no córtex auditivo eram menos dependentes do contexto.
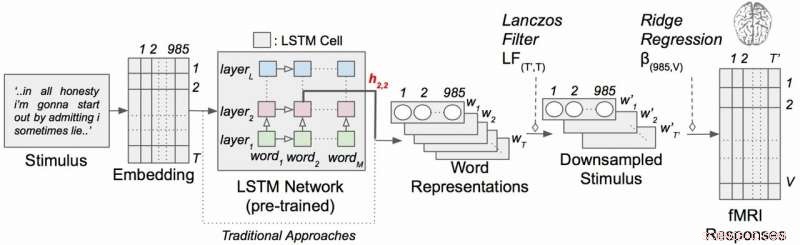 p Modelo de codificação de linguagem contextual com estímulos narrativos. Cada palavra da história é primeiro projetada em um espaço de incorporação de 985 dimensões. As sequências de representações de palavras são então alimentadas em uma rede LSTM que foi pré-treinada como um modelo de linguagem. Crédito:Huth lab, UT Austin
p Modelo de codificação de linguagem contextual com estímulos narrativos. Cada palavra da história é primeiro projetada em um espaço de incorporação de 985 dimensões. As sequências de representações de palavras são então alimentadas em uma rede LSTM que foi pré-treinada como um modelo de linguagem. Crédito:Huth lab, UT Austin
p "Se você ouvir a palavra cachorro, esta área não se importa quais foram as 10 palavras antes disso, só vai responder ao som da palavra cachorro ", Huth explicou.
p Por outro lado, as áreas do cérebro que lidam com o pensamento de nível superior eram mais fáceis de identificar quando mais contexto era incluído. Isso apóia as teorias da mente e da compreensão da linguagem.
p "Havia uma correspondência muito boa entre a hierarquia da rede artificial e a hierarquia do cérebro, que achamos interessante, "Huth disse.
p O processamento de linguagem natural - ou PNL - deu grandes passos nos últimos anos. Mas quando se trata de responder a perguntas, tendo conversas naturais, ou analisando os sentimentos em textos escritos, A PNL ainda tem um longo caminho a percorrer. Os pesquisadores acreditam que seu modelo de linguagem desenvolvido com LSTM pode ajudar nessas áreas.
p O LSTM (e redes neurais em geral) funciona atribuindo valores no espaço de alta dimensão a componentes individuais (aqui, palavras) para que cada componente possa ser definido por seus milhares de relacionamentos díspares com muitas outras coisas.
p Os pesquisadores treinaram o modelo de linguagem alimentando-o com dezenas de milhões de palavras retiradas de postagens do Reddit. O sistema deles então fez previsões de como milhares de voxels (pixels tridimensionais) nos cérebros de seis sujeitos responderiam a um segundo conjunto de histórias que nem o modelo nem os indivíduos tinham ouvido antes. Porque eles estavam interessados nos efeitos do comprimento do contexto e no efeito das camadas individuais na rede neural, eles testaram essencialmente 60 fatores diferentes (20 comprimentos de retenção de contexto e três dimensões de camada diferentes) para cada assunto.
p Tudo isso leva a problemas computacionais de enorme escala, exigindo grandes quantidades de poder de computação, memória, armazenar, e recuperação de dados. Os recursos da TACC eram adequados para o problema. Os pesquisadores usaram o supercomputador Maverick, que contém GPUs e CPUs para as tarefas de computação, e Corral, um recurso de armazenamento e gerenciamento de dados, para preservar e distribuir os dados. Ao paralelizar o problema em muitos processadores, eles foram capazes de executar o experimento computacional em semanas, em vez de anos.
p "Para desenvolver esses modelos de forma eficaz, você precisa de muitos dados de treinamento, "Huth disse." Isso significa que você tem que passar por todo o conjunto de dados toda vez que quiser atualizar os pesos. E isso é inerentemente muito lento se você não usar recursos paralelos como os do TACC. "
p Se parece complexo, bem, é.
p Isso está levando Huth e Jain a considerar uma versão mais simplificada do sistema, onde, em vez de desenvolver um modelo de predição de linguagem e depois aplicá-lo ao cérebro, eles desenvolvem um modelo que prevê diretamente a resposta do cérebro. Eles chamam isso de sistema ponta a ponta e é onde Huth e Jain esperam chegar em suas pesquisas futuras. Esse modelo melhoraria seu desempenho diretamente nas respostas cerebrais. Uma previsão incorreta da atividade cerebral seria um feedback para o modelo e estimularia melhorias.
p "Se funcionar, então é possível que esta rede possa aprender a ler texto ou linguagem de entrada de forma semelhante a como nossos cérebros fazem, "Huth disse." Imagine o Google Translate, mas entende o que você está dizendo, em vez de apenas aprender um conjunto de regras. "
p Com esse sistema instalado, Huth acredita que é apenas uma questão de tempo até que um sistema de leitura de mentes que possa traduzir a atividade cerebral em linguagem seja viável. Enquanto isso, eles estão obtendo insights sobre neurociência e inteligência artificial com seus experimentos.
p "O cérebro é uma máquina de computação muito eficaz e o objetivo da inteligência artificial é construir máquinas que sejam realmente boas em todas as tarefas que um cérebro pode realizar, "Jain disse." Mas, não entendemos muito sobre o cérebro. Então, tentamos usar a inteligência artificial para primeiro questionar como o cérebro funciona, e então, com base nas percepções que obtemos por meio desse método de interrogatório, e através da neurociência teórica, usamos esses resultados para desenvolver uma melhor inteligência artificial.
p "A ideia é entender os sistemas cognitivos, biológico e artificial, e usá-los em conjunto para compreender e construir máquinas melhores. "














