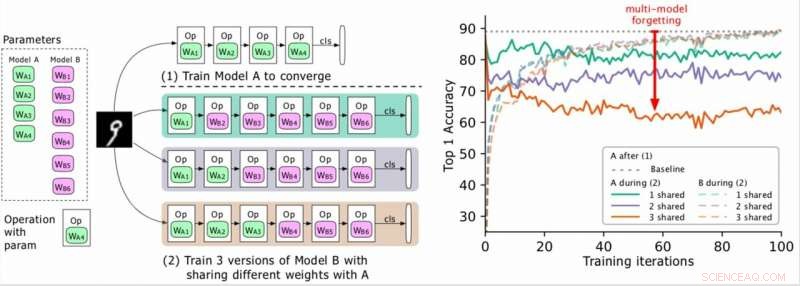
(Esquerda) Dois modelos a serem treinados (A, B), onde os parâmetros de A estão em verde e B em roxo, e B compartilha alguns parâmetros com A (indicado em verde durante a fase 2). Os pesquisadores primeiro treinam A para a convergência e, em seguida, treinam B. (Direita) Precisão do modelo A conforme o treinamento de B avança. As diferentes cores correspondem a diferentes números de camadas compartilhadas. A precisão de A diminui drasticamente, especialmente quando mais camadas são compartilhadas, e os pesquisadores referem-se à queda (a seta vermelha) como esquecimento de modelos múltiplos. Crédito:Benyahia, Yu et al.
Nos últimos anos, pesquisadores desenvolveram redes neurais profundas que podem realizar uma variedade de tarefas, incluindo tarefas de reconhecimento visual e processamento de linguagem natural (PNL). Embora muitos desses modelos tenham alcançado resultados notáveis, eles normalmente só funcionam bem em uma tarefa específica devido ao que é conhecido como "esquecimento catastrófico".
Essencialmente, esquecimento catastrófico significa que quando um modelo que foi inicialmente treinado na tarefa A é posteriormente treinado na tarefa B, seu desempenho na tarefa A diminuirá significativamente. Em um artigo pré-publicado no arXiv, pesquisadores da Swisscom e da EPFL identificaram um novo tipo de esquecimento e propuseram uma nova abordagem que poderia ajudar a superá-lo por meio de uma perda de plasticidade de peso estatisticamente justificada.
"Quando começamos a trabalhar em nosso projeto, projetar arquiteturas neurais automaticamente era caro do ponto de vista computacional e inviável para a maioria das empresas, "Yassine Benyahia e Kaicheng Yu, os investigadores principais do estudo, disse TechXplore por e-mail. "O objetivo original do nosso estudo era identificar novos métodos para reduzir essa despesa. Quando o projeto começou, um artigo do Google afirmou ter reduzido drasticamente o tempo e os recursos necessários para construir arquiteturas neurais usando um novo método chamado compartilhamento de peso. Isso tornou o autoML viável para pesquisadores sem grandes clusters de GPU, encorajando-nos a estudar este tópico com mais profundidade. "
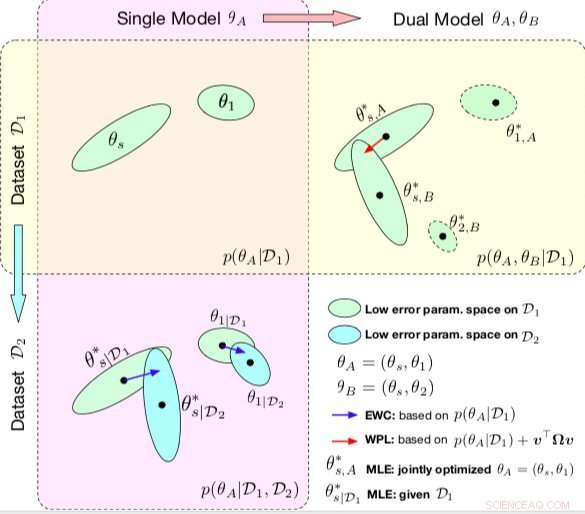
Comparação entre EWC e WPL. As elipses em cada subparcela representam regiões de parâmetro correspondentes ao erro baixo. (Canto superior esquerdo) Ambos os métodos começam com um único modelo, com parâmetros θA ={θs, θ1}, treinado em um único conjunto de dados D1. (Embaixo à esquerda) O EWC regulariza todos os parâmetros com base em p (θA | D1) para treinar o mesmo modelo inicial em um novo conjunto de dados D2. (Canto superior direito) Em contraste, WPL faz uso do conjunto de dados inicial D1 e regulariza apenas os parâmetros compartilhados θs com base em ambos p (θA | D1) ev> Ωv, enquanto os parâmetros θ2 podem se mover livremente. Crédito:Benyahia, Yu et al.
Durante sua pesquisa em modelos baseados em redes neurais, Benyahia, Yu e seus colegas notaram um problema com o compartilhamento de peso. Quando eles treinaram dois modelos (por exemplo, A e B) sequencialmente, o desempenho do modelo A diminuiu, enquanto o desempenho do modelo B aumentou, ou vice-versa. Eles mostraram que este fenômeno, que eles chamam de "esquecimento multi-modelo, "pode prejudicar o desempenho de várias abordagens de auto-mL, incluindo a pesquisa de arquitetura neural eficiente do Google (ENAS).
"Percebemos que a divisão de peso estava fazendo com que os modelos impactassem uns aos outros negativamente, que estava fazendo com que o processo de pesquisa de arquitetura ficasse mais próximo do aleatório, "Benyahia e Yu explicaram." Também tínhamos nossas reservas na pesquisa de arquitetura, onde apenas os resultados finais são revelados e onde não existe um bom framework para avaliar a qualidade da pesquisa de arquitetura de uma forma justa. Nossa abordagem pode ajudar a resolver esse problema de esquecimento, já que está relacionado a um método central do qual quase todos os artigos autoML recentes dependem, e consideramos esse impacto enorme para a comunidade. "
Em seu estudo, os pesquisadores modelaram o multi-modelo esquecendo matematicamente e derivaram uma nova perda, chamada de perda de plasticidade de peso. Essa perda poderia reduzir o esquecimento de multimodelos substancialmente, regularizando o aprendizado dos parâmetros compartilhados de um modelo de acordo com sua importância para os modelos anteriores.
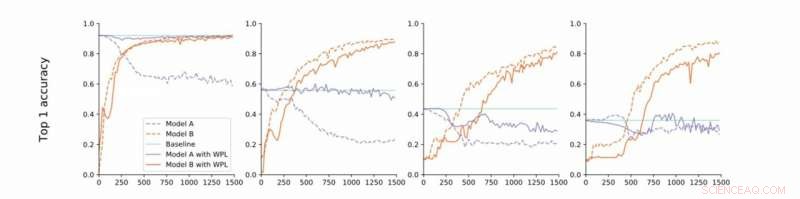
De convergência estrita a frouxa. Os pesquisadores realizam experimentos no MNIST com os modelos A e B com parâmetros compartilhados e relatam a precisão do Modelo A antes de treinar o Modelo B (linha de base, verde) e a precisão dos Modelos A e B durante o treinamento do Modelo B com (laranja) ou sem (azul) WPL. Em (a) eles mostram os resultados para convergência estrita:A é inicialmente treinado para convergência. Eles então relaxam essa suposição e treinam A para cerca de 55% (b), 43% (c), e 38% (d) de sua precisão ideal. O WPL é altamente eficaz quando A é treinado para pelo menos 40% da otimização; abaixo, as informações de Fisher tornam-se muito imprecisas para fornecer pesos de importância confiáveis. Assim, o WPL ajuda a reduzir o esquecimento de vários modelos, mesmo quando os pesos não são ideais. WPL reduziu o esquecimento em até 99,99% para (a) e (b), e em até 2% para (c). Crédito:Benyahia, Yu et al.
"Basicamente, devido à parametrização excessiva de redes neurais, nossa perda diminui os parâmetros que são "menos importantes" para a perda final primeiro, e mantém os mais importantes inalterados, "Benyahia e Yu disseram." Portanto, o desempenho do Modelo A não é afetado, enquanto o desempenho do modelo B continua aumentando. Em pequenos conjuntos de dados, nosso modelo pode reduzir o esquecimento em até 99 por cento, e em métodos autoML, até 80 por cento no meio do treinamento. "
Em uma série de testes, os pesquisadores demonstraram a eficácia de sua abordagem para diminuir o esquecimento de modelos múltiplos, tanto em casos onde dois modelos são treinados sequencialmente quanto para pesquisa de arquitetura neural. Suas descobertas sugerem que adicionar plasticidade de peso na pesquisa de arquitetura neural pode melhorar significativamente o desempenho de vários modelos em tarefas de PNL e visão computacional.
O estudo realizado por Benyahia, Yu e seus colegas lançam luz sobre a questão do esquecimento catastrófico, particularmente o que ocorre quando vários modelos são treinados sequencialmente. Depois de modelar este problema matematicamente, os pesquisadores introduziram uma solução que poderia superá-lo, ou pelo menos reduzir drasticamente seu impacto.
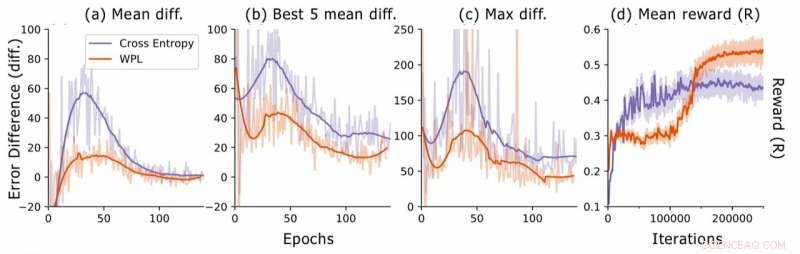
Diferença de erro durante a pesquisa de arquitetura neural. Para cada arquitetura, os pesquisadores calculam as diferenças de erro RNN err2-err1, onde err1 é o erro logo após o treinamento desta arquitetura e err2 aquele após todas as arquiteturas serem treinadas na época atual. Eles traçam (a) a diferença média sobre todos os modelos amostrados, (b) a diferença média sobre os 5 modelos com o erro 1 mais baixo, e (c) a diferença máxima entre todos os modelos. Em (d), eles representam a recompensa média das arquiteturas amostradas como uma função das iterações de treinamento. Embora o WPL inicialmente leve a recompensas mais baixas, devido a um grande peso α na equação (8), reduzindo o esquecimento posterior permite que o controlador experimente melhores arquiteturas, conforme indicado pela recompensa mais alta no segundo semestre. Crédito:Benyahia, Yu et al.
"No esquecimento de modelos múltiplos, nosso princípio orientador era pensar em fórmulas e não apenas por simples intuição ou heurística, "Benyahia e Yu disseram." Acreditamos fortemente que este 'pensamento em fórmulas' pode levar os pesquisadores a grandes descobertas. É por isso que, para pesquisas futuras, pretendemos aplicar essa abordagem a outros campos do aprendizado de máquina. Além disso, planejamos adaptar nossa perda aos métodos autoML de última geração para demonstrar sua eficácia na solução do problema de divisão de peso observado por nós. "
© 2019 Science X Network