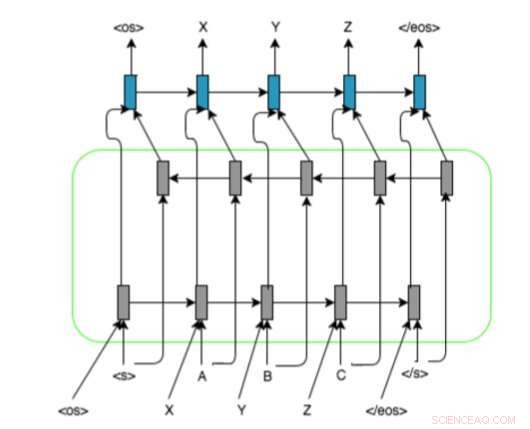
A arquitetura do modelo baseado em RNN dos pesquisadores com LSTM bidirecional codificador-decodificador e representação de alinhamento nas sequências de entrada. Eles usam e, , e marcadores para preencher as sequências de grafemas / fonemas em um comprimento fixo. Crédito:Ngoc Tan Le et al.
Uma equipe de pesquisadores da Universite du Quebec a Montreal e da Universidade Nacional do Vietnã Ho Chi Minh (VNU-HCM) desenvolveu recentemente uma abordagem para transliteração por máquina baseada em redes neurais recorrentes (RNNs). A transliteração envolve a tradução fonética de palavras em um determinado idioma de origem (por exemplo, francês) em palavras equivalentes em um idioma de destino (por exemplo, vietnamita).
Por transliteração, uma palavra individual é transformada em uma palavra foneticamente equivalente em outro sistema de escrita. Essa transformação normalmente depende de um grande conjunto de regras definidas por linguistas, que determinam como os fonemas estão alinhados, considerando a origem de uma palavra e o sistema fonológico da língua-alvo.
Nos últimos anos, pesquisadores desenvolveram várias abordagens de aprendizagem profunda para tradução automática, que foram consideradas uma alternativa valiosa às abordagens estatísticas existentes. Esses resultados promissores motivaram a equipe de pesquisadores da Universite du Quebec a Montreal e VNU-HCM a desenvolver uma abordagem de aprendizado profundo para a transliteração automática.
Sua abordagem usa redes neurais recorrentes (RNNs), visto que estes são particularmente úteis para lidar com problemas semelhantes. Os pesquisadores observaram que a maioria dos métodos grafema-para-fonema de última geração baseava-se principalmente no uso de mapeamentos grafema-fonema, enquanto os RNNs não requerem nenhuma informação de alinhamento.
"Modelos de grafema para fonema são componentes-chave no reconhecimento automático de voz e sistemas de texto para fala, "os pesquisadores explicaram em seu artigo, que foi publicado na ACM Digital Library. "Com pares de idiomas de poucos recursos que não têm léxicos de pronúncia disponíveis e bem desenvolvidos, os modelos grafema-para-fonema são particularmente úteis. Esses modelos são baseados em alinhamentos iniciais entre a origem do grafema e as sequências de destino do fonema. "
Em seu estudo, os pesquisadores introduziram um novo método para alcançar a transliteração automática de poucos recursos, que usa modelos baseados em RNN e informações de alinhamento para sequências de entrada. Dada uma palavra em um determinado idioma que não está presente no dicionário de pronúncia bilíngue, seu sistema pode prever automaticamente sua representação fonêmica no idioma de destino.
"Inspirado por métodos de tradução baseados em rede neural recorrente sequência a sequência, a pesquisa atual apresenta uma abordagem que aplica uma representação de alinhamento para sequências de entrada e embeddings de origem e destino pré-treinados para superar o problema de transliteração para um par de idiomas de poucos recursos, "os pesquisadores explicaram em seu artigo.
Esta nova abordagem combina várias técnicas baseadas em aprendizagem profunda e rede neural, incluindo codificadores-decodificadores, mecanismos de atenção, representação de alinhamento para sequências de entrada e embeddings de origem e destino pré-treinados. Os pesquisadores avaliaram seu método em uma tarefa de transliteração envolvendo pares de línguas franco-vietnamitas de poucos recursos, alcançando resultados muito promissores.
"Avaliação e experimentos envolvendo francês e vietnamita mostraram que, com apenas um pequeno dicionário de pronúncia bilíngue disponível para treinar os modelos de transliteração, resultados promissores foram obtidos, "escreveram os pesquisadores.
De acordo com os pesquisadores, seu estudo foi um dos primeiros a analisar o idioma vietnamita em uma tarefa de transliteração usando RNNs. Seu método alcançou resultados notáveis, superando outras abordagens baseadas em estatísticas e sequências multijuntas de última geração.
O novo sistema desenvolvido pelos pesquisadores pode efetivamente e automaticamente aprender regularidades linguísticas de pequenos dicionários de pronúncia bilíngues. Embora seu estudo o tenha aplicado especificamente a tarefas de transliteração franco-vietnamita, também pode ser estendido a quaisquer outros pares de idiomas de poucos recursos para os quais um dicionário de pronúncia bilíngüe esteja disponível.
"Em trabalhos futuros, pretendemos testar nossa abordagem proposta com um dicionário de pronúncia bilíngue maior, bem como estudar outras abordagens, como semissupervisionado ou não supervisionado, "os pesquisadores escreveram em seu artigo." Também pretendemos investigar a aprendizagem por transferência usando outras tarefas ou linguagens de PNL em ambientes de poucos recursos. "
© 2019 Science X Network