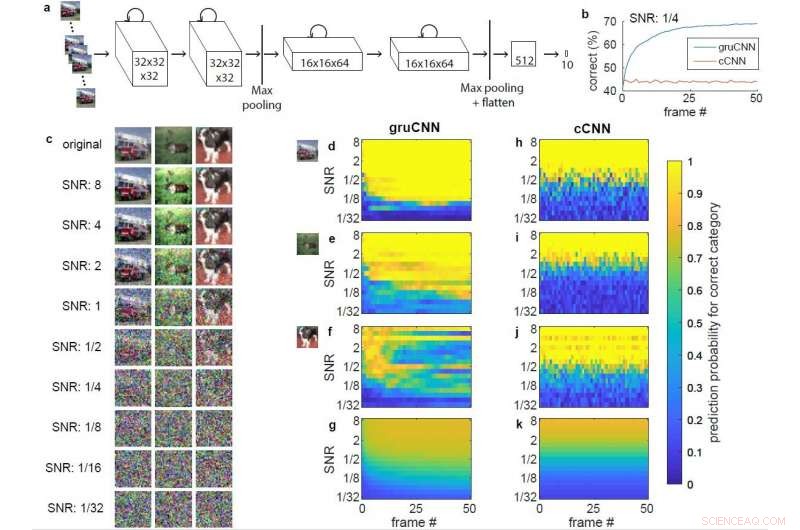
Arquitetura e dados de exemplo. a) Arquitetura do gruCNN. A atividade de cada canal depende tanto da entrada atual quanto do estado anterior. b) Desempenho de classificação do exemplo gruCNN e cCNN quando todas as sequências de teste tiveram um SNR de 1/4. c) Imagem original e imagem com SNRs diferentes para um caminhão de bombeiros (caminhão da categoria) uma rena (cervo da categoria), e um cachorro, mostrado sem jitter. d – k) Probabilidades preditas codificadas por cores (saída de softmax) da categoria de imagem correta (positiva) para gruCNN (d – g) e cCNN (h – k). Os eixos horizontais mostram probabilidades previstas em 51 frames, eixos verticais em uma gama de SNRs. d) &h) e e) &i) correspondem ao desempenho nos exemplos de caminhão de bombeiros e renas, respectivamente. A probabilidade preditiva em SNRs baixos continua melhorando ao longo dos quadros para as previsões gruCNN, mas são relativamente constantes para o cCNN. f) e j) Dados para o terceiro exemplo (o cachorro), em que o gruCNN falha (o que é raro) enquanto o cCNN prediz a categoria corretamente na maioria dos SNRs. A probabilidade média prevista para a categoria de imagem correta (positiva) para todos os 10, 000 imagens de teste são exibidas em g) e k). Crédito:Till S. Hartmann / arXiv:1811.08537 [cs.CV].
Ao longo dos últimos anos, redes neurais convolucionais clássicas (cCNNs) levaram a avanços notáveis na visão computacional. Muitos desses algoritmos agora podem categorizar objetos em imagens de boa qualidade com alta precisão.
Contudo, em aplicativos do mundo real, como direção autônoma ou robótica, os dados de imagem raramente incluem fotos tiradas em condições ideais de iluminação. Muitas vezes, as imagens que as CNNs precisariam para processar objetos ocluídos, distorção de movimento, ou baixas relações de sinal para ruído (SNRs), seja como resultado de imagem de baixa qualidade ou baixos níveis de luz.
Embora os cCNNs também tenham sido usados com sucesso para reduzir o ruído de imagens e melhorar sua qualidade, essas redes não podem combinar informações de vários quadros ou sequências de vídeo e, portanto, são facilmente superadas por humanos em imagens de baixa qualidade. Till S. Hartmann, um pesquisador de neurociência na Harvard Medical School, realizou recentemente um estudo que aborda essas limitações, introduzindo uma nova abordagem da CNN para analisar imagens barulhentas.
Hartmann, que tem formação em neurociência, passou mais de uma década estudando como os humanos percebem e processam informações visuais. Nos últimos anos, ele ficou cada vez mais fascinado pelas semelhanças entre as CNNs profundas usadas na visão computacional e o sistema visual do cérebro.
No córtex visual, área do cérebro especializada no processamento de dados visuais, a maioria das conexões neurais é feita nas direções lateral e de feedback. Isso sugere que o processamento visual é muito mais do que as técnicas empregadas pelos cCNNs. Isso motivou Hartmann a testar camadas convolucionais que incorporam processamento recorrente, que é vital para o processamento de informações visuais do cérebro humano.
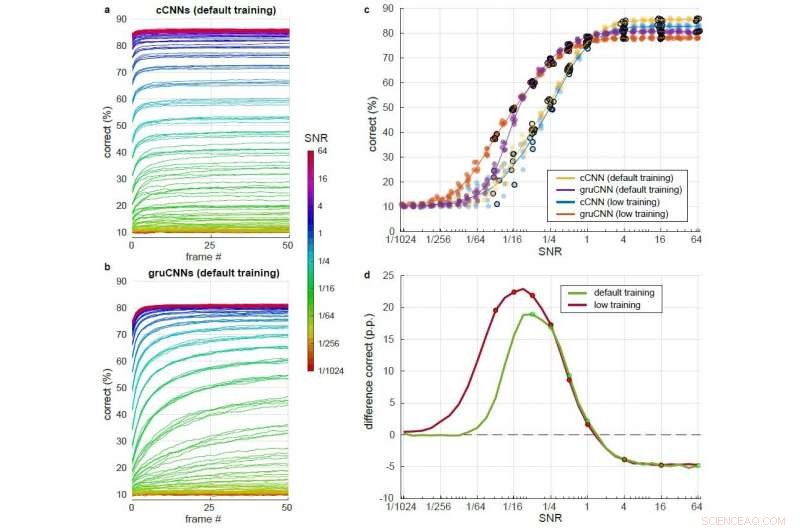
Comparação detalhada de cCNN com inferência Bayesiana e desempenho de gruCNN em uma grande variedade de níveis de SNR. Cada arquitetura de modelo foi testada após o treinamento com SNRs ligeiramente mais elevados (treinamento padrão) e após o treinamento com SNRs ligeiramente mais baixos (treinamento baixo). a) e b) Porcentagem correta ao longo de 51 quadros para SNRs diferentes (codificados por cores) usando o treinamento padrão para a) o cCNN (com inferência Bayesiana) eb) o gruCNN. c) Pontos:classificação correta para as arquiteturas do modelo no último quadro. Jitter nos valores SNR foi adicionado para aumentar a legibilidade dos gráficos, mas não estava nos dados. Linhas:desempenho médio dos cinco modelos por arquitetura. d) Desempenho médio de gruCNNs menos desempenho médio de cCNNs para modelos treinados com padrão e SNRs mais baixos (verde e vermelho, respectivamente). Os níveis de SNR usados durante o treinamento são indicados por pontos. Crédito:Till S. Hartmann / arXiv:1811.08537 [cs.CV].
Usando conexões recorrentes dentro das camadas convolucionais da CNN, A abordagem de Hartmann garante que as redes estejam melhor equipadas para processar ruído de pixel, como aquele presente em imagens tiradas em condições de pouca luz. Quando testado em simulações de sequências de vídeo ruidosas, CNNs recorrentes (gruCNNs) tiveram um desempenho muito melhor do que as abordagens clássicas, classificar com sucesso objetos em vídeos simulados de baixa qualidade, como as tiradas à noite.
Adicionar conexões recorrentes a uma camada convolucional, em última análise, adiciona memória espacialmente restrita, permitindo que a rede aprenda como integrar informações ao longo do tempo antes que o sinal seja muito abstrato. Este recurso pode ser particularmente útil quando há baixa qualidade de sinal, como em imagens com ruído ou tiradas em condições de pouca luz.
Em seu estudo, Hartmann descobriu que os cCNNs tiveram um bom desempenho em imagens com SNRs altos, gruCNNs, superou-os em imagens de baixo SNR. Mesmo adicionando integrações temporais otimizadas de Bayes, que permitem que os cCNNs integrem vários quadros de imagem, não correspondeu ao desempenho do gruCNN. Hartmann também observou que em SNRs baixos, As previsões dos gruCNNs apresentaram níveis de confiança mais elevados do que as produzidas pelos cCNNs.
Embora o cérebro humano tenha evoluído para enxergar na escuridão, a maioria das CNN existentes ainda não está equipada para processar imagens borradas ou com ruído. Ao fornecer às redes a capacidade de integrar imagens ao longo do tempo, a abordagem desenvolvida por Hartmann poderia, eventualmente, melhorar a visão computacional ao ponto que corresponda, ou mesmo excede, desempenho humano. Isso pode ser enorme para aplicações como carros autônomos e drones, bem como em outras situações em que a máquina precisa 'ver' em condições de iluminação não ideais.
O estudo realizado por Hartmann pode abrir caminho para o desenvolvimento de CNNs mais avançadas, capazes de analisar imagens obtidas em condições de pouca luz. O uso de conexões recorrentes nas fases iniciais do processamento da rede neural pode melhorar muito as ferramentas de visão computacional, superando as limitações das abordagens clássicas da CNN no processamento de imagens barulhentas ou fluxos de vídeo.
Como uma próxima etapa, Hartmann poderia expandir o escopo de sua pesquisa, explorando aplicações da vida real de gruCNNs, testá-los em uma ampla gama de cenários do mundo real. Potencialmente, sua abordagem também pode ser usada para melhorar a qualidade de vídeos caseiros amadores ou instáveis.
© 2018 Science X Network














