Começando com o jogo aleatório e sem nenhum conhecimento de domínio, exceto as regras do jogo, AlphaZero derrotou de forma convincente um programa campeão mundial nos jogos de xadrez e shogi (xadrez japonês), bem como no Go. Crédito:DeepMind Technologies Ltd
Uma equipe de pesquisadores com o grupo DeepMind e University College, ambos no Reino Unido, desenvolveu um sistema de IA capaz de aprender a jogar e dominar três difíceis jogos de tabuleiro. Em seu artigo publicado na revista Ciência , o grupo descreve seu novo sistema e explica por que eles acreditam que ele representa mais um grande passo no desenvolvimento de sistemas de IA. Murray Campbell, do T.J Watson Research Center nos EUA, oferece um artigo da Perspectiva sobre o trabalho realizado pela equipe na mesma edição do jornal.
Já se passaram mais de 20 anos desde que um supercomputador conhecido como Deep Blue venceu o campeão mundial de xadrez Gary Kasparov, mostrando ao mundo o quão longe a computação de IA havia chegado. Nos anos desde então, os computadores ficaram cada vez mais inteligentes e agora vencem os humanos em jogos como xadrez, shogi e Go. Mas esses sistemas foram todos ajustados para torná-los realmente bons em apenas um jogo. Neste novo esforço, os pesquisadores criaram um sistema de IA que não é bom apenas em mais de um jogo, mas ganha essa experiência por conta própria.
O novo sistema, chamado AlphaZero, é um sistema de aprendizagem por reforço, que, como o nome indica, significa que aprende jogando repetidamente um jogo e aprendendo com suas experiências. Isto é, claro, muito semelhante a como os humanos aprendem. Um conjunto básico de regras é estabelecido e, em seguida, o computador joga o jogo - consigo mesmo. Nem precisa jogar com outros parceiros. Ele se reproduz repetidamente, observando quais jogadas constituem boas jogadas e, portanto, ganhando, e que constituem movimentos ruins e perdas. Hora extra, Melhora. Eventualmente, torna-se tão bom que pode vencer não apenas os humanos, mas outros sistemas de IA de jogos de tabuleiro dedicados. O sistema também usou um método de pesquisa conhecido como pesquisa por árvore de Monte Carlo. A combinação das duas tecnologias permite que o sistema aprenda a si mesmo como melhorar no jogo. Os pesquisadores deram muito poder ao seu sistema de teste, também, ao empregar 5000 unidades de processamento de tensores, o que o coloca em pé de igualdade com grandes supercomputadores.
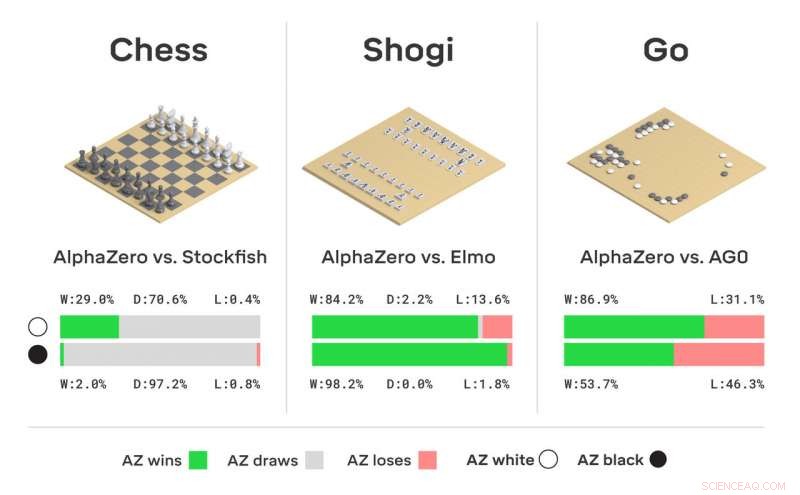
Avaliação de torneio de AlphaZero no xadrez, shogi, e ir, conforme os jogos vencem, desenhado ou perdido da perspectiva do AlphaZero, em partidas contra Stockfish, Elmo, e AlphaGo Zero (AG0) que foi treinado por três dias. Crédito:DeepMind Technologies Ltd
Até agora, AlphaZero domina o xadrez, shogi e Go - jogos que são particularmente adequados para aplicativos de IA. Campbell sugere que o próximo passo para tais sistemas pode ser ramificar em jogos como pôquer, ou mesmo videogames populares.
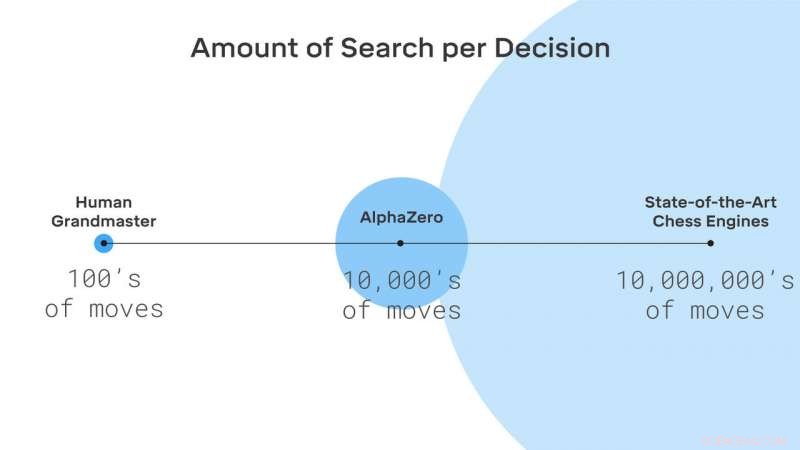
AlphaZero pesquisa apenas uma pequena fração das posições consideradas pelos motores de xadrez tradicionais. Crédito:DeepMind Technologies Ltd
© 2018 Science X Network