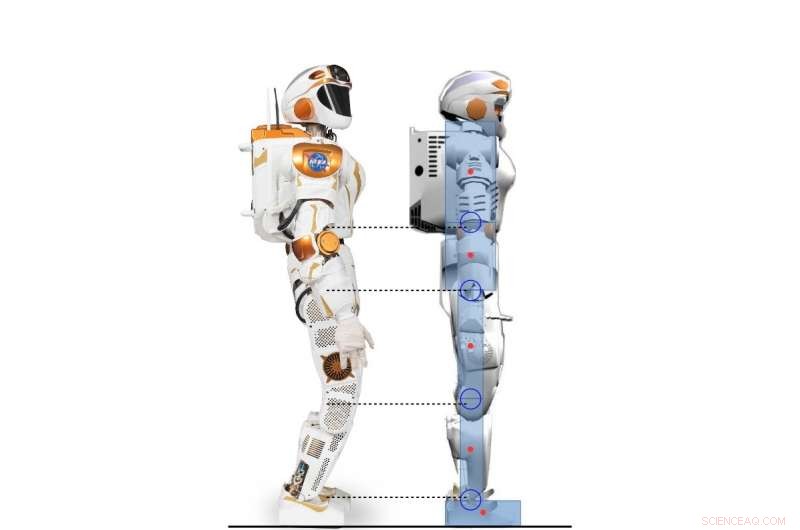
Vista lateral do robô Valkyrie e o personagem humanóide 2D modelado de acordo com o robô Valkyrie. Crédito:Yang, Komura e Li
Pesquisadores da Universidade de Edimburgo desenvolveram uma estrutura hierárquica baseada no aprendizado por reforço profundo (RL) que pode adquirir uma variedade de estratégias para o controle do equilíbrio humanoide. Sua estrutura, descrito em um artigo pré-publicado no arXiv e apresentado na Conferência Internacional de Robótica Humanóide de 2017, poderiam realizar comportamentos de balanceamento muito mais parecidos com os humanos do que os controladores convencionais.
Ao ficar em pé ou caminhando, os seres humanos usam de maneira inata e eficaz várias técnicas de controle insuficiente que os ajudam a manter o equilíbrio. Isso inclui inclinação do dedo do pé e rolamento do calcanhar, que criam uma melhor distância pé-solo. A replicação de comportamentos semelhantes em robôs humanóides pode melhorar muito suas capacidades motoras e de movimento.
"Nossa pesquisa se concentra no uso de RL profundo para resolver a locomoção dinâmica de robôs humanóides, "Dr. Zhibin Li, professor de robótica e controle na Universidade de Edimburgo, quem realizou o estudo, disse TechXplore. "No passado, a locomoção foi feita principalmente usando abordagens analíticas convencionais, baseadas em modelos, que são limitados porque exigem esforço e conhecimento humano, e exigem alto poder de computação para funcionar online. "
Exigindo menos esforço humano e ajuste manual, técnicas de aprendizado de máquina podem levar ao desenvolvimento de controladores mais eficazes e específicos do que as abordagens tradicionais de engenharia. Outra vantagem de usar RL é que a computação para essas ferramentas também pode ser terceirizada offline, resultando em desempenho online mais rápido para sistemas de controle de alta dimensão, como robôs humanóides.

Um robô Valkyrie simulado em pose de inclinação do dedo do pé / calcanhar. Crédito:Yang, Komura e Li
"Dados os algoritmos RL cada vez mais poderosos e profundos, um número crescente de estudos de pesquisa começou a usar RL profundo para resolver tarefas de controle, como o progresso recente em algoritmos RL profundos projetados para domínio de ação contínua trouxe a possibilidade de aplicar tarefas de controle contínuo de aprendizagem por reforço que envolvem dinâmica complicada, "Dr. Li explicou." O objetivo principal de nossa pesquisa foi explorar as possibilidades de usar o aprendizado por reforço profundo para adquirir políticas de controle versáteis comparáveis ou melhores do que as abordagens analíticas, usando menos esforço humano. "
A estrutura desenvolvida pelo Dr. Li, em colaboração com o Dr. Taku Komura e Ph.D. estudante Chuanyu Yang, usa RL profundo para atingir políticas de controle de alto nível. Recebendo constantemente feedback do estado do robô, essas estratégias permitem ângulos articulares desejados em uma frequência mais baixa.
"No nível mais baixo, controladores proporcionais e derivados (PD) são usados em uma frequência de controle muito mais alta para garantir os movimentos estáveis da junta, "O estudante de doutorado Chuanyu disse." As entradas para o controlador PD de baixo nível são os ângulos de articulação desejados produzidos pela rede neural de alto nível, e as saídas são os torques desejados para motores articulados. "
Os pesquisadores testaram o desempenho de seu algoritmo e alcançaram resultados altamente promissores. Eles descobriram que a transferência de conhecimento humano de métodos de engenharia de controle para o projeto de recompensa para algoritmos RL possibilitou estratégias de controle de equilíbrio que se assemelhavam àquelas usadas por humanos. Além disso, à medida que os algoritmos RL melhoram por meio de um processo de tentativa e erro, adaptando-se automaticamente a novas situações, sua estrutura requer pouco ajuste manual ou outras intervenções por engenheiros humanos.
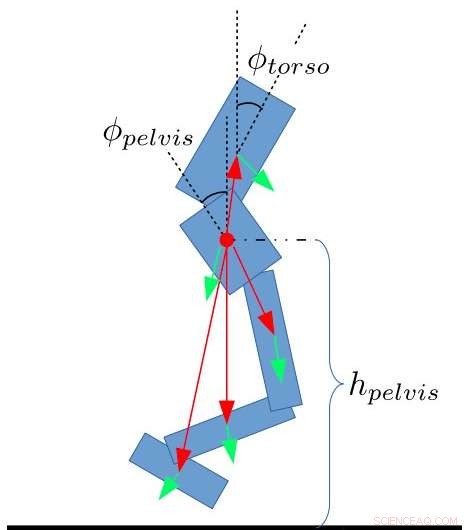
Estado recursos para o bípede. Yang, Komura e Li
"Nosso estudo mostra que o aprendizado por reforço profundo pode ser uma ferramenta poderosa para produzir resultados de balanceamento comparáveis aos de um controlador de engenharia humana com menos esforço de ajuste manual e menor tempo, "Disse o Dr. Li." O algoritmo de aprendizagem por reforço profundo que desenvolvemos é até capaz de aprender comportamentos humanos emergentes, como inclinar os dedos dos pés ou calcanhares, que a maioria dos métodos de engenharia são incapazes de realizar. "
Dr. Li e seus colegas estão agora trabalhando em uma extensão de seu estudo que aplica RL a um robô Valkyrie de corpo inteiro em uma simulação 3-D. Neste novo esforço de pesquisa, eles foram capazes de generalizar estratégias de equilíbrio semelhantes a humanos para caminhadas e outras tarefas de locomoção.
"Eventualmente, gostaríamos de aplicar esta estrutura hierárquica de combinação de aprendizado de máquina e controle de robô a robôs humanóides reais, bem como para outras plataformas robóticas, "Dr. Li disse.
© 2018 Tech Xplore