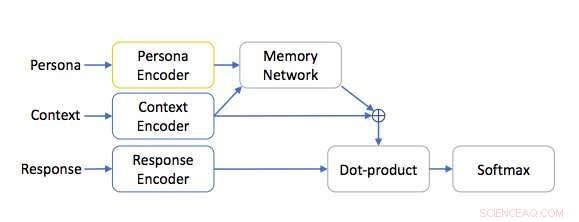
Arquitetura de rede baseada em Persona. Crédito:Mazaré et al.
Pesquisadores do Facebook recentemente compilaram um conjunto de dados de 5 milhões de personas e 700 milhões de diálogos baseados em personas. Este banco de dados pode ser usado para treinar sistemas de diálogo ponta a ponta, resultando em diálogos mais envolventes e ricos entre agentes de computador e humanos.
Sistemas de diálogo, ou agentes conversacionais (CA), são sistemas de computador projetados para se comunicar com seres humanos por meio de texto, Fala, gráficos, ou outros métodos, de uma forma coerente. Até aqui, sistemas de diálogo baseados em arquiteturas neurais, como LSTMs ou redes de memória, foram considerados particularmente promissores na obtenção de comunicação fluente, particularmente quando treinado diretamente em registros de diálogo.
"Uma de suas principais vantagens é que eles podem contar com grandes fontes de dados de diálogos existentes para aprender a cobrir vários domínios sem exigir nenhum conhecimento especializado, "escreveram os pesquisadores em seu artigo, que foi pré-publicado no arXiv. "Contudo, o outro lado é que eles também exibem engajamento limitado, especialmente em configurações de bate-papo:falta consistência e não alavancam estratégias de engajamento proativas como os bots de bate-papo com script (mesmo parcialmente) fazem. "
Em um estudo recente, uma equipe diferente de pesquisadores do Montreal Institute for Learning Algorithms (MILA) e do Facebook AI criou um conjunto de dados chamado PERSONA-CHAT, que inclui diálogos entre agentes com perfis de texto, ou personas, apegado a eles. Eles descobriram que treinar um sistema de diálogo sobre uma determinada pessoa melhorou seu envolvimento nas interações.
"Contudo, o conjunto de dados PERSONA-CHAT foi criado usando um mecanismo de coleta de dados artificial baseado no Mechanical Turk, "os pesquisadores explicaram em seu artigo." Como resultado, nem diálogos nem personas podem ser totalmente representativos das interações reais do usuário-bot e a cobertura do conjunto de dados permanece limitada, contendo um pouco mais de mil personas diferentes. "
Para lidar com as limitações do conjunto de dados compilado anteriormente, os pesquisadores do Facebook criaram um novo, conjunto de dados de diálogo baseado em persona em grande escala, composto por conversas extraídas da plataforma online Reddit. Seu estudo leva o trabalho de seus predecessores um passo adiante, usando interações mais representativas.
"Nesse artigo, construímos um conjunto de dados de diálogo baseado em persona em grande escala usando conversas previamente extraídas do Reddit, "escreveram os pesquisadores." Com heurísticas simples, criamos um corpus de mais de 5 milhões de personas, abrangendo mais de 700 milhões de conversas. "
Para avaliar sua eficácia, os pesquisadores treinaram sistemas de diálogo ponta a ponta baseados em persona em seu conjunto de dados recém-desenvolvido. Sistemas treinados em seu conjunto de dados foram capazes de conduzir conversas mais envolventes, superando outros agentes de conversação que não tiveram acesso a personas durante seu treinamento.
Interessantemente, seu conjunto de dados levou a resultados de última geração, mesmo quando os sistemas de diálogo foram meramente pré-treinados nele. No futuro, essas descobertas podem levar ao desenvolvimento de chatbots mais envolventes, que também pode ser personalizado e treinado para adquirir uma personalidade particular.
"Mostramos que os modelos de treinamento para alinhar as respostas tanto com a personalidade de seu autor quanto com o contexto melhoram o desempenho de previsão, "escreveram os pesquisadores." Como o pré-treinamento leva a uma melhoria considerável no desempenho, trabalhos futuros podem ajustar este modelo para vários sistemas de diálogo. "
© 2018 Tech Xplore