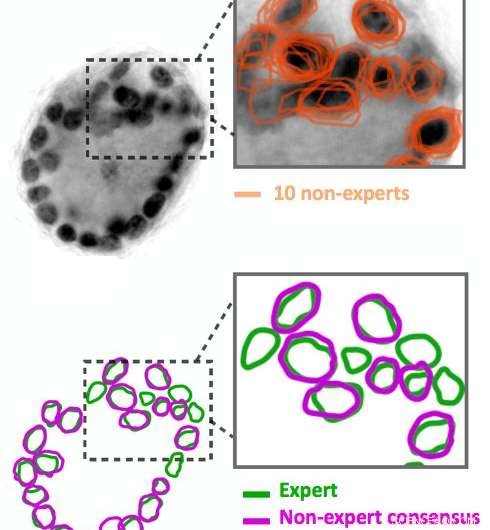
As anotações de imagens não especializadas são ruidosas. Dez não especialistas delinearam os círculos pretos escuros na imagem, que são núcleos celulares. Seus resultados (mostrados em laranja) não correspondem exatamente. Nossos algoritmos são capazes de inferir um contorno de consenso (mostrado em roxo) a partir dos dados ruidosos. Compare este consenso com a anotação de especialista da mesma imagem (mostrada em verde). Crédito:IBM
Hoje, minha equipe IBM e meus colegas do laboratório UCSF Gartner relataram em Métodos da Natureza uma abordagem inovadora para gerar conjuntos de dados de não especialistas e usá-los para treinamento em aprendizado de máquina. Nossa abordagem foi projetada para permitir que os sistemas de IA aprendam tão bem com não especialistas quanto com dados de treinamento gerados por especialistas. Desenvolvemos uma plataforma, chamado Quanti.us, que permite que não especialistas analisem imagens (uma tarefa comum na pesquisa biomédica) e criem um conjunto de dados anotado. A plataforma é complementada por um conjunto de algoritmos projetados especificamente para interpretar corretamente este tipo de dados "ruidosos" e incompletos. Usados juntos, essas tecnologias podem expandir as aplicações de aprendizado de máquina na pesquisa biomédica.
Dados não especialistas e barulhentos
A disponibilidade limitada de conjuntos de dados anotados de alta qualidade é um gargalo no avanço do aprendizado de máquina. Ao criar algoritmos que podem fornecer resultados precisos de anotações de qualidade inferior - e um sistema para coletar esses dados rapidamente - podemos ajudar a aliviar o gargalo. Analisar imagens para recursos de interesse é um ótimo exemplo. A anotação de imagem de especialista é precisa, mas demorada, e técnicas de análise automatizadas, como segmentação baseada em contraste e detecção de bordas, funcionam bem em condições definidas, mas são sensíveis a alterações na configuração experimental e podem produzir resultados não confiáveis.
Entre no crowdsourcing. Usando Quanti.us, Obtivemos anotações de imagens de crowdsourcing de 10 a 50 vezes mais rápido do que seria necessário para um único especialista analisar as mesmas imagens. Mas, como se poderia esperar, as anotações de não especialistas eram ruidosas:alguns identificaram corretamente uma característica e outros estavam fora do alvo. Desenvolvemos algoritmos para processar os dados ruidosos, inferir a localização correta de um recurso a partir da agregação de ocorrências dentro e fora do destino. Quando treinamos uma rede de regressão convolucional profunda usando o conjunto de dados de origem coletiva, teve um desempenho quase tão bom quanto uma rede treinada em anotações de especialistas, no que diz respeito à precisão e recall. Junto com o artigo que descreve nossa abordagem e estratégia, lançamos o código-fonte do nosso algoritmo.
Aplicações em engenharia celular
A análise de imagens é fundamental para muitos campos da biologia quantitativa e da medicina. Há alguns anos, nós e nossos colaboradores anunciamos o Center for Cellular Construction (CCC) financiado pela NSF, um centro de ciência e tecnologia pioneiro na nova disciplina científica da engenharia celular. O CCC facilita a colaboração próxima entre especialistas de diferentes disciplinas, como aprendizado de máquina, física, Ciência da Computação, biologia celular e molecular, e genômica, para impulsionar o progresso na engenharia celular. Nosso objetivo é estudar e criar células que podem ser usadas como máquinas automatizadas, ou sensores ad hoc, para aprender informações novas e vitais sobre uma variedade de entidades biológicas e sua relação com o ambiente em que vivem. Usamos a análise de imagens para localizar a posição e o tamanho dos componentes internos das células. Mas mesmo com técnicas de imagem avançadas, a inferência exata de subestruturas celulares pode ser incrivelmente barulhenta, dificultando a operação dos componentes da célula. Nossa técnica pode usar esses dados ruidosos para prever corretamente onde as estruturas celulares relevantes podem estar, permitindo uma melhor identificação de organelas envolvidas na produção de importantes produtos químicos ou potenciais alvos de drogas em uma doença.
Acreditamos que nossos algoritmos são um primeiro passo importante em direção a plataformas de IA mais complexas. Esses sistemas podem usar paradigmas "humanos no circuito" adicionais, envolvendo um biólogo para corrigir erros durante a fase de treinamento, por exemplo, para melhorar ainda mais o desempenho. Também vemos uma oportunidade de aplicar nosso método além da biologia a outros campos onde conjuntos de dados anotados de alta qualidade podem ser escassos.
Esta história foi republicada por cortesia da IBM Research. Leia a história original aqui.