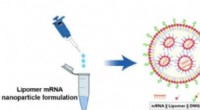
Uma ilustração de estruturas de fluxo intrincadas em turbulência de uma grande simulação realizada usando 1, 024 nós no Summit. O quadro inferior direito mostra uma visão ampliada de uma região de alta atividade. Crédito:Dave Pugmire e Mike Matheson, Oak Ridge National Laboratory
Turbulência, o estado de movimento desordenado do fluido, é um quebra-cabeça científico de grande complexidade. A turbulência permeia muitas aplicações em ciência e engenharia, incluindo combustão, transporte de poluentes, previsão do tempo, astrofísica, e mais. Um dos desafios enfrentados pelos cientistas que simulam turbulência reside na ampla gama de escalas que devem capturar para compreender com precisão o fenômeno. Essas escalas podem abranger várias ordens de magnitude e podem ser difíceis de capturar dentro das restrições dos recursos de computação disponíveis.
A computação de alto desempenho pode enfrentar esse desafio quando combinada com o código científico correto; mas simular fluxos turbulentos em tamanhos de problema além do atual estado da arte requer um novo pensamento em conjunto com plataformas heterogêneas de primeira linha.
Uma equipe liderada por P. K. Yeung, professor de engenharia aeroespacial e engenharia mecânica no Instituto de Tecnologia da Geórgia, realiza simulações numéricas diretas (DNS) de turbulência usando o novo código de sua equipe, GPUs para Simulações de Turbulência em Escala Extrema (GESTS). O DNS pode capturar com precisão os detalhes que surgem de uma ampla variedade de escalas. No início deste ano, a equipe desenvolveu um novo algoritmo otimizado para o supercomputador IBM AC922 Summit no Oak Ridge Leadership Computing Facility (OLCF). Com o novo algoritmo, a equipe atingiu um desempenho de menos de 15 segundos de tempo de relógio de parede por intervalo de tempo para mais de 6 trilhões de pontos de grade no espaço - um novo recorde mundial ultrapassando o estado da arte anterior no campo para o tamanho do problema.
As simulações que a equipe conduz na Summit devem esclarecer questões importantes sobre fluxos de fluidos turbulentos de agitação rápida, que terá um impacto direto na modelagem de fluxos reativos em motores e outros tipos de sistemas de propulsão.
GESTS é um código de dinâmica de fluidos computacional no Center for Accelerated Application Readiness do OLCF, um Departamento de Energia (DOE) dos Estados Unidos para usuários do Office of Science User Facility no Oak Ridge National Laboratory do DOE. No coração do GESTS está um algoritmo matemático básico que calcula em grande escala, transformadas rápidas de Fourier distribuídas (FFTs) em três direções espaciais.
Um FFT é um algoritmo matemático que calcula a conversão de um sinal (ou um campo) de seu domínio de tempo ou espaço original para uma representação no espaço de frequência (ou número de onda) - e vice-versa para a transformação inversa. Yeung aplica extensivamente um grande número de FFTs para resolver com precisão a equação diferencial parcial fundamental da dinâmica dos fluidos, a equação de Navier-Stokes, usando uma abordagem conhecida em matemática e computação científica como "métodos pseudo-espectrais".
A maioria das simulações usando paralelismo maciço baseado em CPU irá particionar um domínio de solução 3-D, ou o volume do espaço onde um fluxo de fluido é calculado, ao longo de duas direções em muitas "caixas de dados longas, "ou" lápis ". No entanto, quando a equipe de Yeung se encontrou em um OLCF GPU Hackathon no final de 2017 com o mentor David Appelhans, um membro da equipe de pesquisa da IBM, o grupo concebeu uma ideia inovadora. Eles combinariam duas abordagens diferentes para resolver o problema. Eles primeiro dividiriam o domínio 3-D em uma direção, formando uma série de "blocos" de dados nas CPUs de grande memória da Summit, em seguida, paralelize ainda mais dentro de cada placa usando as GPUs da Summit.
A equipe identificou as partes mais demoradas de um código de base da CPU e começou a projetar um novo algoritmo que reduziria o custo dessas operações, ultrapasse os limites do maior tamanho de problema possível, e aproveite as características exclusivas centradas em dados da Summit, o supercomputador mais poderoso e inteligente do mundo para ciência aberta.
"Projetamos este algoritmo para ser um paralelismo hierárquico para garantir que funcionaria bem em um sistema hierárquico, "Disse Appelhans." Colocamos até duas lajes em um nó, mas como cada nó tem 6 GPUs, quebramos cada placa e colocamos essas peças individuais em GPUs diferentes. "
No passado, lápis podem ter sido distribuídos entre muitos nós, mas o método da equipe faz uso da comunicação on-node da Summit e sua grande quantidade de memória CPU para encaixar placas de dados inteiras em nós únicos.
"Planejamos originalmente executar o código com a memória residente na GPU, o que nos teria limitado a tamanhos menores de problemas, "Yeung disse." No entanto, no OLCF GPU Hackathon, percebemos que a conexão NVLink entre a CPU e a GPU é tão rápida que poderíamos realmente maximizar o uso dos 512 gigabytes de memória da CPU por nó. "
A constatação levou a equipe a adaptar algumas das partes principais do código (kernels) para movimentação de dados da GPU e processamento assíncrono, que permite que a computação e a movimentação de dados ocorram simultaneamente. Os kernels inovadores transformaram o código e permitiram que a equipe resolvesse problemas muito maiores do que nunca em um ritmo muito mais rápido do que nunca.
O sucesso da equipe provou que mesmo grandes, aplicativos dominados por comunicação podem se beneficiar muito com o supercomputador mais poderoso do mundo quando os desenvolvedores de código integram a arquitetura heterogênea ao design do algoritmo.
Coalescendo em sucesso
Um dos principais ingredientes para o sucesso da equipe foi uma combinação perfeita entre a longa experiência científica de domínio da equipe da Georgia Tech e o pensamento inovador e profundo conhecimento da máquina da Appelhans.
Também crucial para a realização foi o acesso antecipado dos sistemas Ascent e Summitdev do OLCF e uma alocação de milhões de nós-hora na Summit fornecida pelo programa Innovative Novel and Computational Impact on Theory and Experiment (INCITE), gerenciado em conjunto pelas Instalações de Computação de Liderança de Argonne e Oak Ridge, e o Programa Summit Early Science em 2019.
Oscar Hernandez, desenvolvedor de ferramentas no OLCF, ajudou a equipe a enfrentar os desafios ao longo do projeto. Um desses desafios foi descobrir como executar cada processo paralelo único (que obedece ao padrão de interface de passagem de mensagem [MPI]) na CPU em conjunto com várias GPUs. Tipicamente, um ou mais processos MPI estão vinculados a uma única GPU, mas a equipe descobriu que usar várias GPUs por processo MPI permite que os processos MPI enviem e recebam um número menor de mensagens maiores do que o planejado originalmente pela equipe. Usando o modelo de programação OpenMP, Hernandez ajudou a equipe a reduzir o número de tarefas MPI, melhorando o desempenho de comunicação do código e, portanto, levando a mais acelerações.
Kiran Ravikumar, um aluno de doutorado da Georgia Tech no projeto, apresentará detalhes do algoritmo dentro do programa técnico da Conferência de Supercomputação de 2019, SC19.
A equipe planeja usar o código para fazer mais incursões nos mistérios da turbulência; eles também introduzirão outros fenômenos físicos, como mistura oceânica e campos eletromagnéticos no código no futuro.
"Este código, e suas futuras versões, proporcionará oportunidades empolgantes para grandes avanços na ciência da turbulência, com insights de generalidade relacionados à mistura turbulenta em muitos ambientes naturais e projetados, "Yeung disse.