Usando o aprendizado de máquina para auxiliar no projeto molecular. Crédito:Wenbo Sun, Avanços da Ciência, doi:10.1126 / sciadv.aay4275
Para sintetizar materiais de alto desempenho para fotovoltaicos orgânicos (OPVs) que convertem a radiação solar em corrente contínua, os cientistas de materiais devem estabelecer de forma significativa a relação entre as estruturas químicas e suas propriedades fotovoltaicas. Em um novo estudo sobre Avanços da Ciência , Wenbo Sun e uma equipe incluindo pesquisadores da Escola de Energia e Engenharia de Energia, Escola de Automação, Ciência da Computação, Engenharia Elétrica e Tecnologia Verde e Inteligente, estabeleceu um novo banco de dados de mais de 1, 700 materiais de doadores usando relatórios de literatura existentes. Eles usaram o aprendizado supervisionado com modelos de aprendizado de máquina para construir relações estrutura-propriedade e materiais OPV de tela rápida usando uma variedade de entradas para diferentes algoritmos de ML.
Usando impressões digitais moleculares (codificando a estrutura de uma molécula em bits binários) além de um comprimento de 1000 bits, Sun et al. obteve alta precisão de predição de ML. Eles verificaram a confiabilidade da abordagem por meio da triagem de 10 materiais de doadores recém-projetados quanto à consistência entre as previsões do modelo e os resultados experimentais. Os resultados do ML apresentaram uma ferramenta poderosa para pré-selecionar novos materiais OPV e acelerar o desenvolvimento de OPVs na engenharia de materiais.
As células fotovoltaicas orgânicas (OPV) podem facilitar a transformação direta e econômica da energia solar em eletricidade, com um rápido crescimento recente para exceder as taxas de eficiência de conversão de energia (PCE). A pesquisa convencional de OPV tem se concentrado na construção de uma relação entre novas estruturas moleculares de OPV e suas propriedades fotovoltaicas. O processo tradicional normalmente envolve o projeto e a síntese de materiais fotovoltaicos para a montagem / otimização de células fotovoltaicas. Tais abordagens resultam em ciclos de pesquisa demorados que requerem controle delicado de síntese química e fabricação de dispositivos, etapas experimentais e purificação. O processo de desenvolvimento de OPV existente é lento e ineficiente, com menos de 2.000 moléculas doadoras de OPV sintetizadas e testadas até agora. Contudo, os dados coletados em décadas de trabalho de pesquisa não têm preço, com valores potenciais restantes a serem totalmente explorados para gerar materiais OPV de alto desempenho.
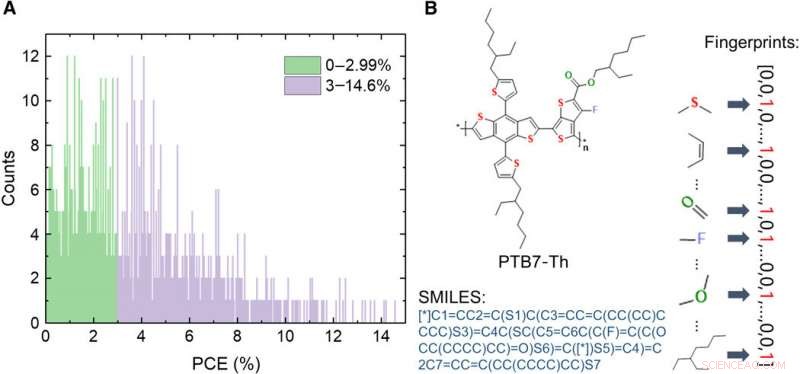
Informações sobre o banco de dados de materiais de doadores de OPV. (A) Distribuição dos valores de PCE das 1719 moléculas no banco de dados. (B) Esquemas de expressões de uma molécula, incluindo imagem, sistema simplificado de entrada de linha de entrada molecular (SMILES), e impressões digitais. Crédito:Science Advances, doi:10.1126 / sciadv.aay4275
Para extrair informações úteis dos dados, Sun et al. exigia um programa sofisticado para varrer um grande conjunto de dados e extrair relacionamentos entre os recursos. Como o aprendizado de máquina (ML) fornece ferramentas computacionais para aprender e reconhecer padrões e relacionamentos usando um conjunto de dados de treinamento, a equipe usou uma abordagem baseada em dados para habilitar o ML e prever diversas propriedades de materiais. O algoritmo de ML não precisava entender a química ou a física por trás das propriedades dos materiais para realizar as tarefas. Métodos semelhantes previram recentemente a atividade / propriedades dos materiais com sucesso durante a descoberta de materiais, desenvolvimento de medicamentos e design de materiais. Antes dos aplicativos de ML, os cientistas geraram quiminformática para estabelecer uma caixa de ferramentas útil.
Cientistas de materiais exploraram recentemente as aplicações do ML no campo de OPV. No presente trabalho, Sun et al. estabeleceu um banco de dados contendo 1.719 materiais de OPV de dadores testados experimentalmente reunidos na literatura. Eles estudaram a importância da expressão da linguagem de programação das moléculas primeiro para entender o desempenho do ML. Eles então testaram vários tipos diferentes de expressões, incluindo imagens, Strings ASCII, dois tipos de descritores e sete tipos de impressões digitais moleculares. Eles observaram que as previsões do modelo estavam de acordo com os resultados experimentais. Os cientistas esperam que a nova abordagem acelere muito o desenvolvimento de novos materiais semicondutores orgânicos altamente eficientes para aplicações de pesquisa de OPV.
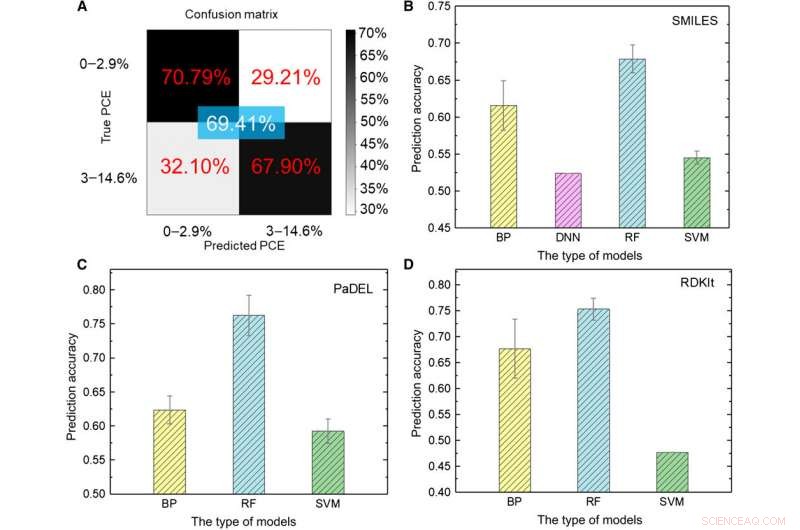
A equipe de pesquisa primeiro transformou os dados brutos em uma representação legível por máquina. Existe uma variedade de expressões para a mesma molécula, compreendendo informações químicas muito diferentes apresentadas em diferentes níveis abstratos. Usando um conjunto de modelos de ML, Sun et al. explorou diversas expressões de uma molécula, comparando sua precisão prevista para eficiência de conversão de energia (PCE) para obter uma precisão de modelo de aprendizado profundo de 69,41 por cento. O desempenho relativamente insatisfatório foi devido ao tamanho pequeno do banco de dados. Por exemplo, anteriormente, quando o mesmo grupo usava um número maior de moléculas de até 50, 000, a precisão do modelo de aprendizado profundo excedeu 90 por cento. Para treinar totalmente um modelo de aprendizado profundo, os pesquisadores devem implementar um banco de dados maior contendo milhões de amostras.
Resultados do teste de modelos de ML. (A) Teste do modelo de aprendizado profundo usando imagens como entrada. (B a D) Resultados do teste de diferentes modelos de ML usando (B) SMILES, (C) PaDEL, e (D) descritores RDKIt como entrada. Crédito:Science Advances, doi:10.1126 / sciadv.aay4275
Sun et al. só tinha centenas de moléculas em cada categoria no momento, tornando difícil para o modelo extrair informações suficientes para maior precisão. Embora seja possível ajustar um modelo pré-treinado para reduzir a quantidade de dados necessária, milhares de amostras ainda são necessárias para realizar um número suficiente de recursos. Isso levou à opção de aumentar o tamanho do banco de dados ao usar imagens para expressar moléculas.
Os cientistas usaram cinco tipos de algoritmos de ML supervisionados no estudo, incluindo (1) rede neural de propagação reversa (BP) (BPNN), (2) rede neural profunda (DNN), (3) aprendizado profundo, (4) máquina de vetores de suporte (SVM) e (5) floresta aleatória (RF). Esses eram algoritmos avançados, onde BPNN, O DNN e o aprendizado profundo foram baseados na rede neutra artificial (ANN). O código SMILES (sistema de entrada de linha de entrada molecular simplificado) forneceu outra expressão original de uma molécula, qual Sun et al. usado como entrada para quatro modelos. Com base nos resultados, a maior precisão foi de aproximadamente 67,84 por cento para o modelo de RF. Como antes, ao contrário do aprendizado profundo, os quatro métodos clássicos não podiam extrair recursos ocultos. Como um todo, SMILES teve desempenho pior do que imagens como descritores de moléculas para prever a classe PCE (eficiência de conversão de energia) nos dados.
Os pesquisadores então usaram descritores moleculares que podem descrever as propriedades de uma molécula usando uma série de números em vez da expressão direta de uma estrutura química. A equipe de pesquisa utilizou dois tipos de descritores PaDEL e RDKIt no estudo. Depois de análises extensas em todos os modelos de ML, um grande tamanho de dados implica em mais descritores irrelevantes para o PCE que afetam o desempenho da RNA. Comparativamente, um pequeno tamanho de dados implicava informações químicas ineficientes para treinar com eficácia os modelos de ML, ao usar descritores moleculares como entrada em abordagens de ML, a chave dependia de encontrar descritores apropriados que se relacionavam diretamente com o objeto de destino.
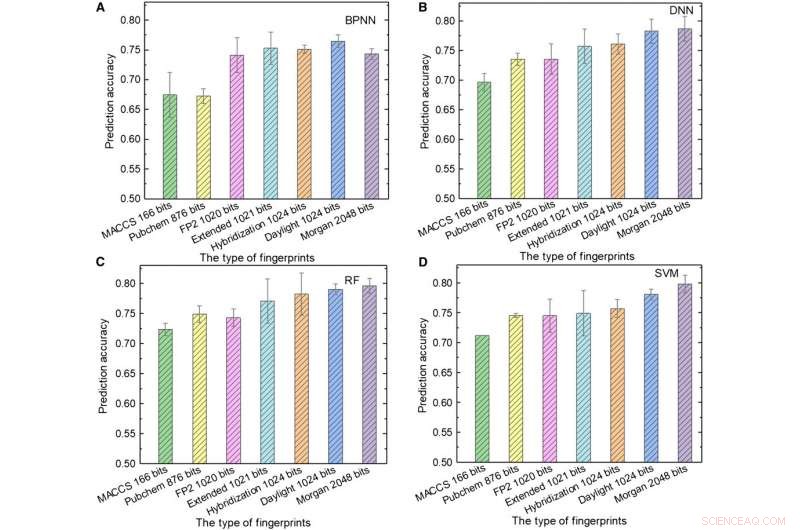
Desempenho de modelos de ML. (A a D) Os resultados do teste de (A) BPNN, (B) DNN, (C) RF, e (D) SVM usando diferentes tipos de impressões digitais como entrada. Crédito:Science Advances, doi:10.1126 / sciadv.aay4275.
A próxima equipe usou impressões digitais moleculares; normalmente projetado para representar moléculas como objetos matemáticos e originalmente criado para identificar isômeros. Durante a triagem de banco de dados em grande escala, o conceito é representado como uma matriz de bits contendo "1" s e "0" s para descrever a presença ou ausência de subestruturas ou padrões específicos dentro das moléculas. Sun et al. usou sete tipos de impressões digitais como entradas para treinar os modelos de ML e considerou a influência do comprimento da impressão digital no desempenho de previsão de diferentes modelos para obter diversas impressões digitais. Por exemplo, As impressões digitais do sistema de acesso molecular (MACCS) continham 166 bits e eram a entrada mais curta e os resultados eram insatisfatórios devido às suas informações limitadas.
Sun et al. mostrou a melhor combinação de linguagem de programação e algoritmo de ML obtida usando impressões digitais de hibridização de 1024 bits e RF, para atingir uma precisão de previsão de 81,76 por cento; onde as impressões digitais de hibridização representaram os estados de hibridização SP2 das moléculas. Quando o comprimento da impressão digital aumentou de 166 para 1024 bits, o desempenho de todos os modelos de ML melhorou, pois impressões digitais mais longas incluíam mais informações químicas.
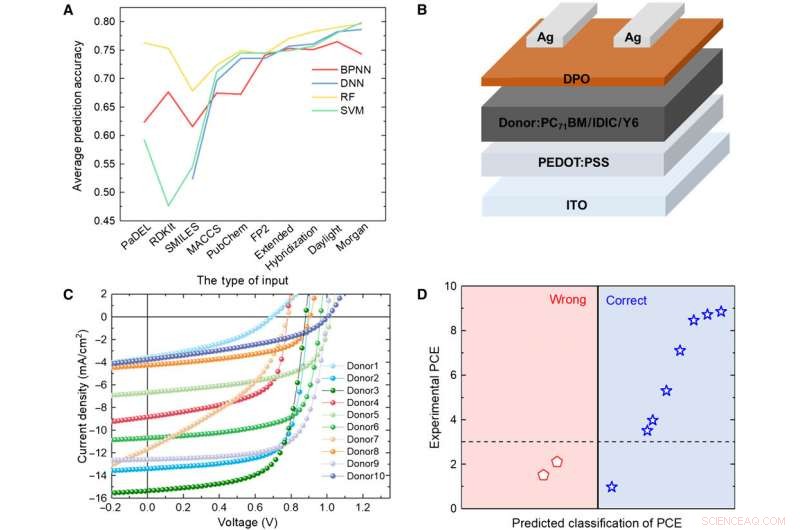
Verificação de modelos de ML com experimento. (A) Comparação dos resultados de quatro modelos diferentes. (B) Diagrama esquemático da arquitetura da célula usada neste estudo. (C) Curva J-V da célula solar com a camada ativa usando o material doador previsto. (D) Resultados de previsão versus dados experimentais para os materiais doadores previstos com o algoritmo de RF e impressões digitais de luz do dia. Crédito:Science Advances, doi:10.1126 / sciadv.aay4275.
Para testar a confiabilidade dos modelos de ML, Sun et al. sintetizou 10 novas moléculas doadoras de OPV. Em seguida, usou três impressões digitais representativas para expressar a estrutura química das novas moléculas e comparou os resultados previstos pelo modelo de RF e os valores experimentais de PCE. O sistema classificou oito das 10 moléculas. Os resultados indicaram o potencial dos materiais sintéticos para aplicações de OPV com otimização experimental adicional para dois dos novos materiais. Uma pequena alteração na estrutura pode causar uma grande diferença nos valores PCE. Encorajadoramente, os modelos de ML identificaram essas pequenas modificações para facilitar resultados de previsão favoráveis.
Desta maneira, Wenbo Sun e colegas usaram um banco de dados de literatura sobre materiais de doadores OPV e uma variedade de expressões de linguagem de programação (imagens, Strings ASCII, descritores e impressões digitais moleculares) para construir modelos de ML e prever a classe OPV PCE correspondente. A equipe demonstrou um esquema para projetar materiais doadores de OPV usando abordagens de ML e análise experimental. Eles pré-selecionaram um grande número de materiais de doadores usando o modelo ML para identificar os principais candidatos para a síntese e outros experimentos. O novo trabalho pode acelerar o design de novos materiais doadores para acelerar o desenvolvimento de OPVs de alto PCE. O uso de ML em conjunto com experimentos irá progredir na descoberta de materiais.
© 2019 Science X Network