Imagem sem lentes por meio de aprendizado de máquina avançado para soluções de detecção de imagem de próxima geração
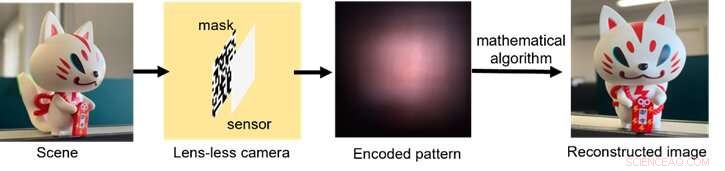
Um esquema de como funciona o processo de imagem sem lentes, desde a coleta de luz através da codificação do sinal até o pós-processamento com algoritmos de computação. Crédito:Xiuxi Pan da Tokyo Tech
Uma câmera geralmente requer um sistema de lentes para capturar uma imagem focada, e a câmera com lente tem sido a solução de imagem dominante por séculos. Uma câmera com lente requer um sistema de lente complexo para obter imagens de alta qualidade, brilhantes e sem aberrações. Nas últimas décadas, houve um aumento na demanda por câmeras menores, mais leves e mais baratas. Há uma clara necessidade de câmeras de última geração com alta funcionalidade, compactas o suficiente para serem instaladas em qualquer lugar. No entanto, a miniaturização da câmera com lente é restrita pelo sistema de lentes e pela distância de foco exigida pelas lentes refrativas.
Avanços recentes na tecnologia de computação podem simplificar o sistema de lentes substituindo algumas partes do sistema óptico pela computação. A lente inteira pode ser abandonada graças ao uso da computação de reconstrução de imagem, permitindo uma câmera sem lente, que é ultrafina, leve e de baixo custo. A câmera sem lente vem ganhando força recentemente. Mas até agora, a técnica de reconstrução de imagem não foi estabelecida, resultando em qualidade de imagem inadequada e tempo de computação tedioso para a câmera sem lente.
Recentemente, pesquisadores desenvolveram um novo método de reconstrução de imagem que melhora o tempo de computação e fornece imagens de alta qualidade. Descrevendo a motivação inicial por trás da pesquisa, um membro central da equipe de pesquisa, Prof. Masahiro Yamaguchi da Tokyo Tech, diz:"Sem as limitações de uma lente, a câmera sem lente poderia ser ultra-miniatura, o que poderia permitir novas aplicações que são além da nossa imaginação." Seu trabalho foi publicado em
Optics Letters .
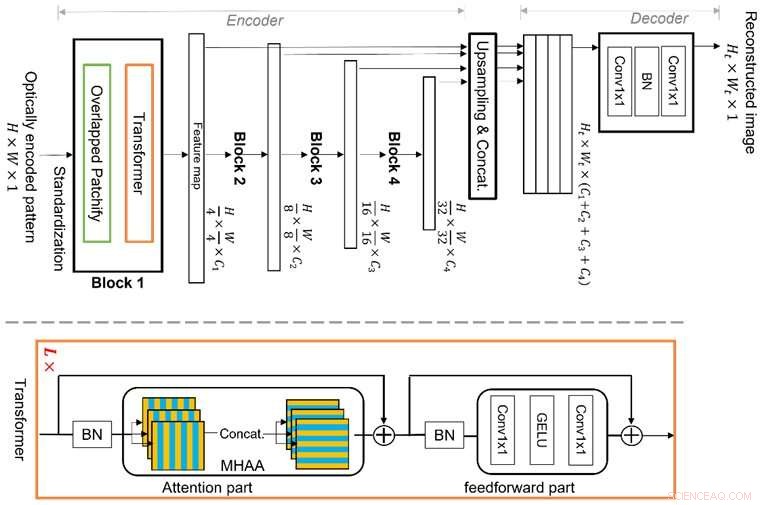
O Vision Transformer (ViT) é uma técnica de aprendizado de máquina de ponta, que é melhor no raciocínio de recursos globais devido à sua nova estrutura dos blocos transformadores de vários estágios com módulos "patchify" sobrepostos. Isso permite que ele aprenda com eficiência os recursos da imagem em uma representação hierárquica, tornando-o capaz de abordar a propriedade de multiplexação e evitar as limitações do aprendizado profundo convencional baseado em CNN, permitindo assim uma melhor reconstrução da imagem. Crédito:Xiuxi Pan da Tokyo Tech
O hardware óptico típico da câmera sem lente consiste simplesmente em uma máscara fina e um sensor de imagem. A imagem é então reconstruída usando um algoritmo matemático. A máscara e o sensor podem ser fabricados juntos em processos de fabricação de semicondutores estabelecidos para produção futura. A máscara codifica opticamente a luz incidente e projeta padrões no sensor. Embora os padrões fundidos sejam completamente não interpretáveis ao olho humano, eles podem ser decodificados com conhecimento explícito do sistema óptico.
No entanto, o processo de decodificação – baseado na tecnologia de reconstrução de imagem – continua desafiador. Os métodos tradicionais de decodificação baseados em modelo aproximam o processo físico da ótica sem lentes e reconstroem a imagem resolvendo um problema de otimização "convexo". Isso significa que o resultado da reconstrução é suscetível às aproximações imperfeitas do modelo físico. Além disso, a computação necessária para resolver o problema de otimização é demorada porque requer cálculo iterativo. O aprendizado profundo pode ajudar a evitar as limitações da decodificação baseada em modelo, pois pode aprender o modelo e decodificar a imagem por um processo direto não iterativo. No entanto, os métodos de aprendizado profundo existentes para imagens sem lentes, que utilizam uma rede neural convolucional (CNN), não podem produzir imagens de alta qualidade. Eles são ineficientes porque a CNN processa a imagem com base nas relações dos pixels "locais" vizinhos, enquanto a ótica sem lentes transforma as informações locais da cena em informações "globais" sobrepostas em todos os pixels do sensor de imagem, por meio de uma propriedade chamada "multiplexação". "

A câmera sem lente consiste em uma máscara e um sensor de imagem com uma distância de separação de 2,5 mm. A máscara é fabricada por deposição de cromo em uma placa de sílica sintética com um tamanho de abertura de 40×40 μm. Crédito:Xiuxi Pan da Tokyo Tech
A equipe de pesquisa da Tokyo Tech está estudando essa propriedade de multiplexação e agora propôs um novo algoritmo de aprendizado de máquina dedicado para reconstrução de imagens. O algoritmo proposto é baseado em uma técnica de aprendizado de máquina de ponta chamada Vision Transformer (ViT), que é melhor no raciocínio de recursos globais. A novidade do algoritmo está na estrutura dos blocos do transformador multiestágio com módulos "patchify" sobrepostos. Isso permite que ele aprenda com eficiência os recursos da imagem em uma representação hierárquica. Consequentemente, o método proposto pode abordar bem a propriedade de multiplexação e evitar as limitações do aprendizado profundo convencional baseado em CNN, permitindo uma melhor reconstrução da imagem.
Enquanto os métodos convencionais baseados em modelos requerem longos tempos de computação para processamento iterativo, o método proposto é mais rápido porque a reconstrução direta é possível com um algoritmo de processamento livre de iterativo projetado por aprendizado de máquina. A influência dos erros de aproximação do modelo também é drasticamente reduzida porque o sistema de aprendizado de máquina aprende o modelo físico. Além disso, o método baseado em ViT proposto usa recursos globais na imagem e é adequado para processar padrões fundidos em uma ampla área no sensor de imagem, enquanto os métodos convencionais de decodificação baseados em aprendizado de máquina aprendem principalmente relações locais por CNN.
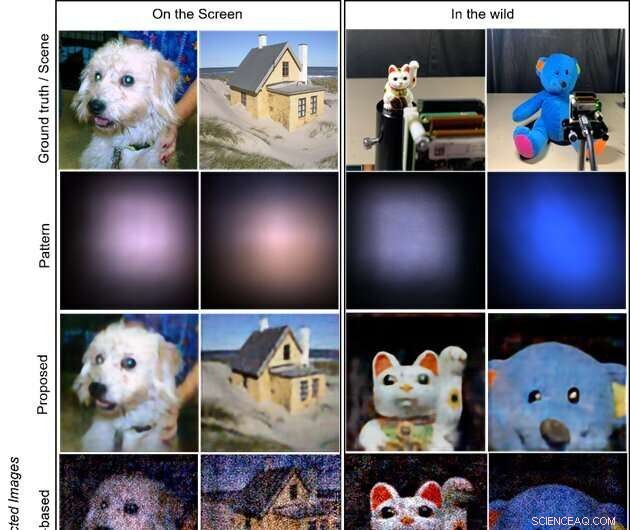
Os alvos são as imagens exibidas em uma tela de LCD (duas colunas à esquerda) e os objetos em estado selvagem (duas colunas à direita; boneca de gato acenando e urso de pelúcia), respectivamente. A primeira linha mostra as imagens reais exibidas na tela e as cenas de tiro para objetos selvagens. A segunda linha mostra os padrões capturados no sensor. As últimas três linhas ilustram as imagens reconstruídas pelos métodos proposto, baseado em modelo e baseado em CNN, respectivamente. O método proposto produz imagens de alta qualidade e visualmente atraentes. Crédito:Xiuxi Pan da Tokyo Tech
Em resumo, o método proposto resolve as limitações de métodos convencionais, como processamento baseado em reconstrução iterativa de imagens e aprendizado de máquina baseado em CNN com a arquitetura ViT, permitindo a aquisição de imagens de alta qualidade em um curto período de tempo computacional. A equipe de pesquisa realizou experimentos ópticos - conforme relatado em sua última publicação - que sugerem que a câmera sem lente com o método de reconstrução proposto pode produzir imagens de alta qualidade e visualmente atraentes, enquanto a velocidade de computação pós-processamento é alta o suficiente para real- captura de tempo.
"Percebemos que a miniaturização não deve ser a única vantagem da câmera sem lente. A câmera sem lente pode ser aplicada a imagens de luz invisível, nas quais o uso de uma lente é impraticável ou mesmo impossível. Além disso, a dimensionalidade subjacente da informação óptica capturada pela câmera sem lente é maior que dois, o que possibilita imagens 3D de uma só foto e refocalização pós-captura. Estamos explorando mais recursos da câmera sem lente. O objetivo final de uma câmera sem lente é ser em miniatura, mas poderosa. Estamos entusiasmados por liderar nesta nova direção para soluções de imagem e detecção de próxima geração", disse o principal autor do estudo, Sr. Xiuxi Pan, da Tokyo Tech, enquanto falava sobre seu trabalho futuro.
+ Explorar mais Expandindo a microespectroscopia infravermelha com o método de reconstrução computacional Lucy-Richardson-Rosen